Cette IA Crée des Oeuvres d'art à partir de texte et croquis !

Image tirée du blog de Meta.
Voici Make-A-Scene. Ce n'est pas "juste un autre Dalle". Le but de ce nouveau modèle n'est pas de permettre aux utilisateurs de générer des images aléatoires à l’aide d'une invite de texte comme le fait dalle — ce qui est vraiment cool — mais limite le contrôle que l'utilisateur a sur les générations.
Au lieu de cela, Meta voulait faire avancer l'expression créative dans ces générations, fusionnant cette tendance de modèles d’IA “texte à image” avec les modèles précédents de “croquis à image,” menant à "Make-A-Scene": un mélange fantastique entre la génération d'images conditionnées par croquis et texte. Cela signifie qu'en utilisant cette nouvelle approche, vous pouvez rapidement esquisser un chat et écrire le type d'image que vous souhaitez, et le processus de génération d'image suivra à la fois l'esquisse et les conseils de votre texte. Cela nous rapproche encore plus de la possibilité de générer l'illustration parfaite que nous voulons en quelques secondes.

Image tirée du blog de Meta.
Vous pouvez voir cette méthode d'IA générative multimodale comme un modèle Dalle avec un peu plus de contrôle sur les générations puisqu'elle peut également prendre une esquisse rapide en entrée. C'est pourquoi nous l'appelons multimodal : puisque le modèle peut prendre plusieurs “modalités” en entrée, comme du texte et une image, une esquisse dans ce cas, par rapport à Dalle, qui ne prend que du texte pour générer une image.
Les modèles multimodaux sont très prometteur , puisque nous avons plus de contrôle sur les résultats, nous rapprochant d'un objectif final très intéressant: générer l'image parfaite que nous avons en tête sans aucune compétence artistique ou logicielle.
Bien sûr, Make-A-Scene est encore à l'état de recherche. Cela ne signifie pas que ce que nous voyons est irréalisable. Ça signifie simplement qu'il faudra un peu plus de temps pour arriver au public.
Les progrès en IA sont extrêmement rapides, et je ne serais pas surpris de le voir vivre très prochainement, ou un modèle similaire d'autres personnes, avec lequel nous pourrons “jouer” autant qu’on le veut. Je pense que de tels modèles basés sur des croquis et du texte sont encore plus intéressants, en particulier pour l'industrie, c'est pourquoi j'ai voulu le couvrir sur mon blogue, même si les résultats sont un peu en retard par rapport à ceux de Dalle 2 que nous voyons en ligne. Et pas seulement pour l'industrie, mais aussi pour les artistes. Certains ont déjà utilisé la fonction d'esquisse pour générer des résultats encore plus inattendus que ce que Dalle pouvait faire, comme je le montre dans ma vidéo (en anglais).
Nous pouvons demander a umodèle de générer quelque chose et dessiner une forme qui ne représente pas cette chose spécifique, comme dessiner une méduse en forme de fleur (voir la vidéo), ce qui n'est peut-être pas impossible à avoir avec dalle, mais beaucoup plus compliqué sans un guidage d'esquisse, car le modèle ne fera que reproduire ce dont il apprend, répliquant donc des images et illustrations du monde réel.

Image tirée du papier.
La question principale est donc de savoir comment peuvent-ils guider les générations avec à la fois une entrée de texte, comme Dalle, et un croquis et faire en sorte que le modèle suive les deux directives ? Eh bien, c'est très, très similaire au fonctionnement de Dalle, donc je n'entrerai pas trop dans les détails des modèles génératifs, car j'ai couvert au moins cinq approches différentes au cours des deux derniers mois, que vous devriez certainement regarder si vous ne les avez pas encore vue, car ces modèles comme Dalle 2 ou Imagen sont assez fantastiques.
En règle générale, ces modèles nécessitent des millions d'exemples à fournir pendant l’entraînement pour apprendre à générer des images à partir de texte avec des données sous forme d'images et leurs légendes extraites d'Internet.
