Manipulez des images avec des blobs ! BlobGAN expliqué
Si vous pensiez que les progrès avec les GAN étaient terminés, vous ne pouviez pas vous tromper davantage. Voici BlobGAN, et ce nouveau modèle est tout simplement incroyable.

Exemples BlobGAN de déplacement de tous les objets à la fois. Image de la page du projet des auteurs.
BlobGAN permet une manipulation sur-réelle des objets d’une image en les contrôlant très facilement de simples blobs. Toutes ces petits blobs représentent un objet, et vous pouvez les déplacer ou les agrandir, les réduire ou même les supprimer, et cela aura le même effet sur l'objet qu'il représente dans l'image.
Comme les auteurs ont partagé dans leurs résultats, vous pouvez même créer de nouvelles images en dupliquant des blobs, créant des images non-existantes dans l'ensemble de données d’entraînement, comme une pièce avec deux ventilateurs de plafond ! Corrigez-moi si je me trompe, mais je pense que c'est l'un des premier, sinon le premier, article à rendre la modification des images aussi simple que de déplacer des blobs et de permettre des modifications qui n'étaient pas présentes dans l'ensemble de données d'entraînement.
Et vous pouvez réellement jouer avec ce modèle contrairement à certaines entreprises que nous connaissons ! Ils ont partagé leur code publiquement et ont créé une démo Google Colab que vous pouvez essayer immédiatement. Encore plus excitant est le fonctionnement de BlobGAN, dans lequel nous plongerons dans quelques secondes.
Regardez des résultats dans la vidéo sous-titrée en français!
Maintenant que vous avez vu quelques résultats dans la vidéo ou simplement le gif ci-dessus, revenons à notre article, BlobGAN : “Spatially Disentangled Scene Representations”. Le titre dit tout, BlobGAN utilise des blobs pour démêler des objets dans une scène.
