Comment Uber utilise l'IA pour mieux vous servir
Comment Uber peut-il livrer de la nourriture et arriver toujours à l'heure ou quelques minutes avant ? Comment font-ils correspondre les passagers aux chauffeurs pour que vous puissiez *toujours* trouver un Uber ? Tout cela en gérant également tous les conducteurs.
Nous répondrons à ces questions dans cette vidéo avec leur algorithme de prédiction de l'heure d'arrivée : DeepETA. DeepETA est l'algorithme le plus avancé d'Uber pour estimer les heures d'arrivée à l'aide de l'apprentissage profont (deep learning). Utilisé à la fois pour Uber et Uber Eats, DeepETA peut tout organiser comme par magie en arrière-plan afin que les passagers, les chauffeurs et la nourriture se déplacent couramment du point a au point b aussi efficacement que possible.
De nombreux algorithmes différents existent pour estimer les déplacements sur ces réseaux routiers, mais je ne pense pas qu'aucun soit aussi optimisé que celui d'Uber. Les précédents outils de prédiction de l'heure d'arrivée ont été construits avec ce que nous appelons des algorithmes de chemin le plus court, qui ne sont pas bien adaptés aux prédictions du monde réel, car ils ne prennent pas en compte les signaux en temps réel.

Pendant plusieurs années, Uber a utilisé XGBoost, une célèbre bibliothèque d'apprentissage automatique d'arbres de décision boostés par gradient. XGBoost est extrêmement puissant et utilisé dans de nombreuses applications, mais était limité dans le cas d'Uber, car plus il grandissait, plus il y avait de latence. Uber voulait quelque chose de plus rapide, plus précis et plus général à utiliser pour les chauffeurs, les passagers et la livraison de nourriture. Tous des défis orthogonaux complexes à résoudre, même pour le machine learning ou l'IA.
Voici DeepETA. Un modèle d'apprentissage profond qui est plus puissant que XGBoost pour tous ces points.
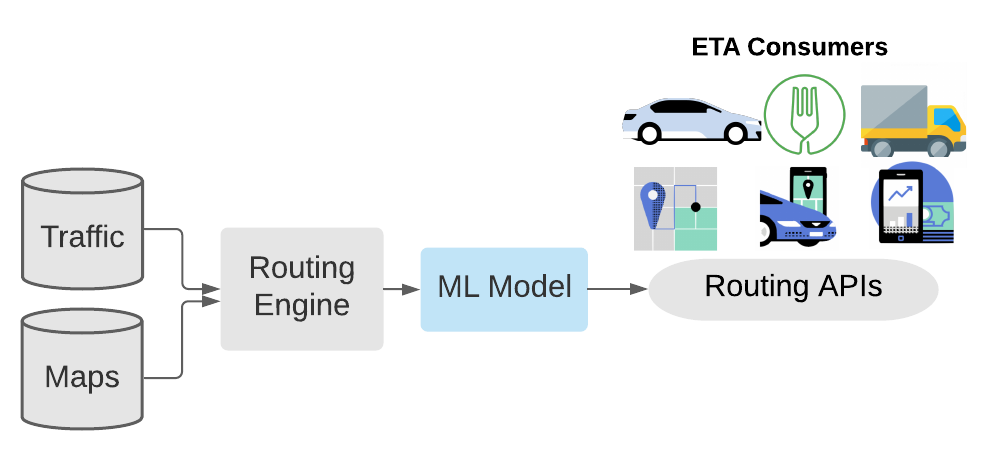
Approche hybride du post-traitement ETA à l'aide du modèle DeepETA (ML Model dans l’image). Image tirée du blog d'Uber.
DeepETA est vraiment puissant et efficace, car il ne se contente pas de prendre des données et de générer une prédiction. Il existe tout un système de prétraitement pour rendre ces données plus digestes pour le modèle. Cela facilite grandement la tâche du modèle, car il peut se concentrer directement sur des données optimisées avec beaucoup moins de bruit et des entrées beaucoup plus petites, une première étape dans l'optimisation des problèmes de latence.
Ce module de prétraitement commence par prendre des données cartographiques et des mesures de trafic en temps réel pour produire une première estimation de l'heure d'arrivée pour toute nouvelle demande client.
Ensuite, le modèle prend en compte ces caractéristiques transformées avec l'origine et la destination spatiales et l'heure de la demande en tant que caractéristique temporelle. Mais cela ne s'arrête pas là. Il prend également plus d'informations sur les activités en temps réel comme le trafic, la météo ou même la nature de la demande, comme la livraison ou un ramassage en covoiturage. Toutes ces informations supplémentaires sont nécessaires pour améliorer les algorithmes de chemin le plus court que nous avons mentionnés qui sont très efficaces, mais loin d'être une preuve intelligente ou applicables au monde réel.
Et qu'est-ce que ce modèle utilise comme architecture ?
Vous l'avez deviné : un transformeur ! Êtes-vous surpris? Je ne le suis certainement pas.
Et cela répond directement au premier défi, qui était de rendre le modèle plus précis que XGBoost. J'ai déjà couvert de nombreuses fois les transformeurs sur ma chaîne, je n'entrerai donc pas dans le détail de leur fonctionnement dans cet article, mais je voulais tout de même souligner quelques fonctionnalités spécifiques pour Uber. Tout d'abord, vous devez penser « mais les transformeurs sont des modèles énormes et lents ; comment peut-il avoir une latence inférieure à XGBoost ?!"
Eh bien, vous auriez raison. Ils l'ont essayé, et c'était trop lent, alors ils ont fait quelques changements.
Le changement avec le plus grand impact a été d'utiliser un transformeur linéaire, qui s'adapte à la dimension de l'entrée au lieu de la taille de l'entrée. Cela signifie que si l'entrée est longue, les transformeurs seront extrêmement lents, et c'est souvent le cas pour eux avec autant d'informations et de données de routes. Au lieu de cela, le transformeur linéaire est plutôt limité par les dimensions d’un élément d’entrée, quelque chose qu'ils peuvent contrôler et qui est beaucoup plus petit.
Une autre grande amélioration de la vitesse est la discrétisation des entrées. Cela signifie qu'ils prennent des valeurs continues et les rendent beaucoup plus faciles à calculer en regroupant des valeurs similaires. La discrétisation est régulièrement utilisée en production pour accélérer le calcul, car la vitesse qu'elle donne l'emporte clairement sur l'erreur que les valeurs dupliquées peuvent entraîner.