Ici, pendant la formation, au lieu de nous fier uniquement à la légende et générer la première version de notre image et la comparer à l'image réelle, et répéter ce processus de nombreuses fois avec toutes nos images, nous lui donnerons également un croquis. Ce qui est cool, c'est que les croquis sont assez faciles à produire pour l’entraînement. Il suffit de prendre un réseau pré-entraîné que vous pouvez téléchargez en ligne et effectuer une segmentation d'instance.

Pour ceux qui veulent les détails, ils utilisent un modèle VGG gratuit pré-entraîné sur Imagenet, donc un réseau assez petit par rapport à ceux d'aujourd'hui, super précis et rapide, produisant des résultats comme celui-ci (voir l’image ci-dessus)…
Appelé une carte de segmentation. Ils traitent simplement toutes leurs images une fois et obtiennent ces cartes pour former le modèle.
Ensuite, ils utilise cette carte ainsi que la légende pour orienter le modèle afin de générer l'image initiale. Au moment de l'inférence, ou lorsque l'un de nous l'utilisera, notre croquis remplacera ces cartes de segmentation.
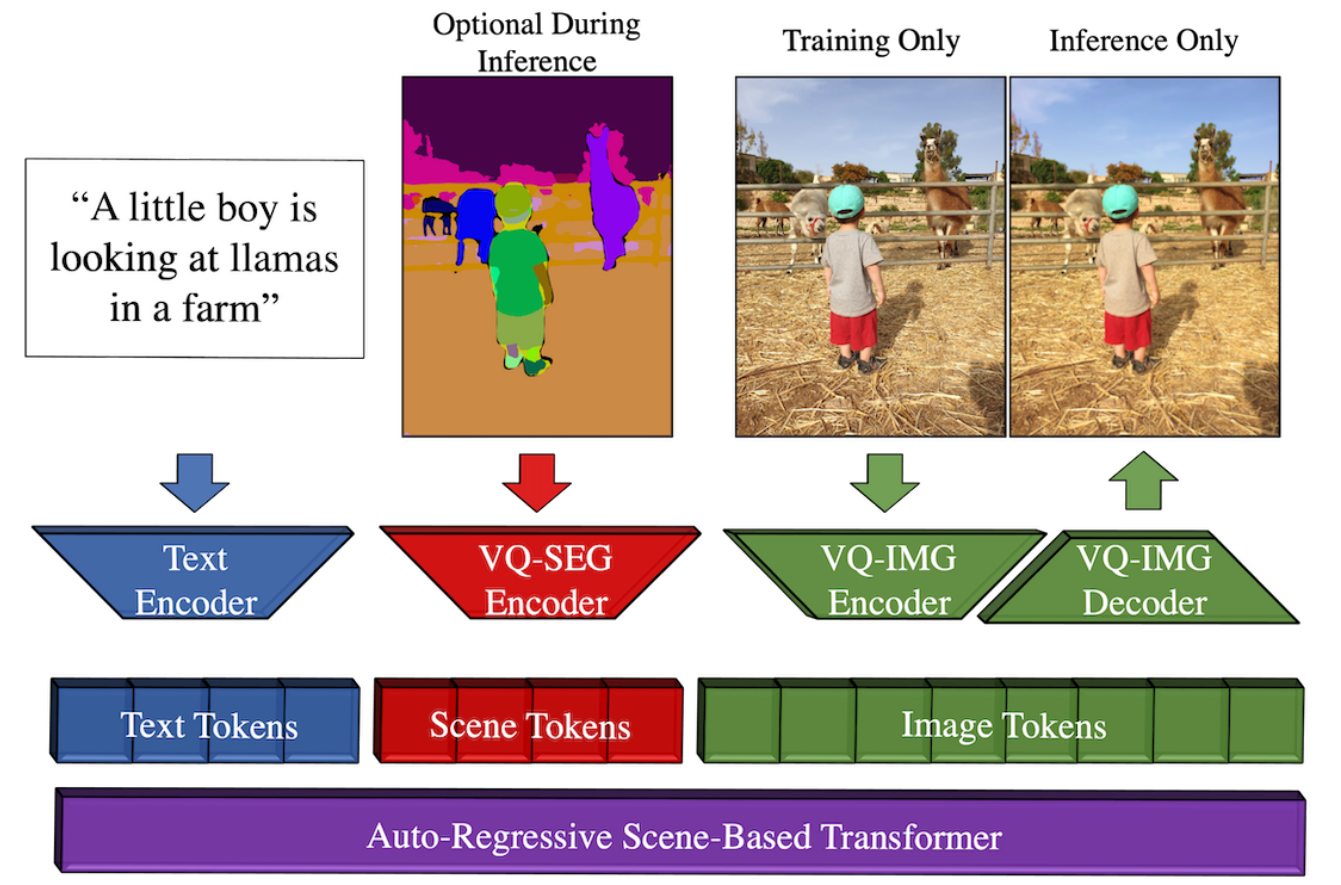
Présentation de l'approche Make-A-Scene. Image tirée du papier.
