Modèles 3D à partir de texte ! DreamFusion expliqué
Nous avons vu des modèles capables de prendre une phrase et de générer des images.
Ensuite, d'autres approches pour manipuler les images générées en apprenant des concepts spécifiques comme un objet ou un style particulier.
La semaine dernière, Meta a publié le modèle Make-A-Video que j'ai couvert, qui vous permet de générer une courte vidéo également à partir d'une phrase. Les résultats ne sont pas encore parfaits, mais les progrès que nous avons réalisés dans le domaine depuis l'année dernière sont tout simplement incroyables.
Cette semaine, nous faisons un autre pas en avant.
Voici DreamFusion, un nouveau modèle de Google Research capable de comprendre suffisamment une phrase pour en générer un modèle 3D.
Vous pouvez voir cela comme un DALLE ou Stable Diffusion, mais en 3D.
À quel point cela est cool?! Nous ne pouvons pas vraiment demander mieux...
Mais ce qui est encore plus fascinant, c'est comment ça fonctionne!

[…] un tigre déguisé en médecin. Modèle 3D généré avec DreamFusion.
Si vous avez suivi mon travail, DreamFusion est assez simple.
Il utilise essentiellement deux modèles que j'ai déjà couverts : les NeRF et l'un des modèles texte-image. Dans leur cas, c'est le modèle Imagen, mais n'importe lequel ferait l'affaire, comme Stable Diffusion.
Comme vous le savez, si vous avez été un bon élève et avez regardé les vidéos précédentes, les NeRF sont une sorte de modèle utilisé pour générer des scènes 3D en générant des “champs de rayonnement neuronal” à partir d'une ou plusieurs images d'un objet.

