Make-a-video: L’IA Cinéaste !
Le nouveau modèle make-a-video de Meta AI est sorti et en une seule phrase : il génère des vidéos à partir de texte. Il est non seulement capable de générer des vidéos, mais c'est aussi la nouvelle méthode de pointe, produisant des vidéos de meilleure qualité et plus cohérentes que jamais ! Et oui, tout ça automatiquement à partir d’une simple entrée de texte!
Vous pouvez voir ce modèle comme un modèle de diffusion stable pour les vidéos. Certainement la prochaine étape après avoir pu générer des images. Ce sont toutes des informations que vous avez déjà dû voir sur un site d'actualités ou simplement en lisant le titre de l'article, mais ce que vous ne savez pas encore, c'est de quoi il s'agit exactement et comment cela fonctionne.
Make-A-Video est la publication la plus récente de Meta AI, et elle vous permet de générer une courte vidéo à partir d'une entrée textuelle, comme ceci…

Un chien portant une tenue de super-héros avec une cape rouge volant dans le ciel. Vidéo générée avec Make-A-Video par Singer et al. (Meta AI), 2022.
Ainsi, vous ajoutez de la complexité à la tâche de génération d'images non seulement en devant générer plusieurs images du même sujet et de la même scène, mais en plus elles doivent être cohérentes dans le temps. Vous ne pouvez pas simplement générer 60 images à l'aide de DALLE et générer une vidéo. Cela n’aurait rien de réaliste.
Vous avez besoin d'un modèle qui comprend mieux le monde et exploite ce niveau de compréhension pour générer une série cohérente d'images qui se fondent bien ensemble. Vous voulez essentiellement simuler un monde, puis simuler des enregistrements de celui-ci. Mais comment pouvez-vous faire cela?
En règle générale, vous auriez besoin de tonnes de paires texte-vidéo pour entraîner votre modèle à générer de telles vidéos à partir d'entrées textuelles, mais pas dans ce cas. Étant donné que ce type de données est vraiment difficile à obtenir et que les coûts de formation sont très élevés, ils abordent ce problème différemment.
Une autre façon consiste à prendre le meilleur modèle texte-image et à l'adapter aux vidéos, et c'est ce que Meta AI a fait dans un document de recherche qu'ils viennent de publier. Dans leur cas, le modèle texte-image est un autre modèle de Meta appelé Make-A-Scene, que j'ai abordé dans un article précédent si vous souhaitez en savoir plus. Mais comment adapter un tel modèle pour tenir compte du temps ? Vous ajoutez un module spatio-temporel pour que votre modèle puisse traiter des vidéos.
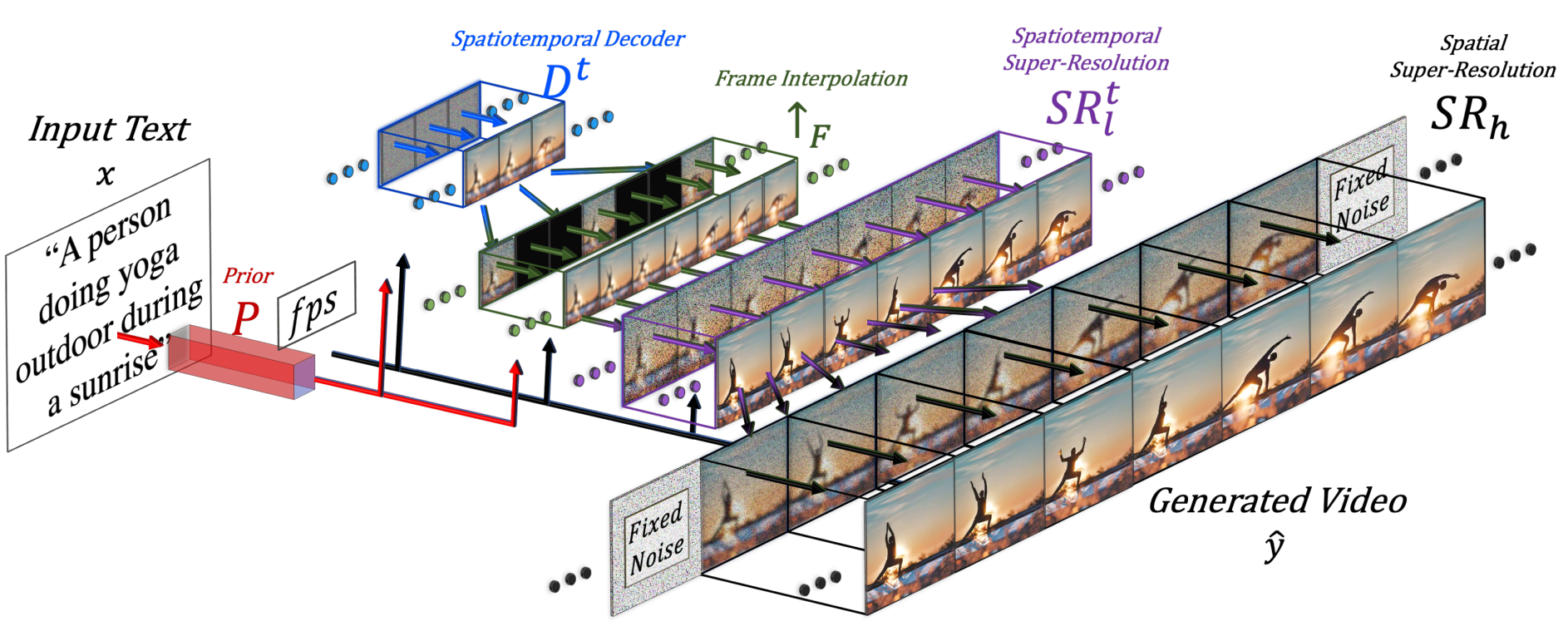
Présentation de l'approche. Image de Singer et al. (Meta AI), 2022.