Maintenant, il ne reste plus qu'un défi à relever, et de loin, le plus intéressant est de savoir comment ils l'ont rendu plus général.
Voici le modèle DeepETA complet pour répondre à cette question:

Illustration de la structure du modèle DeepETA. Image tirée du blog d'Uber.
On peut retrouver la quantification des données qui sont ensuite intégrées et envoyées au transformeur linéaire dont nous venons de parler. Ensuite, nous avons la couche entièrement connectée pour faire notre prédiction, et nous ajoutons une dernière étape pour rendre notre modèle général : le décodeur d'ajustement de biais.
Il lui faudra les prédictions et les « caractéristiques de type » que nous avons mentionnées au début de l’article contenant la raison pour laquelle le client a fait une demande à Uber pour orienter la prédiction vers une valeur plus appropriée pour la tâche. Ils réentraînent et déploient périodiquement leur modèle en utilisant leur propre plate-forme appelée Michelangelo, que j'aimerais couvrir ensuite si vous êtes intéressé. Si oui, merci de me le faire savoir dans les commentaires de la vidéo ou par DM/email !
Et voilà !
C'est ce qu'Uber utilise actuellement dans son système pour livrer et proposer des trajets à tout le monde aussi efficacement que possible !
Bien sûr, ce n'était qu'un aperçu, et ils ont utilisé plus de techniques pour améliorer l'architecture, que vous pouvez découvrir dans leur excellent article de blog lié ci-dessous si vous êtes curieux. Je voulais aussi juste noter qu'il ne s'agissait que d'un aperçu de leur algorithme de prédiction de l'heure d'arrivée, et que je ne suis en aucun cas affilié à Uber.
J'espère que vous avez apprécié l’article de cette semaine couvrant un modèle appliqué au monde réel au lieu d'un nouvel article de recherche, et si c'est le cas, n'hésitez pas à suggérer des applications ou des outils intéressants à couvrir ensuite. J'adorerais lire vos idées!
Merci d'avoir lu, et on se revoit la semaine prochaine avec un autre article incroyable!
Regardez la vidéo sous-titrée en français
Références:
►Blogue de Uber: https://eng.uber.com/deepeta-how-uber-predicts-arrival-times/
►Que sont les transformeurs: https://youtu.be/sMCHC7XFynM
►Transformeurs linéaires: https://arxiv.org/pdf/2006.16236.pdf
►Ma Newsletter (anglais): https://www.louisbouchard.ai/newsletter/