Restaurations de photos avec l’IA !
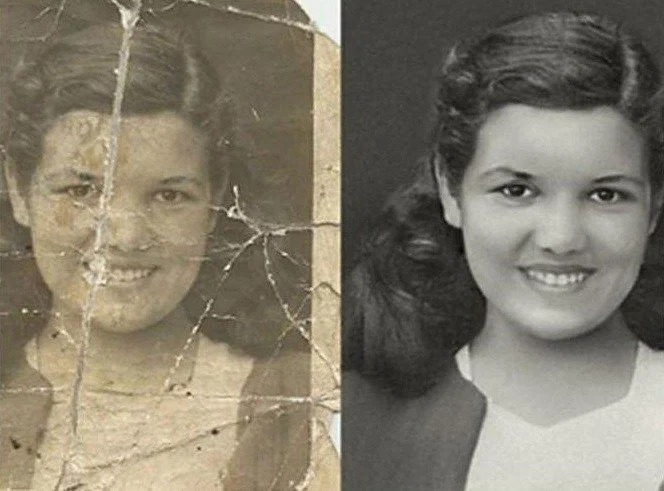
Résultats de l'exemple de restauration de photos GFP-GAN. Images produites par le modèle.
Avez-vous aussi de vieilles photos de vous-même ou de proches qui n'ont pas bien vieilli ou que vous, ou vos parents, avez prises avant que nous puissions produire des images de haute qualité ? J’en ai, et j'avais l'impression que ces souvenirs étaient endommagés à jamais. J’avais effroyablement tord !
Ce nouveau modèle d'IA entièrement gratuit (lien en références) peut réparer la plupart de vos anciennes photos en une fraction de seconde. Cela fonctionne même avec des images de très faible ou de haute qualité, ce qui est généralement tout un défi pour les modèles d’IA.
L'article de cette semaine intitulé ‘“Towards Real-World Blind Face Restoration with Generative Facial Prior” aborde la tâche de restauration de photos avec des résultats exceptionnels. Ce qui est encore plus cool, c'est que vous pouvez l'essayer vous-même et de la manière que vous préférez. Ils ont partagé leur code, créé une démo et des applications en ligne que vous pouvez essayer dès maintenant. Tout les liens sont en référence. Si les résultats que vous avez vus ci-dessus ne sont pas assez convaincants, regardez simplement la vidéo et dites-moi ce que vous en pensez dans les commentaires, je sais que ça va vous époustoufler !
J'ai mentionné que le modèle fonctionnait bien sur des images de faible qualité. Il suffit de regarder les résultats et le niveau de détail par rapport aux autres approches…

Comparaison des résultats avec d'autres approches. Entrées à gauche, GFP-GAN à droite. Image tirée du papier.
Ces résultats sont tout simplement incroyables. Par contre, ils ne représentent pas l'image réelle. Il est important de comprendre que ces résultats ne sont que des suppositions du modèle - des suppositions qui semblent sacrément proches. Aux yeux humains, cela ressemble à la même image représentant la personne. Nous ne pourrions pas deviner qu'un modèle crée ces pixels additionnels sans rien savoir d'autre sur la personne.
Le modèle fait donc de son mieux pour comprendre ce qu'il y a dans l'image, combler les lacunes ou ajouter des pixels si l'image est de faible résolution. Mais comment ça fonctionne? Comment un modèle d'IA peut-il comprendre ce qui est dans l'image et, plus impressionnant encore, comprendre ce qui n'y est pas, comme ce qui était à la place de cette rayure ?
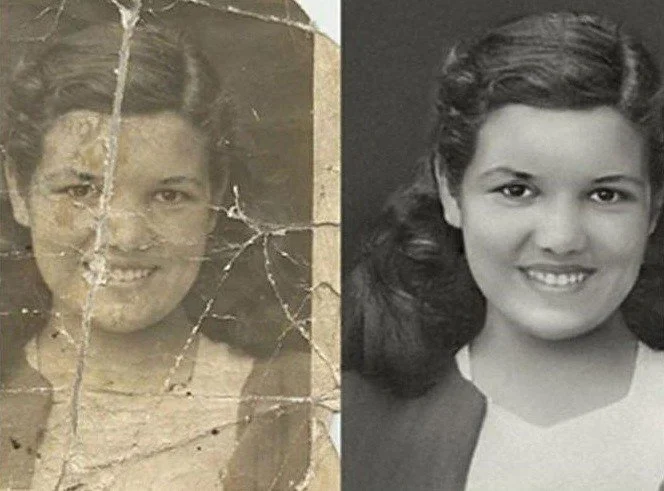
Résultats de l'exemple de restauration de photos GFP-GAN. Images produites par le modèle.
Eh bien, comme vous le verrez, les GAN ne sont pas encore morts ! En effet, les chercheurs n'ont rien créé de nouveau. Ils ont *simplement* maximisé les performances des GAN en aidant au maximum le réseau. Et quoi de mieux pour aider une architecture GAN que d'utiliser un autre GAN ?