Cela signifie que le modèle générera non seulement une image, mais, dans ce cas, 16 d'entre elles en basse résolution pour créer une courte vidéo cohérente de la même manière que le modèle texte-image, mais en ajoutant une convolution 1D avec les convolutions régulières 2D. Ce simple ajout leur permet de conserver les mêmes convolutions 2D pré-formées et d'ajouter une dimension temporelle qu'ils formeront à partir de zéro, en réutilisant la plupart du code et des paramètres du modèle d'image à partir duquel ils sont partis.
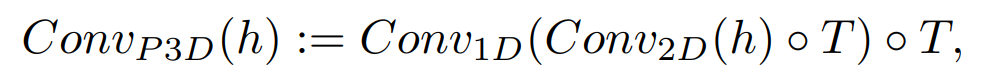
Ajout du module de convolution unidimensionnel après le module de convolution bidimensionnel régulier utilisé dans l'approche texte-image.
Nous voulons également guider nos générations avec la saisie de texte, qui sera très similaire aux modèles d'image utilisant les intégrations CLIP. Un processus que je détaille dans ma vidéo de diffusion stable si vous n'êtes pas familier avec l'approche. Mais ils ajouteront également la dimension spatiale lors de la fusion des caractéristiques du texte avec les caractéristiques de l'image, en faisant la même chose : en gardant le module d'attention que j'ai décrit dans ma vidéo sur make-a-scene et en ajoutant un module d'attention unidimensionnel pour des considérations temporelles — copier-coller le modèle du générateur d'images et dupliquer les modules de génération pour une dimension supplémentaire afin d'avoir toutes nos 16 images initiales.
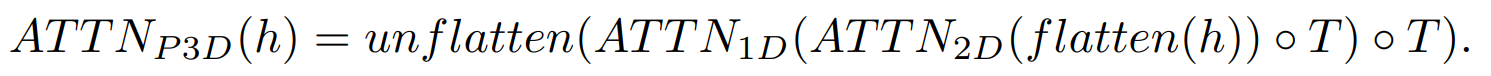
Ajout du module d'attention à une dimension après le module d'attention à deux dimensions habituel utilisé dans l'approche texte-image.
Mais 16 images ne vous mèneront pas loin pour une vidéo. Nous devons créer une vidéo haute définition à partir de ces 16 images principales. Le modèle le fera en ayant accès aux images précédentes et futures et en interpolant de manière itérative à partir d'eux en termes de dimensions temporelles et spatiales en même temps. Donc, fondamentalement, générer de nouvelles images plus grandes entre ces 16 images initiales basées sur les images avant et après elles, ce qui facilitera la cohérence du mouvement et la fluidité globale de la vidéo. Cela se fait à l'aide d'un réseau d'interpolation d’images dans le temps que j'ai également décrit dans d'autres vidéos, mais qui prendra essentiellement les images que nous avons et comblera les lacunes générant des informations intermédiaires. Il fera la même chose pour la composante spatiale, en agrandissant l'image et en comblant les lacunes en pixels pour la rendre plus haute définition.
Donc, pour résumer, ils peaufinent un modèle texte-image pour la génération vidéo. Cela signifie qu'ils prennent un modèle puissant déjà formé et l'adaptent et le forment un peu plus pour s'habituer aux vidéos. Cette technique va simplement adapter le modèle à ce nouveau type de données, grâce aux ajouts de modules spatio-temporels dont nous avons parlé, au lieu de devoir tout ré-entraîner, ce qui est incroyablement coûteux. Cette nouvelle formation sera effectuée avec des vidéos non étiquetées uniquement pour apprendre au modèle à comprendre les vidéos et la cohérence des images dans une vidéo, ce qui simplifie considérablement le processus de création de l'ensemble de données. Ensuite, nous utilisons à nouveau un modèle optimisé pour l'image pour améliorer la résolution spatiale et notre dernier composant d'interpolation d'image pour ajouter plus d'images pour rendre la vidéo fluide.
Et voilà !

Poisson clown nageant à travers la barrière de corail. Vidéo générée avec Make-A-Video par Singer et al. (Meta AI), 2022.
Poisson clown nageant à travers la barrière de corail. Vidéo générée avec Make-A-Video par Singer et al. (Meta AI), 2022.
Bien sûr, les résultats ne sont pas encore parfaits, tout comme les modèles texte-image, mais nous savons à quelle vitesse les progrès vont.
Il s'agissait d'un aperçu de la façon dont Meta AI a abordé avec succès la tâche de conversion de texte en vidéo dans leur excellente publication. Tous les liens sont dans la description si vous souhaitez en savoir plus sur leur approche. Une implémentation de PyTorch est déjà en cours de développement par la communauté, alors restez à l’affut si vous souhaitez l'implémenter vous-même (lien ci-dessous) !
Merci d'avoir regardé toute la vidéo et je vous verrai la prochaine fois avec une autre publication de recherche incroyable !
Références
► Billet de blogue de Meta: https://ai.facebook.com/blog/generative-ai-text-to-video/
►Singer et al. (Meta AI), 2022, “MAKE-A-VIDEO: TEXT-TO-VIDEO GENERATION WITHOUT TEXT-VIDEO DATA”, https://makeavideo.studio/Make-A-Video.pdf
►Make-a-video (page officielle): https://makeavideo.studio/?fbclid=IwAR0tuL9Uc6kjZaMoJHCngAMUNp9bZbyhLmdOUveJ9leyyfL9awRy4seQGW4
► Implémentation PyTorch: https://github.com/lucidrains/make-a-video-pytorch