Que voit une voiture autonome ? (Le système de Waymo expliqué)
Comment voient les véhicules autonomes ?
Vous avez probablement entendu parler des capteurs LiDAR ou d'autres caméras étranges qu'ils utilisent. Mais comment fonctionnent-ils, comment voient-ils le monde, et que voient ces voitures exactement par rapport à nous ? Comprendre comment elles fonctionnent est essentiel si nous voulons les mettre sur la route, principalement si vous travaillez au gouvernement ou élaborez les prochaines réglementations. Mais aussi en tant que client de ces services.
Nous avons déjà vu comment le pilote automatique Tesla voit et fonctionne , mais ils sont différents des véhicules autonomes plus conventionnels. Tesla utilise uniquement des caméras pour comprendre le monde, alors que la plupart d'entre eux, comme Waymo , utilisent des caméras ordinaires couplés à des capteurs LiDAR 3D. Ces capteurs LiDAR sont assez simples à comprendre : ils ne produiront pas d'images comme les caméras classiques mais des nuages de points 3D. Les caméras LiDAR mesurent la distance entre les objets, calculant le temps de déplacement d’impulsions de laser qu'ils projettent sur l'objet.

"Le capteur LiDAR permet la détection 3D des distances", Electronic Specificer
De cette façon, ils produiront très peu de points de données avec des informations de distance précieuses et exactes, comme vous pouvez le voir ici. Ces points de données sont appelés nuages de points, et cela signifie simplement que ce que nous verrons ne sont que de nombreux points aux bonnes positions, créant une sorte de modèle du monde.

"Le capteur LiDAR permet la détection 3D des distances", Electronic Specificer
Ici, vous pouvez voir comment le LiDAR, à droite, n'est pas si précis pour comprendre ce qu'il voit, mais il est assez bon pour comprendre la profondeur avec très peu d'informations (les quelques lignes qu’on peut apercevoir), ce qui est parfait pour calculer efficacement les données en temps réel. Un critère essentiel pour les véhicules autonomes.
Cette quantité minimale de données et cette précision spatiale élevée sont idéales, car couplées aux images RVB (rouge vert bleu), comme illustré à gauche, nous avons à la fois des informations de distance précises et les informations d'objet précises qui nous manquent avec les données LiDAR seules, en particulier pour les objets ou personnes éloignés. C'est pourquoi Waymo et d'autres sociétés de véhicules autonomes utilisent les deux types de capteurs pour comprendre le monde.
Pourtant, comment pouvons-nous combiner efficacement ces informations et les faire comprendre au véhicule ? Et qu'est-ce que le véhicule finit par voir ? Seulement des points partout ? Est-ce suffisant pour rouler sur nos routes ? Nous examinerons cela avec un nouveau papier de recherche de Waymo et Google Research [1].
Je pense que je ne pourrais pas mieux résumer l'article que la phrase qu'ils ont utilisée dans leur article ;
"Nous présentons 4D-Net, qui apprend à combiner des nuages de points 3D dans le temps et des images de caméra RVB dans le temps, pour l'application généralisée de la détection d'objets 3D dans la conduite autonome." [1]
J'espère que vous avez apprécié l'article. N'hésitez pas à me dire si vous avez apprécié la lecture et… je plaisante ! Plongeons un peu plus dans cette phrase.

L'architecture 4D-Net où nous fusionnons les trames LiDAR et RVB. Image tirée de l'article [1].
Voici à quoi ressemble la détection d'objets 3D dont nous parlons. Et c'est aussi ce que la voiture finira par voir. C'est une représentation très précise du monde autour du véhicule avec tous les objets apparaissant et précisément identifiés.
C’est top! Mais plus intéressant encore, comment en sont-ils arrivés à ce résultat ?
Ils ont produit cette vue à l'aide de données LiDAR, appelées nuages de points dans le temps (PCiT), et de caméras ordinaires, ou ici appelées vidéos RVB. Ce sont deux entrées en 4 dimensions, tout comme nous, les humains, voyons et comprenons le monde. Les quatre dimensions proviennent des vidéos prises dans le temps, de sorte que le véhicule a accès aux images passées pour aider à comprendre le contexte et les objets pour deviner les comportements futurs, tout comme nous le faisons, créant la quatrième dimension. Les trois autres sont l'espace 3D que nous connaissons.

Compréhension de scène. Image de l'auteur.
Nous appelons cette tâche la compréhension de scène, et elle a été largement étudiée en vision par ordinateur et a connu de nombreuses avancées avec les progrès récents des algorithmes d'apprentissage automatique. C'est aussi crucial dans les véhicules autonomes, où l'on veut avoir une compréhension quasi parfaite des scènes.
