Comment l'IA comprend les vidéos
Nous avons vu l'IA générer du texte, puis générer des images et plus récemment même générer de courtes vidéos, même si elles ont encore besoin de travail, les résultats sont incroyables quand on pense que personne n'est réellement impliqué dans le processus de création de ces pièces et que ces réseaux ne doivent être formés qu'une seule fois pour ensuite être utilisés par des milliers de personnes comme pour “Stable Diffusion”. Pourtant, ces modèles comprennent-ils vraiment ce qu'ils font ? Savent-ils ce que représente réellement l'image ou la vidéo qu'ils viennent de produire ? Que comprend un tel modèle lorsqu'il voit une photo ou, plus complexe encore, une vidéo ?

Résultat de l’article.
Concentrons-nous sur le plus difficile des deux et plongeons dans la façon dont une IA comprend les vidéos grâce à une tâche appelée “reconnaissance de vidéo générale”, où l'objectif est qu'un modèle prenne des vidéos en entrée et utilise du texte pour décrire ce qui se passe dans la courte vidéo.
La reconnaissance de vidéo générale est l'une des tâches les plus difficiles reliée à la compréhension de vidéos. Pourtant, c'est peut-être la meilleure mesure de la capacité d'un modèle à comprendre ce qui se passe. C'est aussi la base de nombreuses applications s'appuyant sur une bonne compréhension des vidéos comme l'analyse sportive ou les voitures autonomes. Mais qu'est-ce qui rend cette tâche si complexe ? Eh bien, il y a deux choses :
Nous devons comprendre ce qui est montré dans la vidéo, c'est-à-dire chaque image ou chaque image d'une vidéo particulière.
Nous devons être capables de dire ce que nous comprenons d'une manière que les humains comprennent, c'est-à-dire avec des mots.
Heureusement pour nous, le deuxième défi a été relevé à de nombreuses reprises par la communauté linguistique, et nous pouvons reprendre leur travaux. Plus précisément, nous pouvons prendre ce que les gens du domaine langage-image ont fait avec des modèles comme CLIP ou même “Stable Diffusion“, où vous avez un encodeur de texte et un encodeur d'image qui apprennent à encoder les deux types d'entrées dans le même type de représentation. De cette façon, vous pouvez comparer une scène à une invite de texte similaire en entraînant l'architecture avec des millions d'exemples de légendes d'images. Avoir à la fois du texte et des images encodés dans un espace similaire est puissant, car cela prend beaucoup moins d'espace pour effectuer des calculs tout en nous permettant de comparer facilement le texte aux images. Cela signifie que le modèle ne comprend toujours pas une image ou même une simple phrase, mais il peut comprendre si les deux sont similaires ou non. Nous sommes encore loin de l'intelligence, mais c'est très utile et assez bon pour la plupart des cas.
Vient maintenant le plus grand défi : les vidéos. Et pour cela, nous utiliserons l'approche de Bolin Ni et ses collègues dans leur récent article "Expanding Language-Image Pretrained Models for General Video Recognition".