Approche NeRF. Image tirée de l'article NeRF.
Mais alors, comment générer un rendu 3D à partir de texte si le modèle NeRF ne fonctionne qu'avec des images ?
Eh bien, nous utilisons Imagen, l'autre IA, pour générer une variation d'image à partir du texte souhaité !
Et pourquoi faisons-nous cela au lieu de générer directement des modèles 3D à partir de texte ? Parce que cela nécessiterait d'énormes ensembles de données de données 3D ainsi que leurs légendes associées pour former notre modèle, ce qui serait très difficile à avoir. Au lieu de cela, nous utilisons un modèle texte-image pré-entraîné avec des données beaucoup moins complexes à collecter, et nous l'adaptons à la 3D ! Il ne nécessite donc aucune donnée 3D pour s'entraîner, seulement une IA préexistante pour générer des images ! C'est vraiment cool de voir comment nous pouvons réutiliser des technologies puissantes pour de nouvelles tâches comme celle-ci en interprétant le problème différemment.
Donc si on part du début : on a un modèle NeRF.
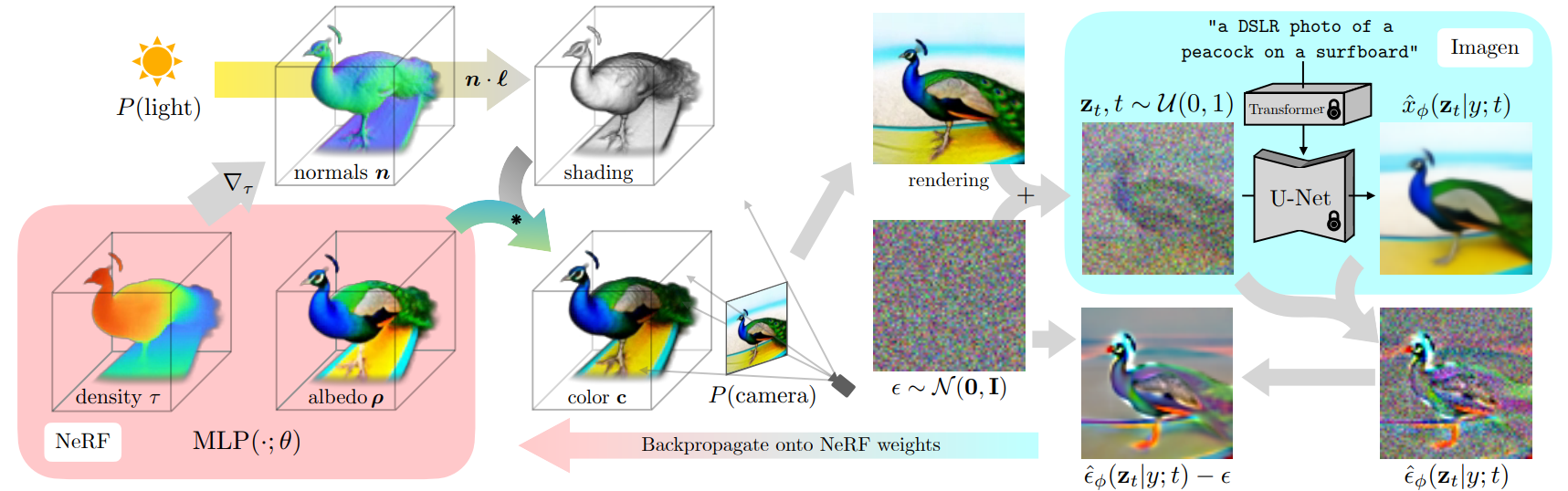
Présentation de l'approche. Image tirée du papier DreamFusion.
Comme je l'ai expliqué dans les vidéos précédentes, ce type de modèle prend des images pour prédire les pixels dans chaque nouvelle vue, créant un modèle 3D à partir de paires d'images du même objet avec différents points de vue. Dans notre cas, nous ne partons pas directement des images. Nous commençons par le texte et échantillonnons une orientation de vue aléatoire que nous voulons générer. Fondamentalement, nous essayons de créer un modèle 3D en générant des images de tous les angles possibles qu'une caméra pourrait couvrir, en regardant autour de l'objet et en devinant les couleurs, les densités, les réflexions lumineuses des pixels, etc. Tout ce qu'il faut pour le rendre réaliste.
Ainsi, nous commençons par une légende et y ajoutons un petit ajustement en fonction du point de vue aléatoire de la caméra que nous voulons générer. Par exemple, nous pouvons vouloir générer une vue de face, nous ajouterons donc "vue de face" à la légende.
De l'autre côté, nous utilisons les mêmes paramètres d'angle et de caméra pour notre modèle NeRF initial, non entraîné, pour prédire le premier rendu.
Ensuite, nous générons une version d'image guidée par notre légende et notre rendu initial avec du bruit supplémentaire à l'aide d'Imagen (en haut à droite de l’image ci-dessus), notre modèle de texte-à-image pré-entraîné, que j'ai expliqué plus en détail dans ma vidéo Imagen si vous êtes curieux de voir comment cela fonctionne.
Ainsi, notre modèle Imagen sera guidé par la saisie de texte ainsi que le rendu actuel de l'objet avec du bruit ajouté. Ici, nous ajoutons du bruit, car c'est ce que le modèle Imagen peut prendre en entrée. L’”image” d’entrée doit faire partie de la distribution de bruit qu'il comprend. Ensuite, nous utilisons le modèle pour générer une image de meilleure qualité. Ajoutez l'image utilisée pour la générer et supprimez le bruit que nous avons ajouté manuellement pour utiliser ce résultat afin de guider et d'améliorer notre modèle NeRF pour l'étape suivante.
Nous faisons tout cela pour mieux comprendre où dans l'image le modèle NeRF devrait concentrer son attention pour produire de meilleurs résultats à l'étape suivante.
Et on répète tout ça jusqu'à ce que le modèle 3D soit suffisamment satisfaisant !
Vous pouvez ensuite exporter ce modèle en mesh et l'utiliser dans une scène de votre choix !

Et avant que certains d'entre vous ne demandent, non, vous n'avez pas besoin de réentraîner le modèle de générateur d'images — comme ils le disent si bien dans l'article : il (Imagen) agit simplement comme un critique figé qui prédit les modifications de l'espace image.
Et voilà !
C'est ainsi que DreamFusion génère des rendus 3D à partir d'entrées de texte. Si vous souhaitez avoir une compréhension plus approfondie de l'approche, jetez un œil à mes vidéos couvrant NeRFs et Imagen. Je vous invite également à lire leur article pour plus de détails sur cette méthode spécifique.
Merci d'avoir lu tout l'article. Je vous invite également à regarder la vidéo pour voir plus d'exemples ! Je vous verrai la semaine prochaine avec un autre article incroyable!
References
►Poole, B., Jain, A., Barron, J.T. and Mildenhall, B., 2022. DreamFusion: Text-to-3D using 2D Diffusion. arXiv preprint arXiv:2209.14988.
►Site du projet: https://dreamfusion3d.github.io/
►Ma Newsletter (anglais): https://www.louisbouchard.ai/newsletter/