Créez des modèles 3D animables avec l'IA
Si vous êtes dans les effets visuels, le développement de jeux ou la création de scènes 3D, ce nouveau modèle d'IA est fait pour vous. Je ne serais pas surpris de voir ce modèle ou des approches similaires dans votre processus de création très prochainement, vous permettant de consacrer beaucoup moins de temps, d'argent et d'efforts à la création de modèles 3D. Regardez ça…

Gauche : vidéos d'entrée ; À droite : reconstruction à chaque instance de temps. Les correspondances retrouvées sont représentées par les mêmes couleurs. Image de la page du projet des auteurs.
Bien sûr, ce modele créé n'est pas parfait, mais il a été fait instantanément avec une vidéo prise a l’aide d’un téléphone. Le modele d’IA n’a pas besoin d'une configuration multi-caméras coûteuse ou de capteurs de profondeur complexes. L'une des beautés derrière l'IA : rendre des technologies complexes et coûteuses à la disposition des startups ou des particuliers pour créer des projets avec des résultats de qualité professionnelle. Filmez simplement un objet et transformez-le en un modèle que vous pouvez importer immédiatement dans votre application. Vous pourrez ensuite peaufiner les détails si vous n'êtes pas satisfait, mais tout le modèle de base sera là en quelques secondes !
Ce que vous voyez ci-dessus sont les résultats d'un modèle d'IA appelé BANMo, récemment partagé lors de l'événement CVPR auquel j'ai assisté. Je vais être honnête, ils ont aussi attiré mon attention à cause des chats. Mais ce n’est pas totalement “clickbait”! Le papier et l'approche sont en fait assez impressionnants. Ce n'est pas comme n'importe quelle approche NeRF pour reconstruire des objets dans des modèles 3D. BANMo s'attaque à une tâche que nous appelons la reconstruction de formes 3D articulées, ce qui signifie qu'il fonctionne avec des vidéos et des images pour modéliser des objets déformables, et quoi de plus déformable qu'un chat ? Et ce qui est encore plus cool que de voir les résultats, c’est de comprendre comment ça fonctionne…
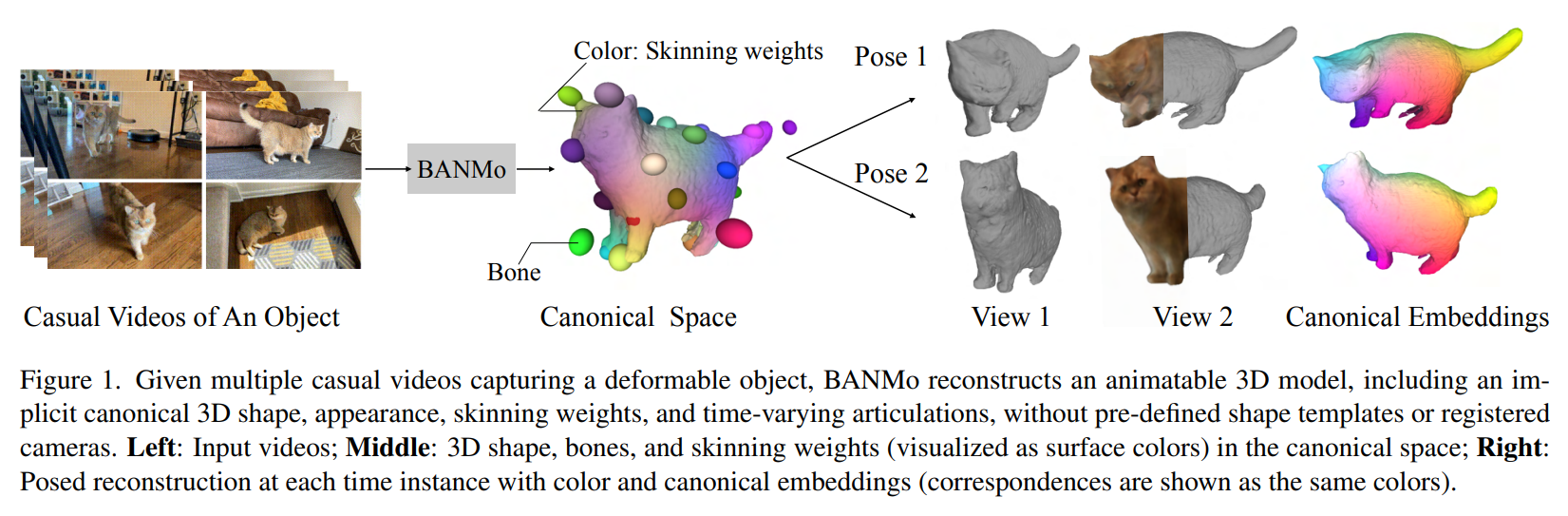
Le modèle commence par quelques vidéos prises de l'objet que vous souhaitez capturer, montrant comment il se déplace et se déforme dans l’espace. C'est là que vous voulez envoyer la vidéo de votre chat qui aspire dans un vase !
