Guider “Stable Diffusion” avec vos propres images!
Les modèles de Texte-à-Image comme DALLE ou “Stable Diffusion” sont vraiment cool et nous permettent de générer des images fantastiques avec une simple saisie de texte. Mais serait-il encore plus cool de leur donner une photo de vous et de lui demander de la transformer en peinture ? Imaginez pouvoir envoyer n'importe quelle image d'un objet, d'une personne ou même de votre chat, et demander au modèle de la transformer en un autre style, comme vous transformer en cyborg, dans votre style artistique préféré ou l'ajouter à une nouvelle scène.

Au fond, ce serait cool d'avoir une version de DALLE que nous pouvons utiliser pour photoshoper nos images au lieu d'avoir des générations aléatoires. Avoir un DALLE personnalisé, tout en rendant beaucoup plus simple le contrôle de la génération, car « une image vaut mille mots ». Ce serait comme avoir un modèle DALLE tout aussi personnalisé et addictif que l'algorithme de TikTok.
Eh bien, c'est ce sur quoi ont travaillé des chercheurs de l'Université de Tel Aviv et de NVIDIA. Ils ont développé une approche pour conditionner les modèles texte-à-image, comme “Stable Diffusion” que j'ai abordée la semaine dernière, avec quelques images pour représenter n'importe quel objet ou concept à travers les mots que vous enverrez avec vos images. Transformer l'objet de vos images d'entrée en ce que vous voulez.