Processus d'optimisation PULSE dans l'espace latent pour la génération d'images. Image tirée du papier.
Leur modèle s'appelle GFP-GAN pour une raison. GFP signifie “Generative Facial Prior”, et j'ai déjà couvert ce que sont les GAN dans plusieurs vidéos si cela vous semble être une autre langue. Par exemple, un modèle que j'ai couvert l'année dernière pour la super résolution d'image appelé PULSE utilise des GAN pré-entraînés comme StyleGAN-2 de NVIDIA et optimise les encodages, appelés code latent, pendant l'e ré-entraînement pour améliorer la qualité de la reconstruction de l’image en plus haute résolution. Encore une fois, si cela ne vous dit rien, veuillez prendre quelques minutes pour regarder la vidéo que j'ai faite sur le modèle PULSE.
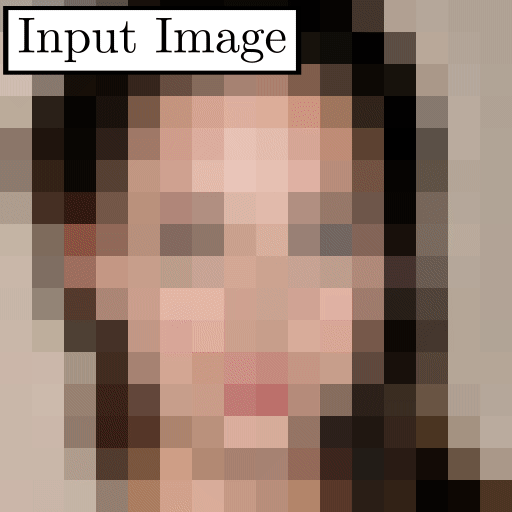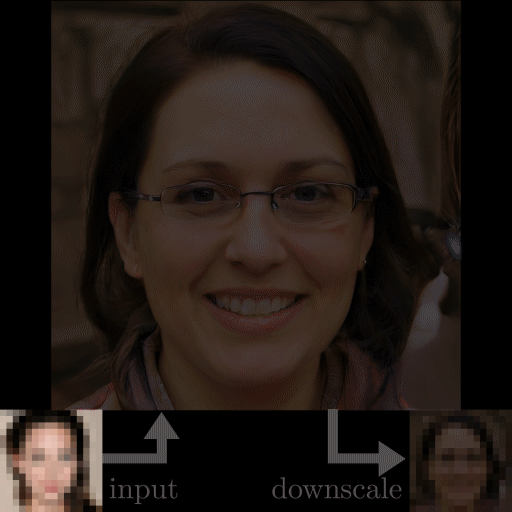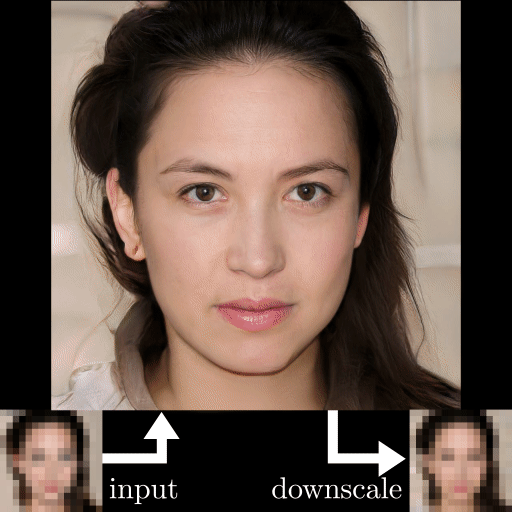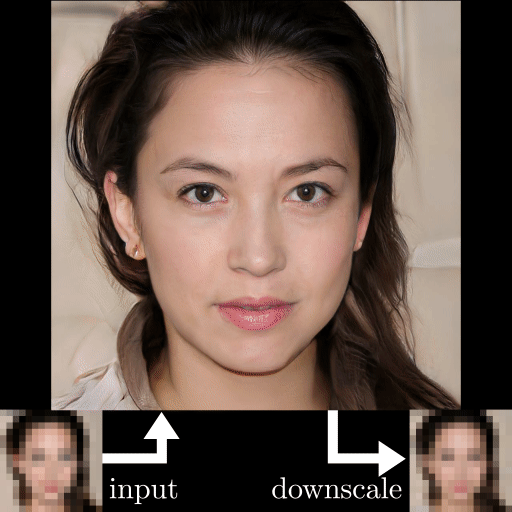
Exemples de super résolution. Image tirée du papier.
The GFP-GAN model…

