Comment OpenAI réduit les risques pour DALL·E 2
Vous avez certainement déjà vu des images incroyables comme celles-ci, entièrement générées par un modèle d'intelligence artificielle. J'ai couvert plusieurs approches sur ma chaîne et ce blog, comme Craiyon, Imagen et la plus connue, Dall-e 2.

Image générée à l'aide de Dalle 2 avec le texte : "Un équipage de b-boy astronautes se produisant sur Mars, polaroid". Partagé sur la page Instagram d'OpenAI.
La plupart des gens veulent essayer ces modèles et générer des images à partir de textes aléatoires, mais la majorité de ces modèles ne sont pas open source, ce qui signifie que nous, les gens ordinaires, ne pouvons pas les utiliser librement. Pourquoi? C'est ce sur quoi nous allons discuter dans cet article.
J'ai dit que la plupart d'entre eux n'étaient pas open-source.
Eh bien, Craiyon l'est, et les gens ont généré des memes incroyables en l'utilisant.



Vous voyez à quel point un tel modèle peut devenir dangereux : permettre à n'importe qui de générer n'importe quoi. Non seulement pour les abus possibles concernant les générations impliquant des personnalités réelles, mais aussi pour les données utilisées pour former de tels modèles, provenant d'images aléatoires venanty d’Internet, à peu près n'importe quoi, avec un contenu parfois douteux et produisant des images inattendues. Ces données d’entraînement pourraient également être récupérées par ingénierie inverse du modèle, ce qui est indésirable(c.à.d. aller chercher les images utilisées lors de l’entraînement du modèle à l’aide de ce dernier).
OpenAI a également utilisé cela pour justifier de ne pas distribuer le modèle Dall-e 2 au public. Ici, nous examinerons ce qu'ils étudient comme risques potentiels et comment ils essaient de les atténuer. Je vais passer en revue un article qu'ils ont écrit sur leurs étapes de prétraitement des données lors de la formation de Dall-e 2.
Qu'est-ce qu'OpenAI a vraiment à l'esprit quand ils disent qu'ils font des efforts pour réduire les risques ?
Premièrement, et la plus évidente, c'est qu'ils filtrent les images violentes et sexuelles parmi les centaines de millions d'images sur Internet. Ceci afin d'empêcher le modèle d'apprendre à produire du contenu violent et sexuel ou même de restituer les images originales au fil des générations.
Cette approche est comparable à ne pas apprendre à votre enfant à se battre dans le but qu’il n’entre jamais en bagarre. Cela peut aider, mais c'est loin d'être une solution parfaite ! Pourtant, je pense qu'il est nécessaire d'avoir de tels filtres dans nos ensembles de données, et cela aide certainement dans certains cas comme celui-ci.
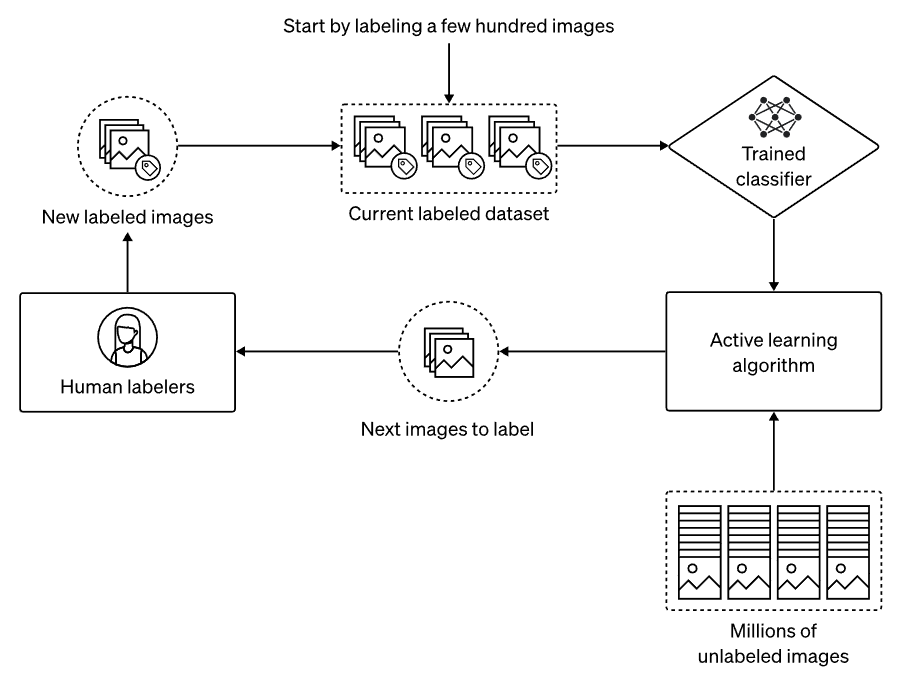
“We start with a small dataset of labeled images (top of figure). We then train a classifier on this data. The active learning process then uses the current classifier to select a handful of unlabeled images that are likely to improve classifier performance. Finally, humans produce labels for these images, adding them to the labeled dataset. The process can be repeated to iteratively improve the classifier’s performance.” Image et citation du blog d’OpenAI.