BANMo utilise ces vidéos pour créer ensuite ce qu'ils appellent un espace canonique. Ce premier résultat vous donnera des informations sur la forme, l'apparence et les articulations de l'objet. C'est la compréhension du modèle de la forme de votre objet, comment il se déplace dans l'espace et où il se trouve en terme de “solodité” entre une brique et de l’eau, décrit à partir de ces grosses boules de différentes couleurs.
Le modèle prend ensuite cette représentation 3D et applique la pose que vous voulez, simulant le comportement et les articulations du chat aussi près que possible de la réalité.
Cela semble magique, n'est-ce pas? C'est parce que nous n'avons pas fini ici. On est vite passé d'une vidéo à la maquette, mais c'est là que ça devient intéressant.
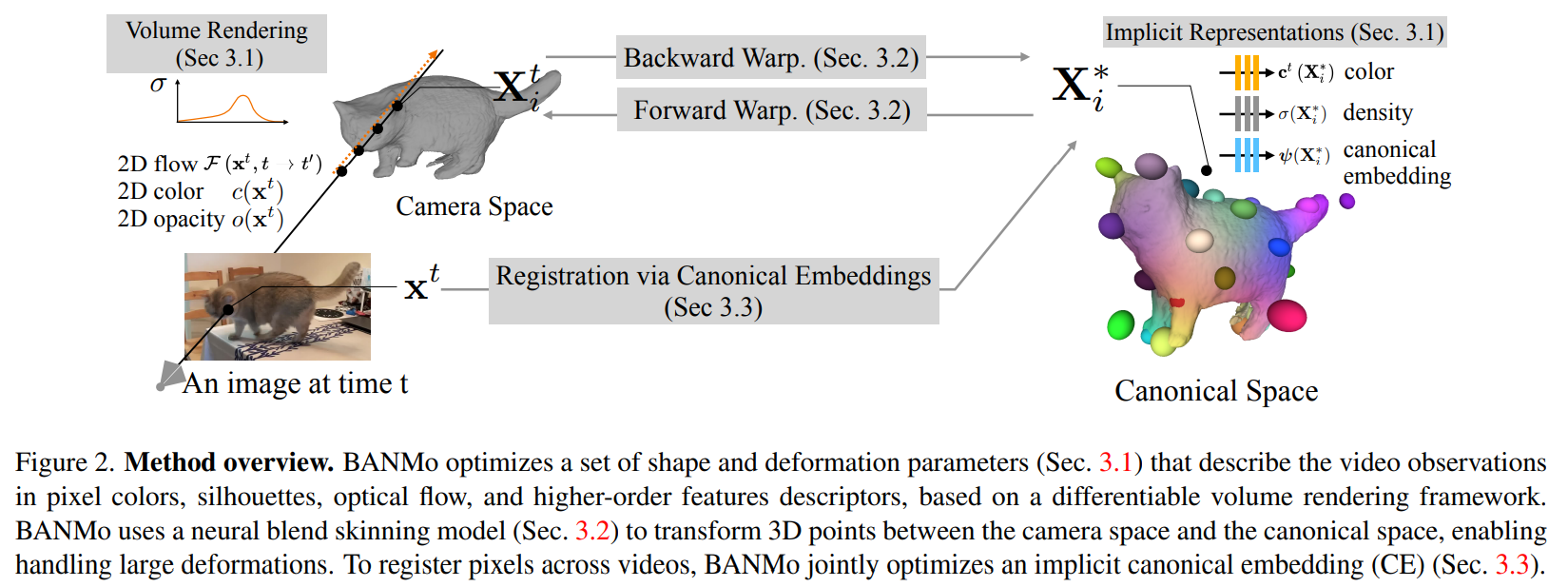
Image tirée du papier.
Alors qu'utilisent-ils pour passer des images d'une vidéo à une telle représentation dans cet espace canonique ? Vous l'avez deviné : un modèle de type NeRF !
Si vous n'êtes pas familier avec cette approche, je vous invite fortement à regarder l'un des nombreux articles que j'ai fait les couvrant et à revenir pour le reste.