Si nous revenons au réseau que nous avons vu plus haut, vous pouvez voir que les deux réseaux se « parlent » toujours avec des connexions. C'est principalement parce que lorsque nous prenons des images, nous avons des objets à différentes distances dans la prise de vue et avec des proportions différentes.

Voitures à différentes échelles. Image de l'auteur.
La voiture devant vous semblera beaucoup plus grande que la voiture éloignée, mais vous devez toujours tenir compte des deux.
Comme nous, quand on voit quelqu'un de loin et qu'on a l'impression que c'est notre ami, mais qu'on attend de se rapprocher pour être sûr avant de crier son nom, la voiture manquera de détails pour des objets aussi lointains.

Image de l'auteur.
Pour corriger cela, nous allons extraire et partager des informations à différents niveaux du réseau. Le partage d'informations à travers le réseau est une solution puissante, car les réseaux de neurones utilisent de petits détecteurs de tailles fixes pour condenser l'image au fur et à mesure que nous pénétrons dans le réseau.

Exemple de filtre dans un réseau de neurones convolutionnels pour les couches de surfaces et profondes. Image de l'auteur.
Cela signifie que les premières couches seront capables de détecter de petits objets et uniquement des bords ou des parties d'objets plus gros. Les couches plus profondes perdront les petits objets, mais pourront détecter les gros objets avec une grande précision.