Cela signifie que le modèle apprend à associer chaque blob à un objet spécifique de la scène, comme un lit, une fenêtre ou un ventilateur de plafond. Une fois entraîné, vous pouvez déplacer les blobs et les objets individuellement, les agrandir ou les réduire, les dupliquer ou même les supprimer de l'image. Bien sûr, les résultats ne sont pas entièrement réalistes, mais comme dirait une personne formidable, “imaginez le potentiel de cette approche deux autres articles plus tard”.
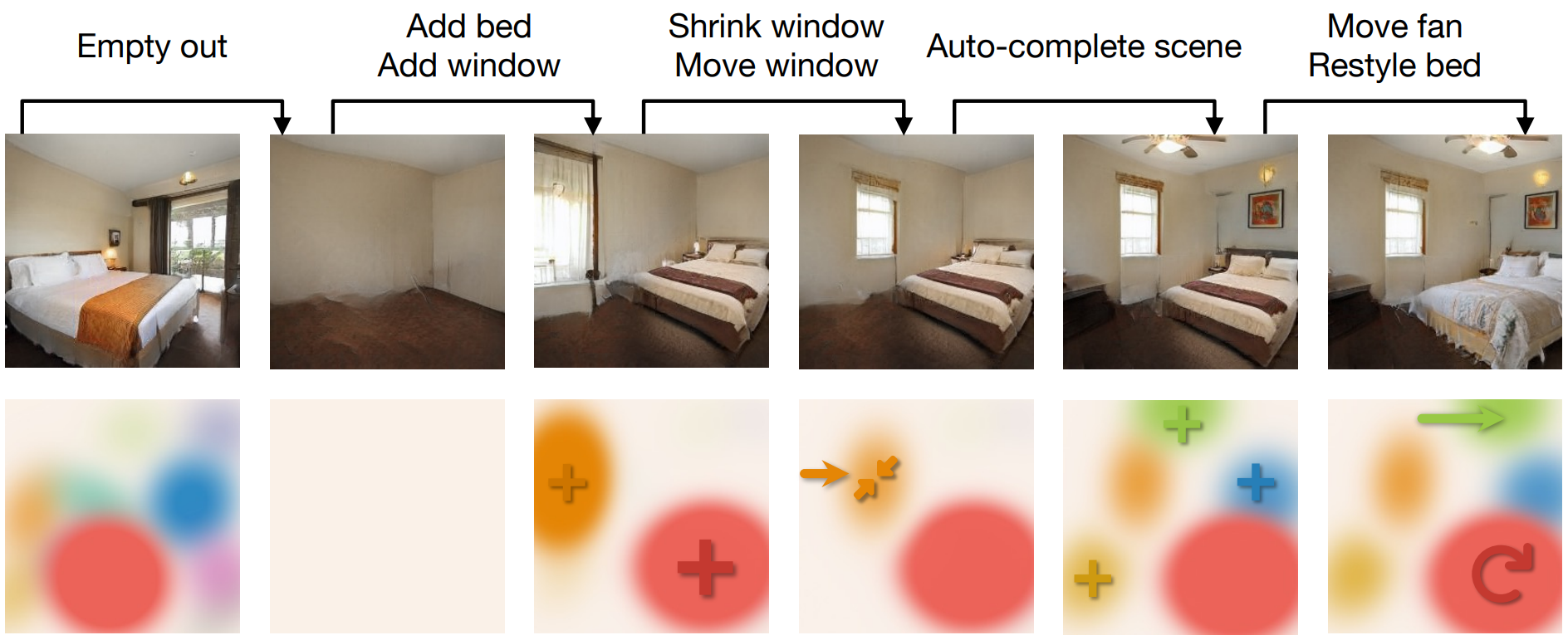
Les blobs. Image tirée de l'article des auteurs.
Ce qui est encore plus cool, c'est que cet entraînement se déroule d’une manière non supervisée. Cela signifie que vous n'avez pas besoin d’avoir des exemples d'images pour chaque cas possible lors de l’entraînement, comme vous le feriez dans un entraînement supervisé. Un exemple rapide est que l’apprentissage supervisé nécessiterait que vous disposiez de toutes les manipulations souhaitées dans votre jeu de données d'image pour apprendre aux blobs à apprendre ces transformations. Alors que dans l'apprentissage non supervisé, vous n'avez pas besoin de toutes ces données. Le modèle apprendra à accomplir cette tâche par lui-même, en associant des blobs à des objets par lui-même sans étiquettes explicites.
Nous entraînons le modèle avec un générateur et un discriminateur à la manière d'un GAN. Je vais simplement faire un bref aperçu ici, car j'ai couvert les GANs dans de nombreuses vidéos. Comme toujours dans les GANs, la responsabilité du discriminateur est de former le générateur pour créer des images réalistes. La partie la plus importante de l'architecture est le générateur avec nos blobs et un décodeur de type StyleGAN2. J'ai également couvert les générateurs basés sur StyleGAN dans d'autres vidéos si vous êtes curieux de savoir comment cela fonctionne.
