Le nouveau modèle de Meta (OPT) est un GPT-3 open source !
Nous avons tous entendu parler de GPT-3 et avons une idée relativement précise de ses capacités. Vous avez très certainement vu des applications nées strictement grâce à ce modèle, dont certaines que j'ai couvertes dans une vidéo précédente sur le modèle. GPT-3 est un modèle développé par OpenAI auquel vous pouvez accéder via une API payante, mais n'avez pas au modèle lui-même.
Ce qui rend GPT-3 si fort, c'est à la fois son architecture et sa taille. Il contient 175 milliards de paramètres. Ce qui est deux fois plus que le nombre de neurones que nous avons dans notre cerveau !

Cet immense réseau a été à peu près formé sur l'ensemble d'Internet pour comprendre comment nous écrivons, échangeons et comprenons le texte. Cette semaine, Meta (Facebook) a fait un grand pas en avant pour la communauté en publiant un modèle tout aussi puissant, sinon plus et qui l'a rendu publiquement accessible.
Nous pouvons maintenant avoir accès à un modèle similaire à GPT-3 et jouer avec lui directement sans passer par une API payant et un accès limité. Ce modèle récent de Meta, OPT, qui signifie Transformers pré-entraînés open source, est disponible en plusieurs tailles avec des poids pré-entraînés pour directement l’implémenter ou l’utiliser dans nos recherches. C'est une nouvelle super cool pour le domaine et surtout pour les chercheurs académiques.
OPT, ou plus précisément OPT-175B, est très similaire à GPT-3, donc je recommande fortement de regarder ma vidéo pour mieux comprendre les grands modèles de langue (“large language models”). GPT-3 et OPT ne peuvent pas seulement résumer vos e-mails ou écrire un essai rapide basé sur un sujet. Il peut également résoudre des problèmes mathématiques de base, répondre aux questions, écrire du code, etc.