Architecture GFP-GAN. Image tirée du papier.
Cependant, comme ils l'indiquent dans l'article, "ces méthodes [* référant à PULSE *] produisent généralement des images de faible fidélité, car les codes latents de faible dimension sont insuffisants pour guider la restauration" (traduit de l’anglais par l’auteur).
En revanche, GFP-GAN ne prend pas * simplement * un StyleGAN pré-entraîné et le ré-entraîne pour orienter les informations encodées pour une nouvelle tâche comme le fait PULSE.
Au lieu de cela, GFP-GAN utilise un modèle StyleGAN-2 pré-entraîné pour orienter son propre modèle génératif à plusieurs échelles pendant l'encodage de l'image jusqu'au code latent et pendant la reconstruction de l’image. Vous pouvez le voir dans la zone verte de l’image ci-dessus où nous fusionnons les informations de notre modèle actuel avec le GAN pré-entraîné avant d'utiliser leur méthode SFT à division de canaux. Vous pouvez trouver plus d'informations sur la manière exacte dont ils fusionnent les informations des deux modèles dans le document en lien ci-dessous.
Le StyleGAN-2 pré-entraîné (section verte) est notre connaissance préalable (prior knowledge) dans ce cas, car il sait déjà comment traiter l'image, mais pour une tâche différente. Cela signifie qu'ils aideront leur modèle de restauration d'image à mieux correspondre comment représenter l’image efficacement à chaque étape en utilisant ces informations préalables à partir d'un puissant modèle StyleGAN-2 pré-formé connu pour créer des encodages significatifs et générer des images précises. Cela aidera le modèle à obtenir des résultats réalistes tout en préservant une haute fidélité.
Ainsi, au lieu de simplement orienter l'entraînement en fonction de la différence entre l'image générée (fausse) et l'image attendue (réelle) en utilisant notre modèle discriminateur du réseau GAN (voir mes autres articles au sujet des GANs si cela ne vous dit rien). Nous aurons également deux métriques pour préserver l'identité et les composants les plus importants du visage. Ces deux mesures supplémentaires, appelées fonctions de coût, aideront à améliorer les détails du visage et, comme il est dit, à garantir que nous conservons l'identité de la personne, ou du moins nous faisons de notre mieux pour le faire. Voir le côté droit de l'image ci-dessus.
La fonction de coût des composantes faciales est fondamentalement la même chose que la fonction de coût adversariale du discrimateur que nous trouvons dans les GANs classiques, mais se concentre principalement sur des caractéristiques locales importantes de l'image résultante comme les yeux et la bouche.
La fonction de coût de préservation de l'identité utilise un modèle de reconnaissance faciale pré-entraîné pour capturer les traits du visage les plus importants et les comparer à l'image réelle pour voir si nous avons toujours la même personne dans l'image générée.
Et voilà ! Nous obtenons ces fantastiques résultats de reconstruction d'image en utilisant toutes ces informations provenant des différentes fonctions de coût...
Voir plus d’exemples dans la vidéo sous-titrée en Français…
Les résultats présentés dans la vidéo ont tous été produits à l'aide de la version la plus récente de leur modèle, la version 1.3. Vous pouvez voir qu'ils partagent ouvertement les faiblesses de leur approche, ce qui est très respectable.

Image de leur répertoire GitHub.
Je voudrais revenir sur quelque chose que j'ai mentionné précédemment, qui est la deuxième faiblesse affichée ci-dessus : "avoir un léger changement d'identité". En effet, cela arrivera, et nous ne pouvons rien y faire. Nous pouvons limiter ce décalage, mais nous ne pouvons pas être sûrs que l'image reconstruite sera identique à celle d'origine. C'est tout simplement impossible. Reconstruire la même personne à partir d'une image basse définition signifierait que nous savons exactement à quoi ressemblait la personne à l'époque de la photo, ce que nous ne savons pas. Nous nous basons sur notre connaissance des humains et de leur apparence habituelle pour faire des suppositions sur l'image floue et créer des centaines de nouveaux pixels se rapprochant le plus possible de la réalité, sans jamais la représenter à la perfection.


L'image résultante ressemblera à notre grand-père si nous avons de la chance. Mais cela peut tout aussi bien ressembler à un parfait inconnu, et vous devez en tenir compte lorsque vous utilisez ce type de modèles. Malgré tout, les résultats de ce modèle sont fantastiques et remarquablement proches de la réalité. Je vous invite fortement à l’essayer et créer votre propre idée du modèle et des résultats. Le lien vers leur code, leur démo et leurs applications se trouve dans les références ci-dessous.
Dites-moi ce que vous en pensez, et j'espère que cet article vous a plu !
Avant de partir, si l'éthique de l'IA vous intéresse ; J'enverrai la prochaine itération de notre newsletter (en anglais) avec le point de vue de Martina sur les considérations éthiques de cette technique dans les jours suivants.
Références
La vidéo: https://youtu.be/nLDVtzcSeqM
PULSE: https://youtu.be/cgakyOI9r8M
Wang, X., Li, Y., Zhang, H. and Shan, Y., 2021. Towards real-world blind face restoration with generative facial prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9168–9178), https://arxiv.org/pdf/2101.04061.pdf
Utilisez le modèle: https://app.baseten.co/applications/Q04Lz0d/operator_views/8qZG6Bg