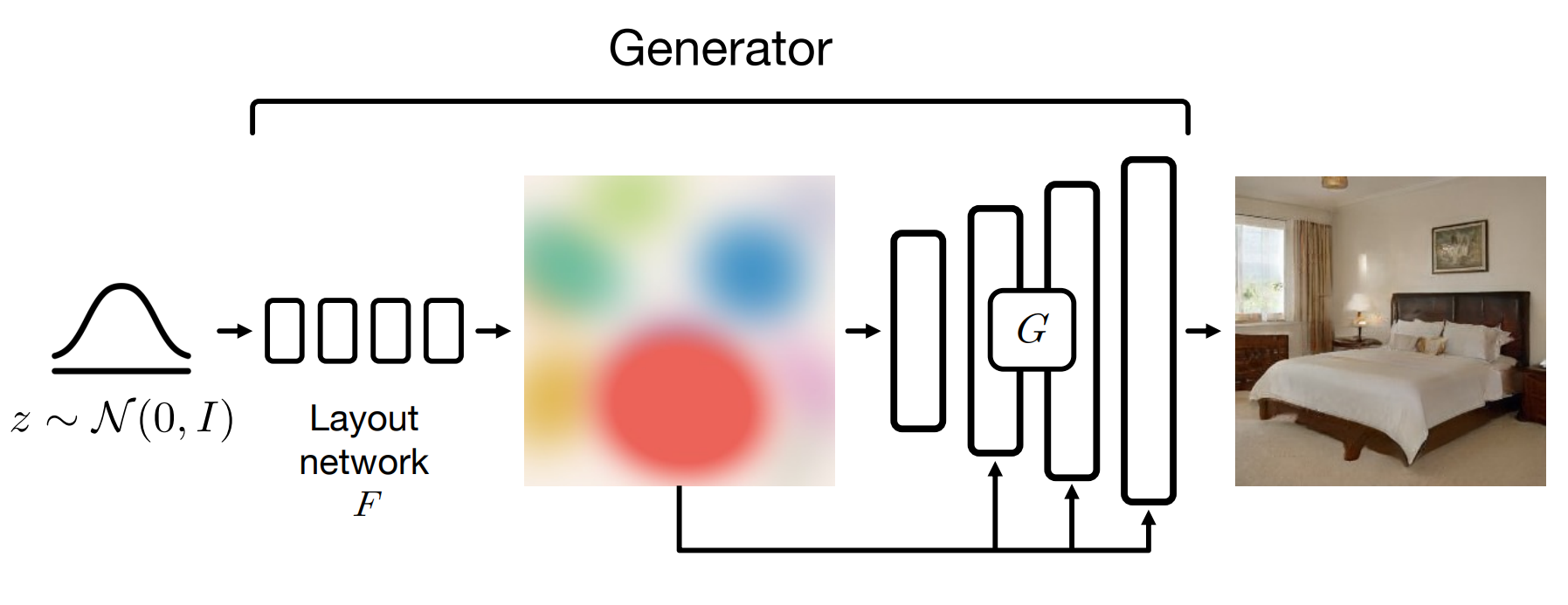
Visualisation du modèle BlogGAN. Image tirée de l'article des auteurs.
Mais, en bref, nous créons d'abord nos blobs. Cela se fait en prenant un bruit aléatoire, comme dans la plupart des réseaux de générateurs, et en le représentant en blobs à l'aide d'un premier réseau de neurones. Cela sera appris lors de la formation. Ensuite, vous devez faire l'impossible : prendre cette représentation de blob et en faire une véritable image ? ! C'est là que la magie du GAN se produit.
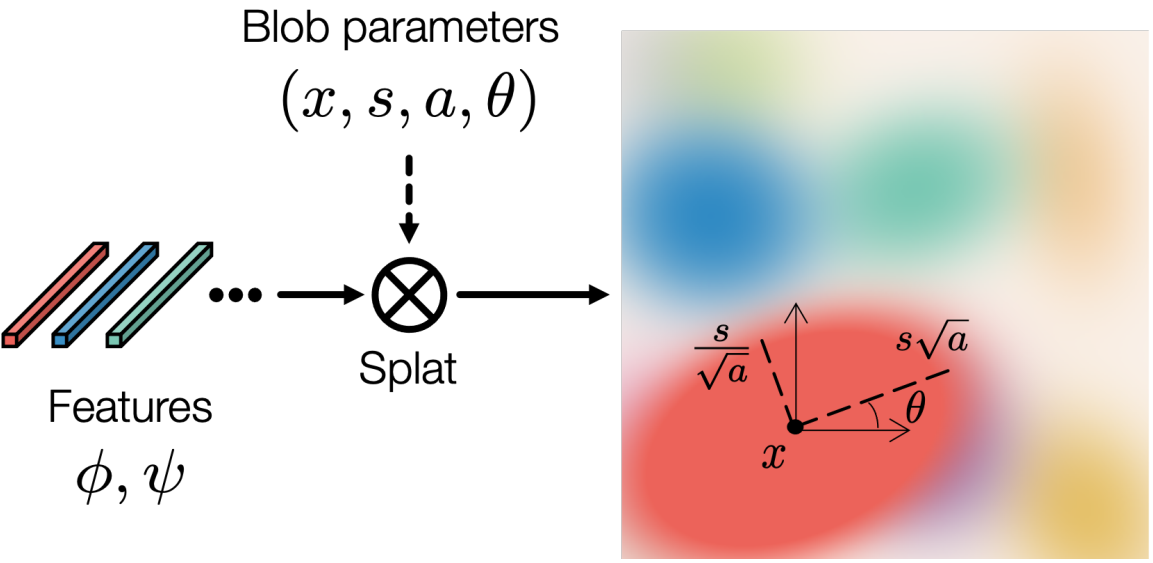
Visualisation de la génération Blob. Image tirée de l'article des auteurs.