La principale différence avec GPT-3 est que celui-ci est open-source, ce qui signifie que vous avez accès à son code et même à des modèles pré-entraînés avec lesquels vous pouvez implémenter directement, sans entraînement nécéssaire. Un autre fait important est que l’entraînement d’OPT a utilisé 1/7e de l'empreinte carbone comme GPT-3, ce qui est un autre pas dans la bonne direction. Vous pouvez dire que ce nouveau modèle est très similaire à GPT-3, mais open-source et meilleur pour l’environnement!
Donc, un modèle de langage utilisant des transformeurs, que j'ai déjà couvert dans des vidéos et articles précédentes, qui a été entraîné sur de nombreux ensembles de données différents, on pourrait dire sur tout Internet, pour traiter du texte et générer encore plus de texte. Pour mieux comprendre leur fonctionnement, je vous renvoie encore une fois à la vidéo que j'ai réalisée sur GPT-3, car ce sont des modèles très similaires.
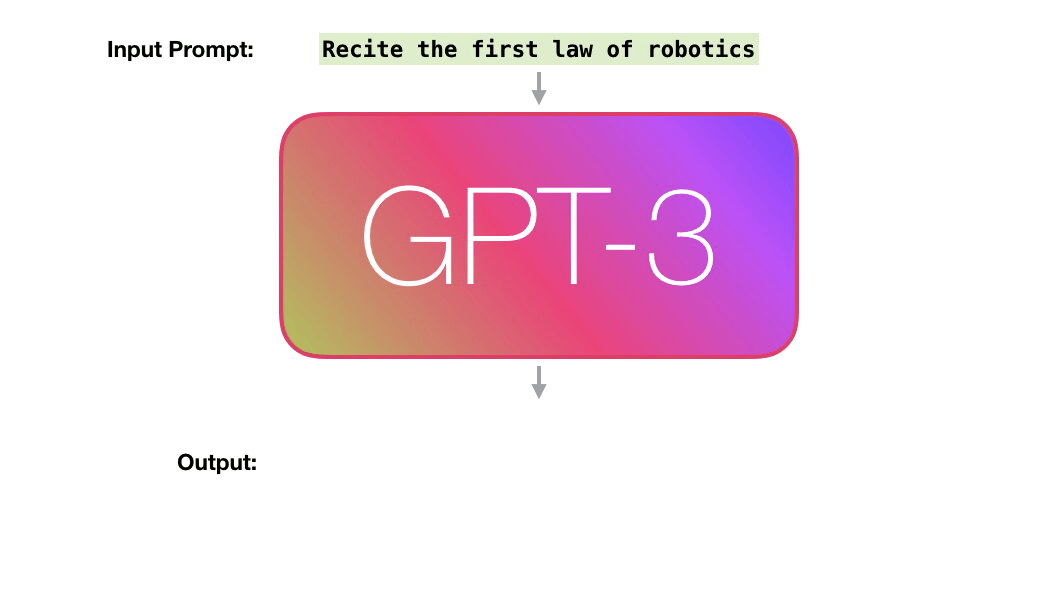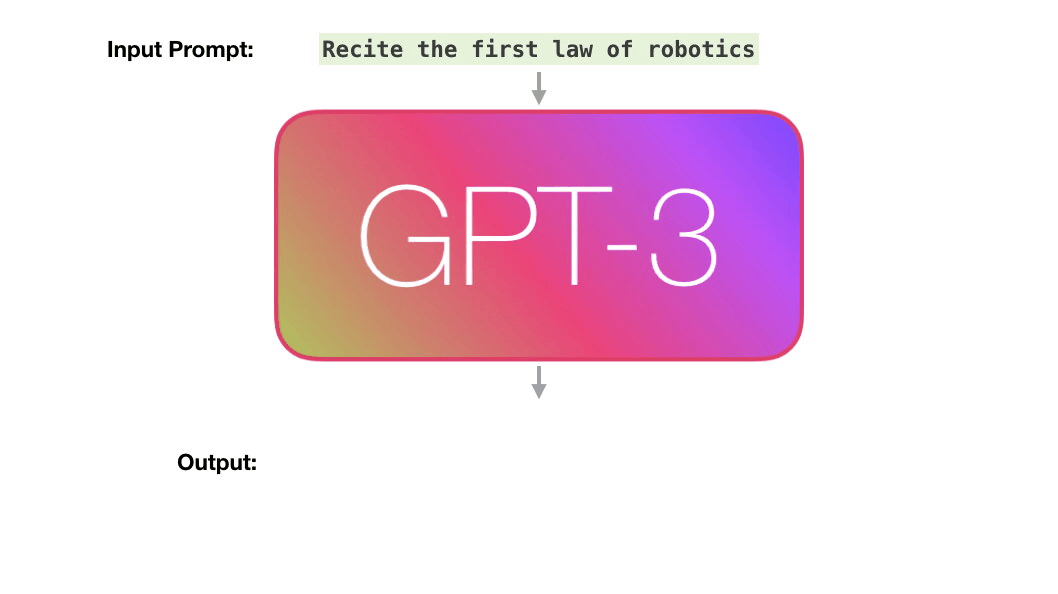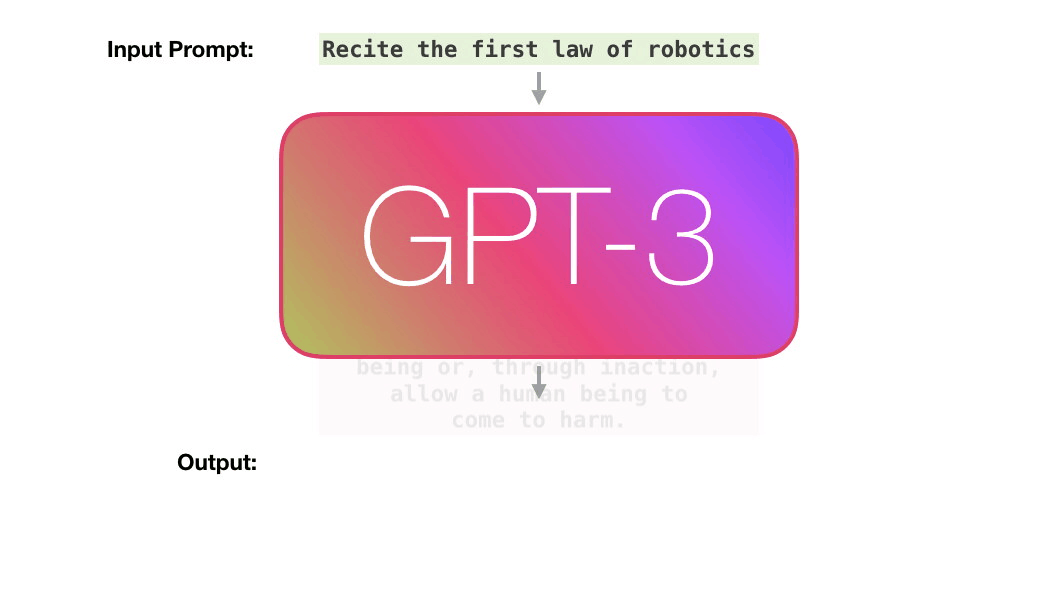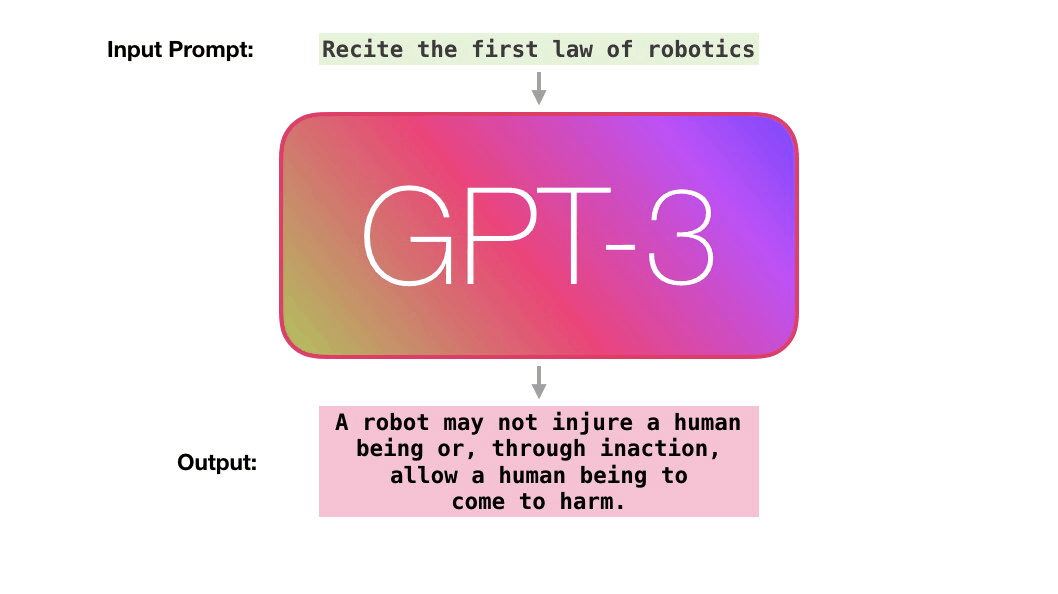
Vidéo par Jay Alammar. “How GPT3 Works - Visualizations and Animations”
Ici, ce que je voulais vraiment couvrir, c'est l'effort de Meta pour rendre ce type de modèle accessible à tout le monde tout en mettant beaucoup d'efforts pour partager ses limites, biais et risques. Par exemple, ils ont vu qu’OPT a tendance à être répétitif et à rester coincé dans une boucle, ce qui nous arrive rarement; sinon, personne ne vous parlera. Comme il a été entraîné sur Internet, ils ont également constaté qu’OPT a une forte propension pour générer un langage toxique et renforcer les stéréotypes nocifs. Reproduisant fondamentalement nos comportements et biais généraux. Il peut également produire des faits incorrectes, ce qui n'est pas souhaitable si vous voulez que les gens vous prennent au sérieux. Ces limitations sont quelques-unes des raisons les plus importantes pourquoi ces modèles ne remplaceront pas les humains de si tôt pour des emplois de prise de décision importants ou même seront utilisés en toute sécurité dans des produits commerciaux.