Mais comment font-ils cela exactement ? Ils construisent plusieurs modèles formés pour classer les données à filtrer ou non en leur donnant quelques exemples positifs et négatifs différents (image violente ou non, image sexuelle ou non) et améliorent itérativement les classificateurs avec un retour humain. Chaque classificateur pours l’entièreté de notre ensemble de données en supprimant plus d'images que nécessaire, juste au cas où, car il est préférable que le modèle ne voie pas de mauvaises données en premier lieu plutôt que de tenter de le corriger par la suite. Chaque classificateur aura une compréhension unique du contenu à filtrer et se compléteront tous, assurant un bon filtrage. Si par bon, nous entendons pas d'images faussement négatives passant par le processus de filtrage (une image classée comme étant sécure, mais contenant de la violence, par exemple).
Pourtant, cela a des inconvénients. Premièrement, l'ensemble de données est clairement plus petit et peut ne pas représenter avec précision le monde réel, ce qui peut être bon ou mauvais selon le cas d'utilisation. Ils ont également découvert un effet secondaire inattendu de ce processus de filtrage des données : il amplifiait les biais du modèle envers certaines données démographiques. Ce qui mène à la deuxième chose que fait OpenAI comme atténuation de risques lors de la pré-formation du modèle : réduire les biais causés par ce filtrage.

“Generations for the prompt “military protest” from our unfiltered model (left) and filtered model (right). Notably, the filtered model almost never produces images of guns.” Image et citation du blog d’OpenAI.
Par exemple, après le filtrage, l'un des biais qu'ils ont remarqués était que le modèle générait plus d'images d'hommes et moins de femmes par rapport aux modèles formés sur l'ensemble de données d'origine. Ils expliquent que l'une des raisons peut être que les femmes apparaissent plus souvent que les hommes dans le contenu sexuel — ce qui peut biaiser leurs classificateurs pour supprimer plus d'images fausses positives contenant des femmes de l'ensemble de données, créant un écart dans le rapport entre les sexes que le modèle observe dans la formation et répliques.
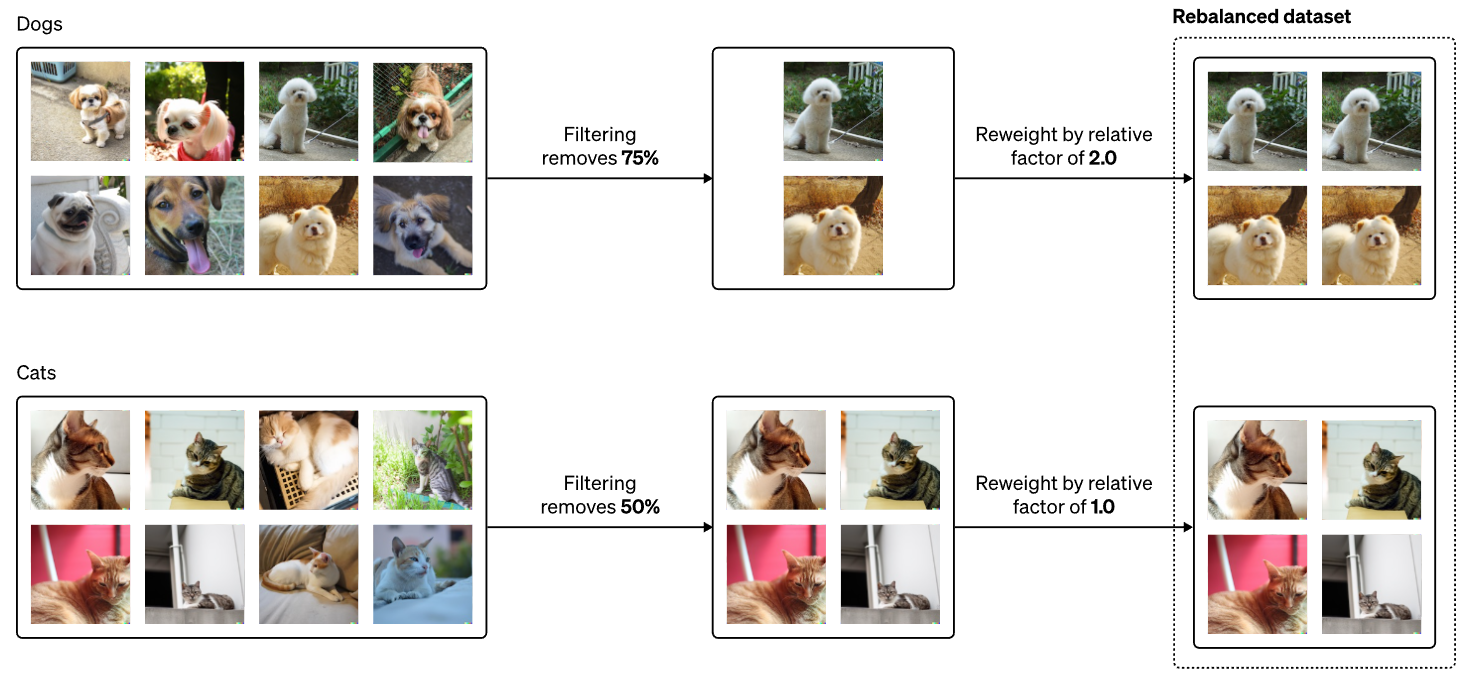
“An illustration of dataset reweighting. We start with a balanced dataset (left). If our filter affects one category more than another, it can create a biased dataset (middle). Using reweighting, we effectively “repeat” some data more than others, allowing us to rebalance the bias caused by the filters (right).” Image et citation du blog d’OpenAI.
Pour résoudre ce problème, ils tentent de faire en sorte que l'ensemble de données filtré corresponde à la distribution de l'ensemble de données préfiltré initial. Voici un exemple qu'ils couvrent en utilisant des chats et des chiens où le filtre supprimerait plus de chiens que de chats, donc la solution serait de doubler le coût rattaché au modèle lors de l’entraînement pour les images de chiens, ce qui reviendrait à envoyer deux images de chiens au lieu d'une et à compenser le manque d'images. Il ne s'agit encore une fois que d’un “quick fix” du biais de filtrage, mais cela réduit au moins l'écart de distribution d'image entre l'ensemble de données préfiltré et filtré.