Nous avons besoin d'une architecture de type StyleGAN pour créer nos images à partir de ces blobs. Bien sûr, nous modifions l'architecture pour prendre les blobs que nous venons de créer comme entrées au lieu du bruit aléatoire habituel. Ensuite, nous entraînons notre modèle à l'aide du discriminateur pour apprendre à générer des images réalistes. Une fois que nous avons de bons résultats, cela signifie que notre modèle peut prendre la représentation du blob au lieu du bruit et générer des images.
Mais nous avons encore un problème. Comment pouvons-nous démêler ces blobs et les faire correspondre à des objets ?
Eh bien, c'est la beauté de notre approche non supervisée. Le modèle s'améliorera de manière itérative et créera des résultats réalistes tout en apprenant à représenter ces images sous la forme d'un nombre fixe de blobs.
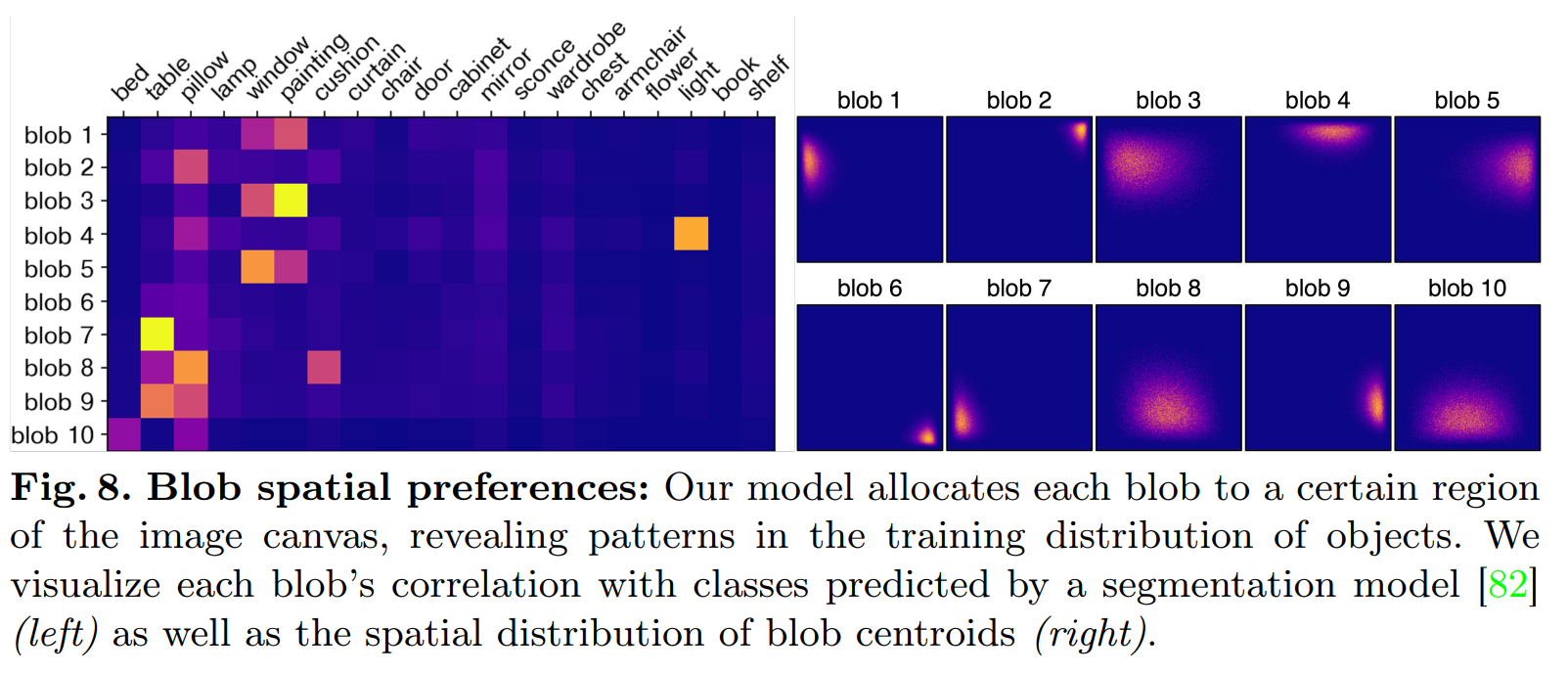
Image tirée de l'article des auteurs.
Vous pouvez voir ci-dessus comment les blobs sont souvent utilisés pour représenter les mêmes objets ou des objets très similaires dans la scène. Vous voyez comment les mêmes blobs sont utilisées pour représenter une fenêtre ou une peinture, ce qui a beaucoup de sens. De même, vous pouvez voir que la lumière est presque toujours représentée par le quatrième blob. Vous pouvez également voir sur la droite comment les blobs représentent souvent les mêmes régions de la scène, très certainement en raison de similitudes d'images dans l'ensemble de données utilisé pour cette expérience.
Et voilà !