Je vous invite à lire leur papier de recherche comportant leur analyse approfondie de la capacité du modèle et vous aidera à mieux comprendre leurs efforts pour rendre ce modèle plus respectueux de l'environnement et sûr à utiliser. Vous pouvez également en savoir plus sur leur processus d’entraînement et l'essayer vous-même avec le code accessible au public! Tous les liens sont dans les références ci-dessous.
De telles contributions open source avec de nouveaux modèles, documents et code disponibles sont vraiment importants pour que la communauté de recherche avance l’état de l’art, et je suis heureux qu'une grande entreprise comme Meta le fasse. Grâce à eux, les chercheurs du monde entier pourront expérimenter avec des modèles de langue de pointe au lieu de petites versions. Je suis ravi de voir tous les progrès à venir que cela engendrera.
J'espère que vous avez apprécié l'article de cette semaine qui était un peu différent de l'habitude, couvrant cette super nouvelle et les efforts essentiels de Meta pour partager des recherches accessibles au public.
Merci d’avoir lu et je vous verrai la semaine prochaine avec un autre papier incroyable!
Regardez la vidéo sous-titrée en français!
Références
►La vidéo sur OPT: https://www.youtube.com/watch?v=Ejg0OunCi9U
►Zhang, Susan et al. “OPT: Open Pre-trained Transformer Language Models.” https://arxiv.org/abs/2205.01068
►Ma vidéo sur GPT-3: https://youtu.be/gDDnTZchKec
►Blogue de Meta: https://ai.facebook.com/blog/democratizing-access-to-large-scale-language-models-with-opt-175b/
►Code: https://github.com/facebookresearch/metaseq https://github.com/facebookresearch/metaseq/tree/main/projects/OPT
►Ma Newsletter (en anglais): https://www.louisbouchard.ai/newsletter/