Bien sûr, les résultats nécessitent encore du travail, mais ce n'est que le premier article s'attaquant à une tâche aussi incroyable qui pourrait révolutionner l'industrie du design. Comme le dirait un fantastique collègue YouTuber : imaginez ce que les résultats seront deux autres articles dans l’avenir.
Alors, comment pouvons-nous prendre quelques photos d'un objet et générer une nouvelle image à la suite d'une entrée conditionnée par du texte pour ajouter les détails de style ou de transformation ?
Pour répondre à cette question complexe, regardons ce que Rinon Gal et son équipe ont trouvé. Les images d'entrée sont encodées dans ce qu'ils appellent un pseudo-mot que vous pouvez ensuite utiliser dans votre génération de texte. Ainsi le nom du papier, « une image vaut un mot ». Mais comment obtiennent-ils ce pseudo-mot et qu'est-ce que c'est ?
Ils commencent avec trois à cinq images d'un objet spécifique. Ils utilisent également un modèle texte-à-image pré-formé (image ci-dessous, à droite). Dans ce cas, ils utilisent la diffusion latente, le modèle que j'ai couvert il n'y a même pas une semaine qui prend n'importe quel type d'entrées comme des images ou du texte et génère de nouvelles images à partir d'eux. Vous pouvez le voir comme un DALLE Open-Source. Si vous n'avez pas encore lu mon article, vous devriez faire une pause, vous renseigner sur ce modèle et revenir ici. Vous allez adorer l’article et découvrir l'architecture la plus en vogue du moment !
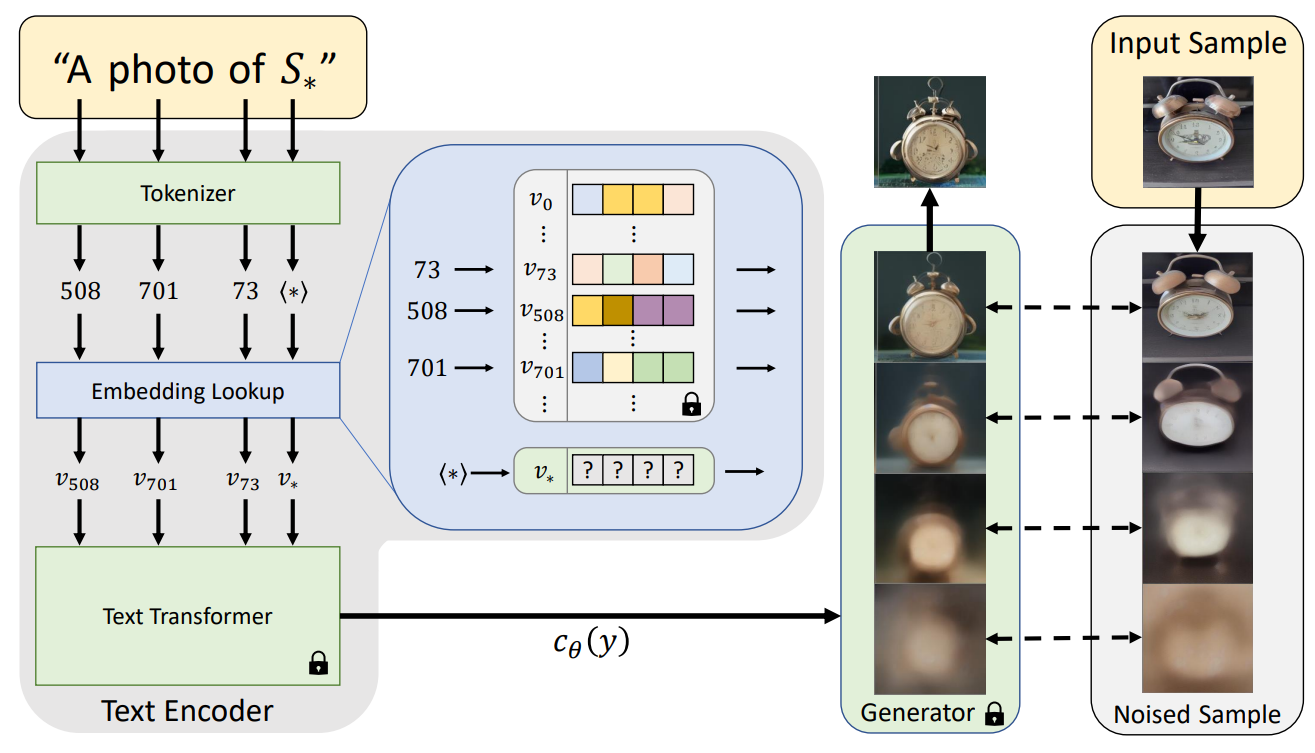
Vous avez donc vos images d'entrée et le modèle de base pour générer des images conditionnées sur des entrées telles que du texte ou d'autres images. Mais que faites-vous de vos 3 à 5 images de votre objet avec lesquelles nous avons commencé ? Et comment contrôlez-vous les résultats du modèle si précisément que votre objet apparaît dans les générations ?
Tout cela est fait pendant le processus de formation de votre deuxième modèle : l'encodeur de texte (image ci-dessus, à gauche). À l'aide de votre modèle de générateur d'images pré-entraîné et fixe, en l'occurrence la diffusion latente, déjà capable de prendre une photo et de la reconstituer, vous souhaitez apprendre à votre modèle d'encodeur de texte à faire correspondre votre pseudo-mot à vos images encodées, ou, en d'autres termes mots, vos représentations tirées de vos cinq images. Vous alimenterez donc votre réseau de générateurs d'images avec vos 3 à 5 images et entraînerez votre encodeur de texte à l'envers pour savoir quels “faux mots”, ou pseudo-mots, représenteraient le mieux toutes vos images encodées.
Fondamentalement, découvrez comment représenter correctement votre concept dans le même espace que celui où se produit le processus de génération d'image que j'ai décrit dans mon article précédent. Ensuite, extrayez-en un faux mot pour guider les générations futures. De cette façon, vous pouvez injecter votre concept dans toutes les générations futures et ajouter quelques mots pour conditionner encore plus la génération en utilisant le même modèle texte-à-image pré-entraîné. Ainsi, vous entraînerez simplement un petit modèle pour comprendre où se trouvent vos images dans l'espace latent afin de les convertir en un faux mot à utiliser dans le modèle de génération d'images standard. Vous n'avez pas besoin de toucher au modèle de générateur d'images, et c'est assez important compte tenu du coût de leur formation !
Et voilà ! C'est ainsi que vous pouvez apprendre à un modèle de type DALLE ou “Stable Diffusion” à générer des variations d'image de votre objet préféré ou à effectuer de puissants transferts de style.

Bien sûr, ce n'est qu'un aperçu de cette nouvelle méthode qui s'attaque à une tâche très intéressante et je vous invite à lire leur article lié ci-dessous pour une compréhension plus approfondie de l'approche et des défis.
C'est une tâche très compliquée et il y a encore beaucoup de limitations comme le temps qu'il faut pour comprendre un tel concept dans un faux mot, qui est d'environ 2 heures. Il n'est pas non plus encore capable de comprendre complètement le concept, mais est sacrément proche. Il y a aussi beaucoup de risques à avoir un tel produit accessible que nous devons considérer. Imaginez être capable d'intégrer le concept d'une personne spécifique et de générer n’importe quel image incluant la personne. C'est assez effrayant et ce genre de technologie est tout près. Si jamais vous aimez penser à cela, j'aimerais entendre vos réflexions en commentaire ou en discuter sur notre serveur Discord.
Merci d'avoir lu et je vous verrai la semaine prochaine avec un autre article incroyable!
References
►Paper: Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G. and Cohen-Or, D., 2022. An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion. https://arxiv.org/pdf/2208.01618v1.pdf
►Code: https://textual-inversion.github.io/
►Ma Newsletter (Anglais): https://www.louisbouchard.ai/newsletter/