C'est ainsi que BlobGAN apprend à manipuler des scènes en utilisant une représentation sous forme de blobs très intuitive ! Je suis très impressionné par le réalisme des résultats et excité de suivre les améliorations, en gardant une approche similaire. En utilisant une telle technique, nous pourrions concevoir des applications interactives simples pour permettre aux concepteurs ou à quiconque de manipuler facilement des images, ce qui est assez prometteur.
Bien sûr, ce n'était qu'un aperçu de ce nouvel article, et je vous recommande fortement de lire leur article pour une meilleure compréhension et beaucoup plus de détails sur l'approche, la mise en œuvre et les tests qu'ils ont effectués.
Comme je l'ai dit plus tôt dans l'article, ils ont également partagé leur code publiquement et une démo sur Google Colab que vous pouvez essayer immédiatement. Tous les liens sont dans les références ci-dessous.
Merci d'avoir lu jusqu'à la fin, et je vous verrai la semaine prochaine avec un autre article incroyable ! N'hésitez pas à commenter sous ma vidéo ou rejoindre notre communauté sur Discord et partagez vos projets là-bas, ça s'appelle “Learn AI Together” et j'aimerais vous rencontrer là-bas !
Références
►Regardez la vidéo sous-titrée en français: https://youtu.be/mnEzjpiA_4E
►Epstein, D., Park, T., Zhang, R., Shechtman, E. and Efros, A.A., 2022. BlobGAN: Spatially Disentangled Scene Representations. arXiv preprint arXiv:2205.02837.
►Lien vers le projet: https://dave.ml/blobgan/
►Code: https://github.com/dave-epstein/blobgan
►Démo Google Colab : https://colab.research.google.com/drive/1clvh28Yds5CvKsYYENGLS3iIIrlZK4xO?usp=sharing#scrollTo=0QuVIyVplOKu
►Ma Newsletter (en anglais): https://www.louisbouchard.ai/newsletter/