En bref, la méthode inspirée de NeRF devra prédire trois propriétés essentielles pour chaque pixel tridimensionnel de l'objet, comme vous le voyez ici : la couleur, la densité et une intégration canonique à l'aide d'un réseau de neurones formé pour cela. Pour obtenir un modèle 3D avec des articulations et des mouvements réalistes, BANMo utilise l'emplacement spatial de la caméra et plusieurs images pour comprendre d’où la caméra filme et où est le chat ainsi que son positionnement, lui permettant de reconstruire et d'améliorer le modèle 3D de manière itérative à travers toutes les images de la vidéo, similaire à ce que nous ferions pour comprendre un objet, le déplacer et le regarder dans toutes les directions.
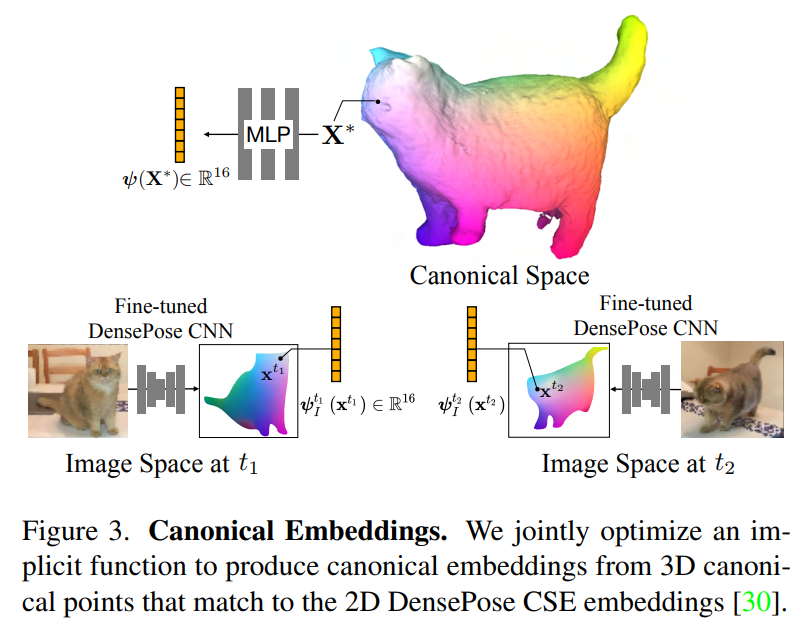
Image tirée du papier.
Cette partie se fait automatiquement en observant les vidéos, grâce à l’intégration canonique dont nous venons de discuter. Cette intégration contiendra toutes les caractéristiques nécessaires de chaque partie de l'objet pour vous permettre d'interroger avec une nouvelle position souhaitée pour l'objet en imposant une reconstruction cohérente compte tenu des observations. Il cartographiera essentiellement la position souhaitée de l'image pour le modèle 3D avec les points de vue et les conditions d'éclairage corrects et fournira des indices pour la forme et les articulations nécessaires.
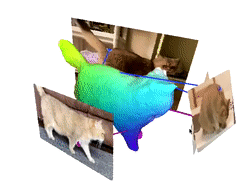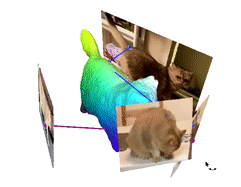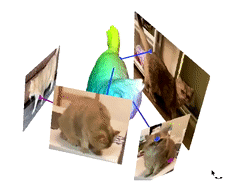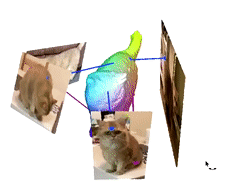
Image de la page du projet des auteurs.
Une dernière chose à mentionner est nos couleurs qu’on retrouve sur le modèle 3D. Ces couleurs représentent les attributs corporels du chat partagés dans les différentes vidéos et images que nous avons utilisées. C'est la fonctionnalité que nous allons apprendre et examiner pour extraire des informations précieuses de toutes les vidéos et les fusionner dans le même modèle 3D afin d'améliorer nos résultats.
Et voilà !
Vous vous retrouvez avec ce magnifique chat coloré déformable en 3D que vous pouvez utiliser dans vos applications !

Image de la page du projet des auteurs.
Bien sûr, ce n'était qu'un aperçu de BANMo, et je vous invite à lire le document pour une compréhension plus approfondie du modèle.
References
► Le projet: https://banmo-www.github.io/
► L’article: Yang, G., Vo, M., Neverova, N., Ramanan, D., Vedaldi, A. and Joo, H., 2022. Banmo: Building animatable 3d neural models from many casual videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 2863–2873).
► Code: https://github.com/facebookresearch/banmo