Le dernier problème est un problème de mémorisation, un point où les modèles semblent être beaucoup plus puissants que moi. Comme nous l'avons dit, il est possible de régurgiter les données d'entraînement à partir de tels modèles de génération d'images, ce qui n'est pas souhaité dans la plupart des cas. Ici, nous voulons également générer de nouvelles images et pas simplement copier-coller des images provenant d'Internet.
Mais comment pouvons-nous empêcher cela? Tout comme notre mémoire, vous ne pouvez pas vraiment décider de ce dont vous vous souvenez et de ce qui s'en va. Une fois que vous voyez quelque chose, soit ça reste, soit ça ressort directement, comme le nom d’une nouvelle rencontre.
Ils ont découvert que, tout comme les humains apprenant un nouveau concept, si le modèle voit les mêmes images plusieurs fois dans l'ensemble de données, il peut accidentellement les connaître par cœur à la fin de sa formation et les générer exactement pour une invite de texte similaire ou identique.
Ce problème détient une solution simple et fiable : découvrez simplement quelles images sont trop similaires et supprimez les doublons. Facile? Hmm, cela reviendrait à comparer chaque image avec toutes les autres images, ce qui signifie des centaines de quadrillions de paires d'images à comparer. Au lieu de cela, ils commencent simplement par regrouper des images similaires, puis comparent les images avec toutes les autres images dans le même et quelques autres groupes d’images similaires, réduisant considérablement la complexité tout en trouvant 97% de toutes les paires en double.
Encore une fois, ceci est une autre correction à faire dans l'ensemble de données avant de former notre modèle Dall-e 2.
OpenAI mentionne également quelques prochaines étapes sur lesquelles ils enquêtent, et si vous avez apprécié cet article, je vous invite définitivement à lire leur article détaillé pour voir tous les détails de ce travail d'atténuation de pré-formation. C'est un article très intéressant et bien écrit. Le lien est en référence ci-bas.
Faites-moi savoir ce que vous pensez de leurs efforts d'atténuation et de leur choix de limiter l'accès du modèle au public. Laissez un commentaire ou rejoignez la discussion dans notre communauté sur Discord !
Merci d'avoir lu jusqu'au bout !
Je vous verrai la semaine prochaine avec un autre papier incroyable!
Louis
Références
Article d’OpenAI: https://openai.com/blog/dall-e-2-pre-training-mitigations/
Ma vidéo sur Dalle 2: https://youtu.be/rdGVbPI42sA
Ma vidéo sur Craiyon: https://youtu.be/qOxde_JV0vI
Utilisez Craiyon: https://www.craiyon.com/