Le principal défi de cette approche est de combiner ces deux types d'informations très différentes à travers ces connexions ; les données spatiales LiDAR 3D et des images RVB plus régulières. L'utilisation des deux informations à toutes les étapes du réseau, comme décrit précédemment, est préférable pour mieux comprendre l'ensemble de la scène.
Mais comment fusionner deux flux d'informations différents et utiliser efficacement la dimension temporelle ? Cette traduction de données entre les deux branches est ce que le réseau apprend lors de son entraînement de manière supervisée avec un processus similaire à celui des mécanismes de “self-attention” que j'ai abordé dans des articles précédents en essayant de recréer le modèle réel du monde. Mais pour faciliter cette traduction des données, ils utilisent un modèle appelé PointPillars, qui prend des nuages de points et donne une représentation en 2 dimensions.

PointPillars. Image tirée de l'article [1].
Vous pouvez voir cela comme une pseudo image du nuage de points, comme ils l'appellent, créant une sorte d'image régulière représentant le nuage de points avec les mêmes propriétés que les images RVB que nous avons dans l'autre branche. Au lieu que les pixels soient de couleur rouge-vert-bleu, ils représentent simplement la profondeur et les positions des coordonnées de l'objet (x, y, z). Cette pseudo image est également très clairsemée, ce qui signifie que les informations sur cette représentation ne sont denses qu'autour des objets importants et très probablement utiles pour le modèle. En ce qui concerne le temps, nous avons simplement la quatrième dimension dans l'image d'entrée pour suivre les images.
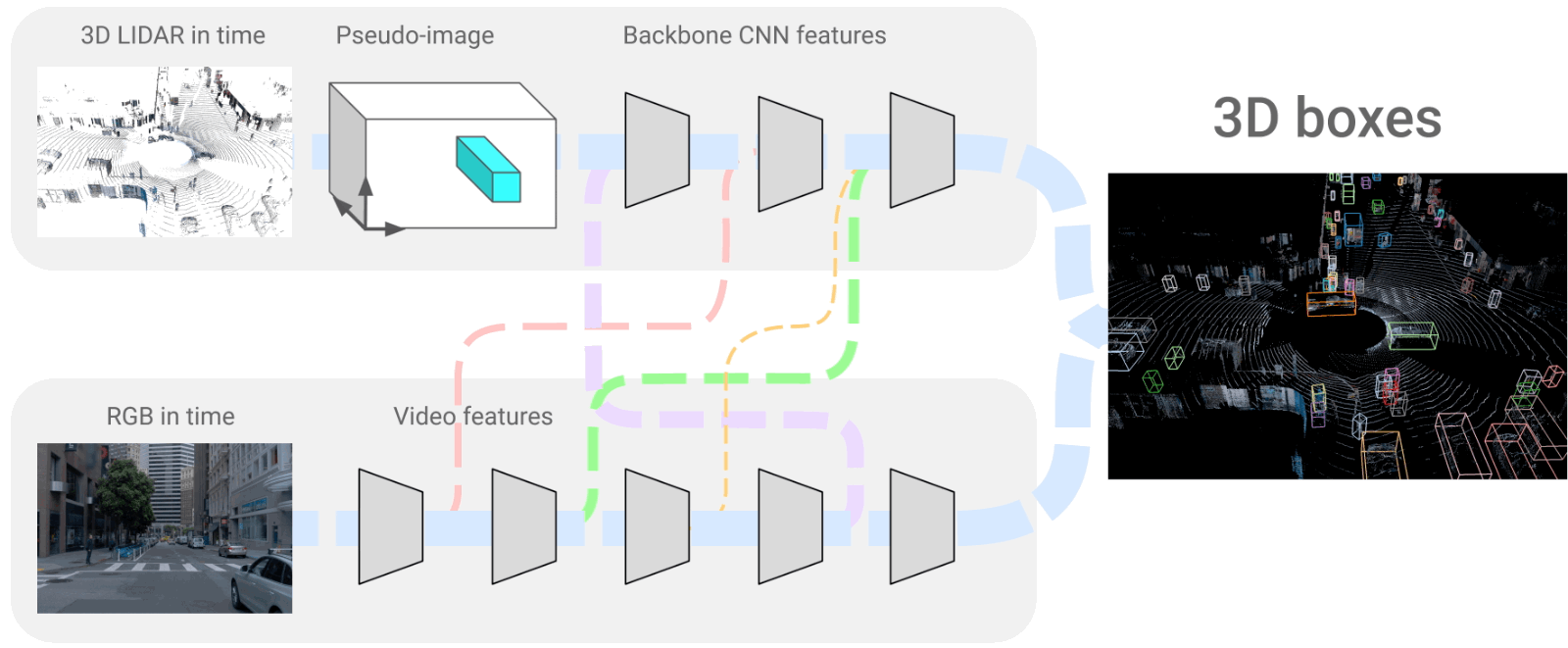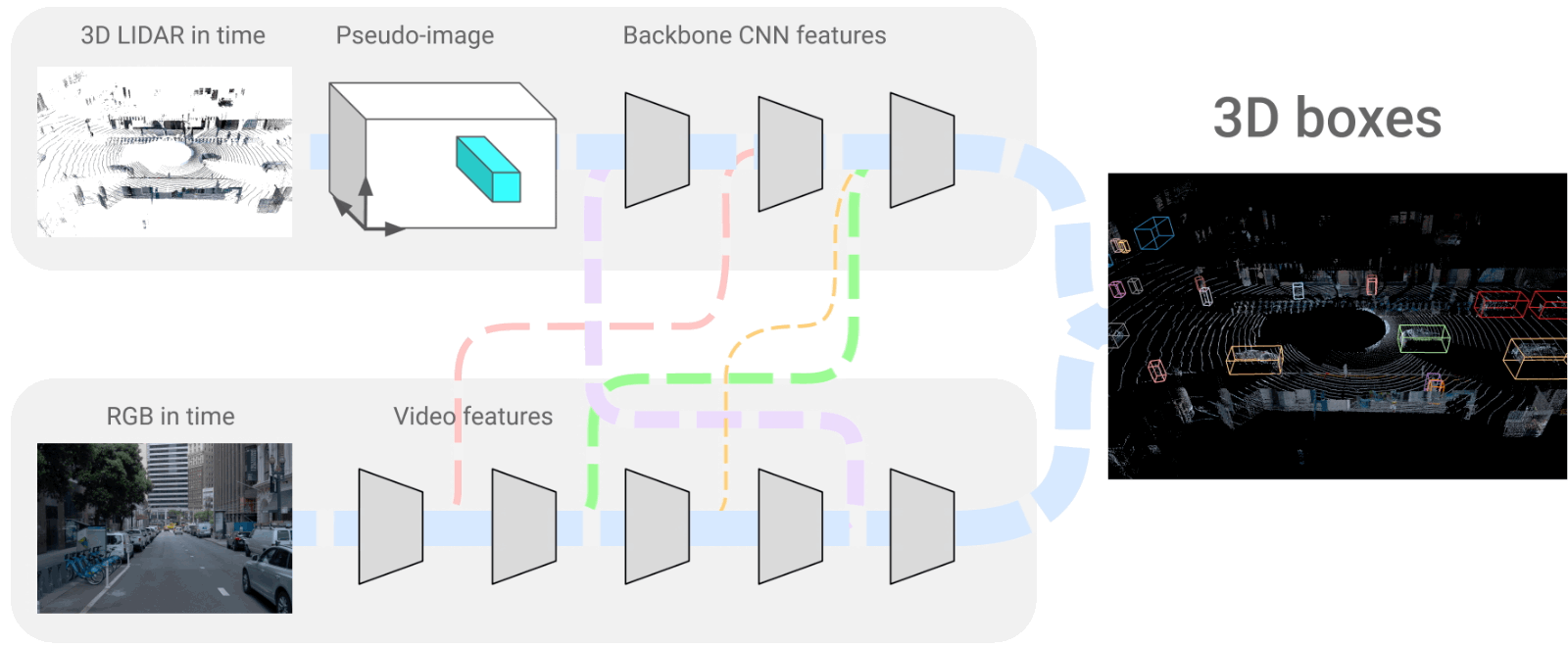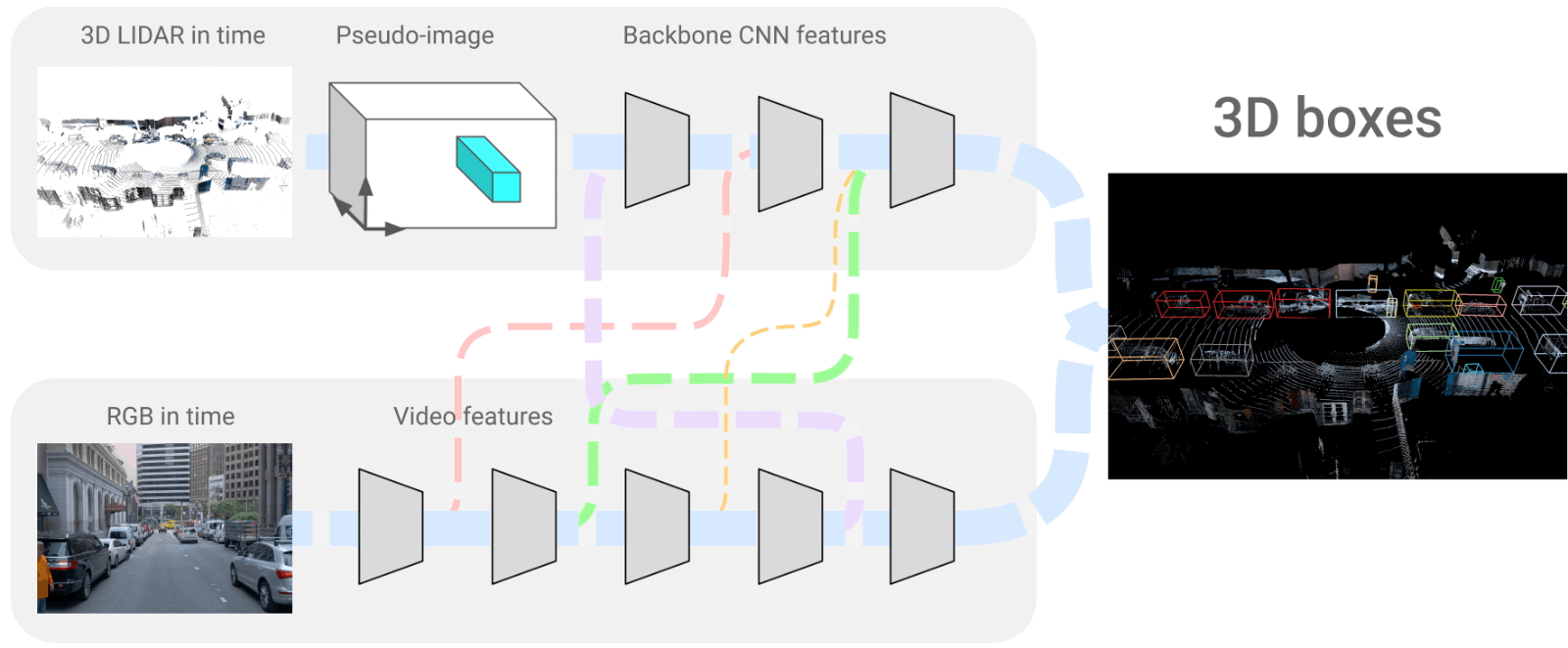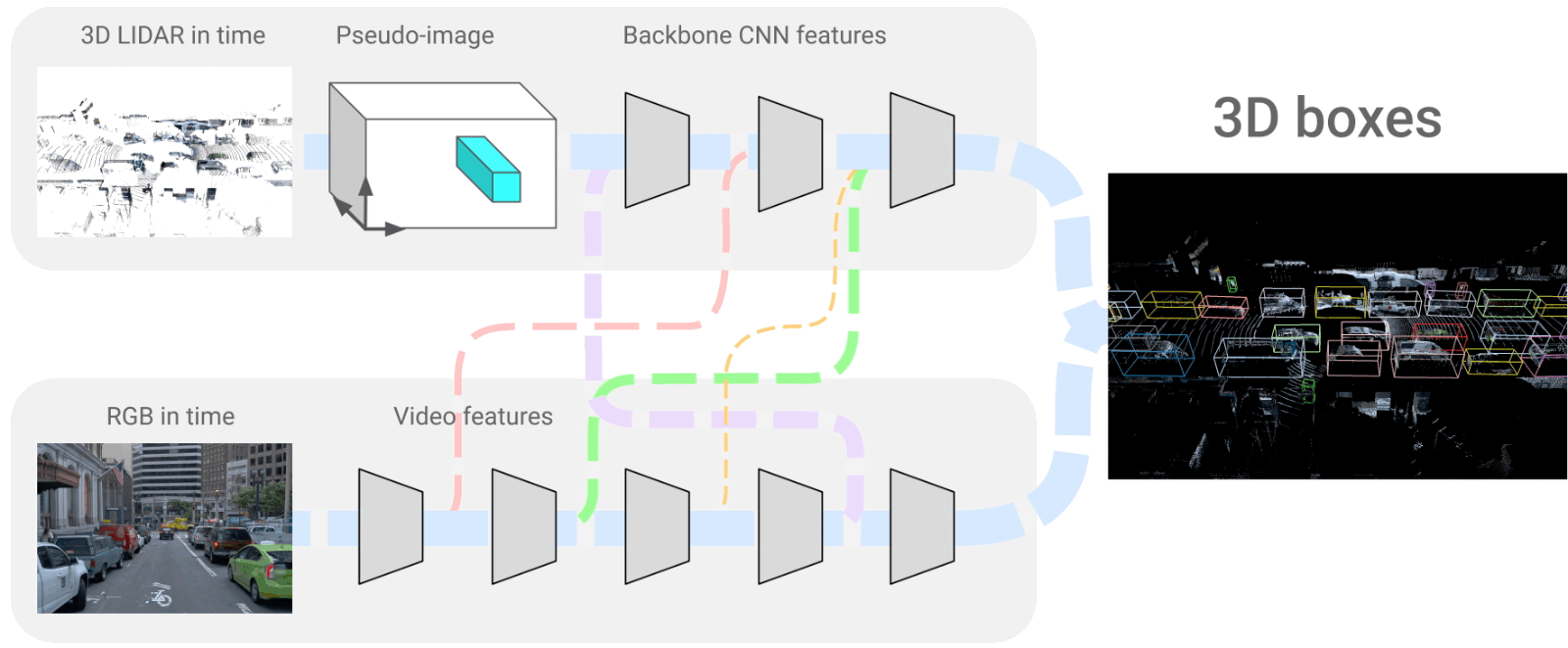
L'architecture 4D-Net où nous fusionnons les trames LiDAR et RVB. Image tirée de l'article [1].
Ces deux branches que nous voyons sont des réseaux de neurones convolutionnels qui encodent les images, comme décrit dans plusieurs de mes articles , puis décodent ces informations encodées pour recréer la représentation 3D que nous avons ici. Ils utilisent donc un encodeur très similaire pour les deux branches, partage des informations entre eux et reconstruit un modèle 3D du monde à l'aide d'un décodeur.