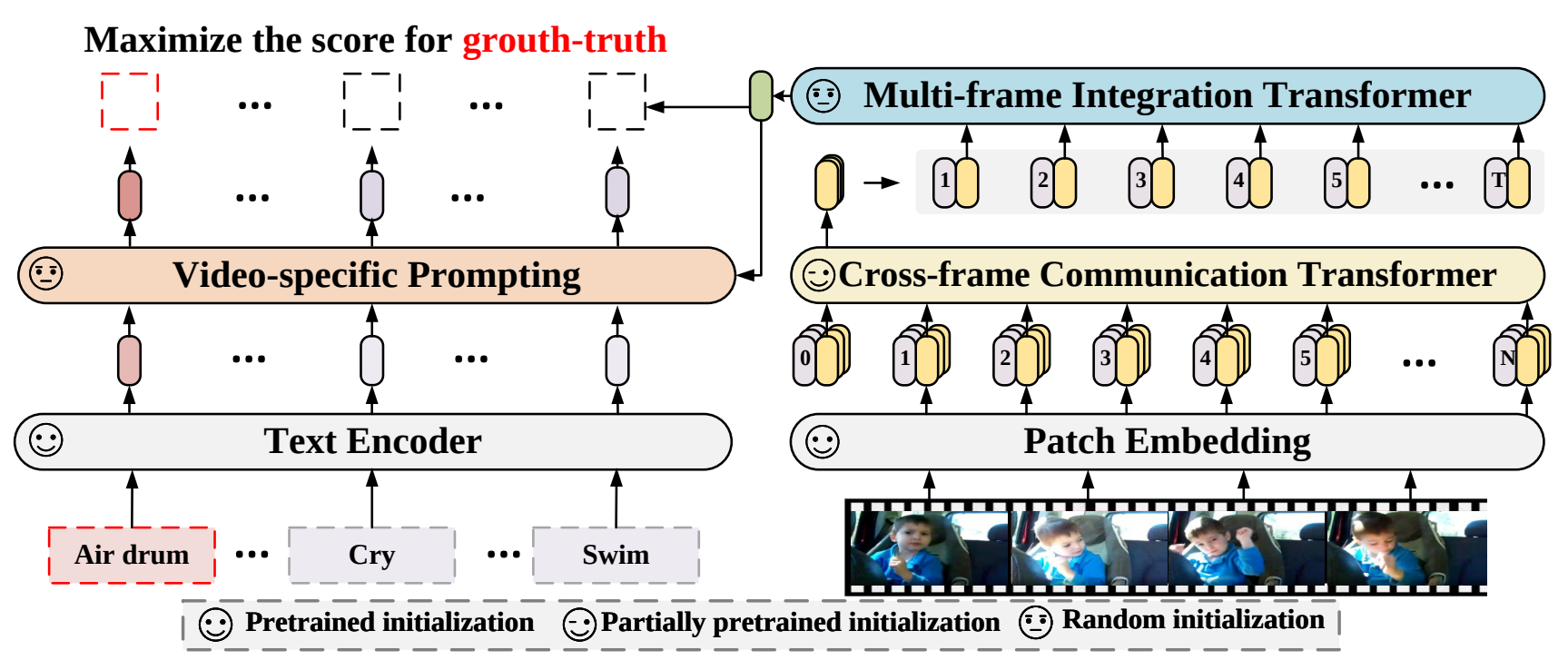
Présentation du modèle. Image tirée de l’article.
Les vidéos sont beaucoup plus complexes que les images en raison des informations temporelles, c'est-à-dire des multiples images et du fait que chaque image est liée à la suivante et à la précédente avec des mouvements et actions cohérents. Le modèle doit voir ce qui s'est passé avant, pendant et après chaque image pour avoir une bonne compréhension de la scène.
C'est comme sur YouTube. Vous ne pouvez pas vraiment sauter 5 secondes en avant dans de courtes vidéos, car vous manquerez des informations précieuses.
Dans ce cas, ils prennent chaque image et les envoient dans le même encodeur d'image dont nous venons de parler en utilisant une architecture basée sur un transformeur de vision pour les traiter dans un espace condensé en utilisant l'attention.
Si vous n'êtes pas familier avec les transformateurs de vision, ou le mécanisme de l'attention, je vous invite à regarder la vidéo que j'ai faite pour les introduires.
Une fois que vous avez votre représentation pour chaque image, vous pouvez utiliser un processus similaire basé sur l'attention pour que chaque image communique ensemble et permettre à votre modèle d'échanger des informations entre les images et de créer une représentation finale pour la vidéo. Cet échange d'informations entre les images en utilisant l'attention agira comme une sorte de mémoire pour que votre modèle comprenne la vidéo dans son ensemble plutôt que quelques images aléatoires regroupées.
Enfin, nous utilisons un autre module d'attention pour fusionner les encodages de texte décrivant les images (captions), que nous avions, avec notre représentation vidéo condensée fraichement produite.

Résultat de l’article.
Et voilà !
C'est une façon pour une IA de comprendre une vidéo. Bien sûr, ce n'était qu'un aperçu de ce super article de Microsoft Research servant d'introduction à la reconnaissance vidéo et je vous invite à lire l'article pour mieux comprendre leur approche.
Merci d'avoir lu tout l'article et je vous verrai la semaine prochaine avec un autre article incroyable !
Louis