Comme je l'ai dit, ils ont utilisé un modèle appelé VGG pour créer de faux croquis pour la formation. Ils utilisent une architecture Transformer pour le processus de génération d'images, qui est différente de Dalle-2, et je vous invite à regarder la vidéo que j'ai faite présentant les transformeurs pour les applications de vision si vous souhaitez plus de détails sur la façon dont il peut traiter et générer des images.
Ce Transformer guidé par croquis est la principale différence avec Make-A-Scene, en plus de ne pas utiliser un classement image-texte comme CLIP pour mesurer les paires texte et image, que vous pouvez également découvrir dans mon article sur Dalle. Au lieu de cela, les encodages de textes et des cartes de segmentation sont envoyés au modèle Transformer. Le modèle génère les encodages d'images pertinents, qui sont ensuite encodés et décodés par les réseaux correspondants, principalement pour produire l'image. L'encodeur est utilisé pendant l'entraînement pour calculer la différence entre l'image produite et l'image initiale, mais seul le décodeur est nécessaire pour prendre cette sortie du transformeur et la transformer en image.
Et voilà !
C'est ainsi que le nouveau modèle de Meta est capable de prendre un croquis et des entrées de texte et de générer une image haute définition à partir de celui-ci, permettant plus de contrôle sur les résultats avec une grande qualité. Et comme Meta le dit si bien, ce n'est que le début de ce nouveau type de modèle d'IA. Les approches continueront de s'améliorer à la fois en termes de qualité et de disponibilité pour le public, ce qui est super excitant.
De nombreux artistes utilisent déjà le modèle pour leur propre travail, comme décrit dans le billet de blog de Meta, et je suis excité de savoir quand nous pourrons également l'utiliser.
Leur approche ne nécessite aucune connaissance en programmation, seulement une bonne main d'esquisse et un peu de “prompt engineering”, ce qui signifie des essais et des erreurs avec les entrées de texte peaufinant les formulations et les mots utilisés pour produire des résultats différents et meilleurs.
Bien sûr, ce n'était qu'un aperçu de la nouvelle approche de Make-A-Scene, et je vous invite à lire l'article complet lié ci-dessous pour un aperçu complet de son fonctionnement.
J'espère que vous avez apprécié cet article, et je vous verrai la semaine prochaine avec un autre article incroyable!
Louis
References
►Blog de Meta: https://ai.facebook.com/blog/greater-creative-control-for-ai-image-generation
►Article: Gafni, O., Polyak, A., Ashual, O., Sheynin, S., Parikh, D. and Taigman, Y., 2022. Make-a-scene: Scene-based text-to-image generation with human priors. https://arxiv.org/pdf/2203.13131.pdf
►Ma Newsletter (anglais): https://www.louisbouchard.ai/newsletter/