Et voilà ! C'est ainsi que les véhicules Waymo voient notre monde, à travers ces modèles 3D du monde que nous voyons à droite de l'image ci-dessus. Il peut traiter 32 nuages de points dans le temps et 16 images RVB en 164 millisecondes, produisant de meilleurs résultats que les autres méthodes. Cela peut ne sonner aucune cloche. Nous pouvons donc le comparer avec la seconde meilleure approche qui est moins précise et prend 300 millisecondes, soit presque le double du temps de traitement.
Bien sûr, il s'agissait d'un aperçu de ce nouvel article de Google Research et Waymo. Je recommanderais de lire l'article lié ci-dessous pour en savoir plus sur l'architecture de leur modèle et d'autres fonctionnalités dans lesquelles je n'ai pas plongé, comme le problème d'efficacité des informations temporelles.
J'espère que vous avez apprécié l'article, et si vous avez, veuillez envisager de soutenir mon travail sur YouTube en vous abonnant à ma chaîne et en commentant ce que vous pensez de ce résumé. J'aimerais lire ce que vous en pensez !
Merci d'avoir lu, et je vous verrai la semaine prochaine avec un autre article impressionnant expliqué!
Regardez la vidéo sous-titrée en français!
Les références
Piergiovanni, A.J., Casser, V., Ryoo, M.S. and Angelova, A., 2021. 4d-net for learned multi-modal alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 15435–15445).
Article de blog de Google Research : https://ai.googleblog.com/2022/02/4d-net-learning-multi-modal-alignment.html?m=1