Méthodes Avancées de Recherche RAG (Hybride, Embedding, Filtrage et plus...)
Regardez la vidéo!
Comment est-ce qu’on améliore la recherche d’information dans les applications augmentées par récupérations comme le RAG? C’est ce qu’on répond dans ce blogue en couvrant tout, des recherches par mots-clés traditionnelles aux méthodes plus récentes comme GraphRAG. À la fin, vous saurez exactement comment faire fonctionner vos données dans votre système RAG et quelles technique utilisé dans chaque cas.
Recherche par Mots-Clés Traditionnelle
Commençons simplement avec la recherche par mots-clés.
La recherche par mots-clés trouve des correspondances exactes ou proches avec les termes recherchés. C’est parfait quand on sait exactement ce qu’on cherche. Si c’est dans les données, on le trouvera.
Par exemple, si on cherche des politiques d’entreprise sur "l’éthique de l’IA", la recherche par mots-clés trouvera des documents contenant exactement ces mots.
Deux algorithmes populaires pour la recherche par mots-clés sont BM25 et BM42 :
BM25, ou "Best Matching 25", est une fonction de classement utilisée dans la recherche d’informations. C’est un système de scoring pour la recherche par mots-clés.
D’abord, il examine la fréquence d’apparition d’un mot dans un document (fréquence du terme, ou TF). Ensuite, il donne plus de poids aux mots rares dans l’ensemble des documents (fréquence inverse des documents, ou IDF). Il évite aussi que les documents plus longs ne soient automatiquement mieux notés simplement parce qu’ils contiennent plus de mots. Enfin, il s’assure que même si un mot apparaît beaucoup, il ne devient pas soudainement beaucoup plus important grâce à une fonction de saturation intelligente. Cette fonction limite l’impact des mots très fréquents, garantissant qu’un mot apparaissant 100 fois n’a pas 10 fois plus de poids qu’un mot apparaissant 10 fois.
BM42 est une évolution de BM25, conçue pour gérer des documents plus longs et des requêtes plus complexes. Il améliore la fonction de saturation pour mieux traiter les documents volumineux, prend en compte les termes de requête absents d’un document en évaluant le contexte général, et intègre une meilleure normalisation pour la longueur des documents.
Ces deux méthodes rendent la recherche par mots-clés plus nuancée et efficace, au-delà d’un simple comptage de mots.
En général, la recherche par mots-clés est idéale pour des résultats rapides et précis. Mais elle a ses limites : si les mots ne correspondent pas exactement, on risque de passer à côté d’idées connexes. Par exemple, un texte parlant d’"éthique de l’IA" comme "considérations éthiques dans l’apprentissage automatique" ne sera pas trouvé par une recherche par mots-clés. C’est là qu’une approche plus intelligente entre en jeu.
Recherche par Embeddings
L’idéal serait une recherche qui comprend ce qu’on veut dire, pas juste les mots qu’on utilise.
C’est ce que fait la recherche par vecteurs.
La recherche par vecteurs, ou recherche sémantique, transforme la requête (comme "éthique de l’IA") et les documents en vecteurs de haute dimension, appelés embeddings. Ces embeddings ne se limitent pas à représenter les mots : grâce à l’entraînement des modèles, ils capturent le sens sémantique des textes. On peut les voir comme une liste de caractéristiques avec une valeur pour chacune, indiquant, par exemple, si c’est un objet, sa couleur, sa forme, etc.
La recherche calcule ensuite la similarité entre le vecteur d’embedding de la requête et ceux des documents. On utilise souvent la similarité cosinus, qui compare chaque valeur du vecteur de la requête à celles des vecteurs des documents. Cela permet au système de trouver des documents pertinents basés sur une similarité conceptuelle, même si les mots-clés exacts ne correspondent pas. Cela demande plus de ressources informatiques et des modèles sophistiqués.
On utilise la recherche par embeddings quand on cherche des idées similaires exprimées différemment. Par exemple, elle peut trouver des articles sur "éthique de l’IA" même si quelqu’un écrit "étique de l’intelligence artificielle" en français, car elle comprend que les deux ont un sens proche.
Recherche Hybride : Le Meilleur des Deux
Mais nous n’avons pas besoin de choisir entre les mots-clés et les embeddings. Nous pouvons tout simplement utiliser les deux ! C’est ce que fait la recherche hybride. Elle combine la précision des mots-clés avec la signification capturée par les embeddings.
Elle peut tirer parti à la fois de ce que vous dites et de ce que vous voulez dire.
La recherche hybride est parfaite lorsque vous avez besoin à la fois de correspondances exactes et de contenus connexes. Elle est idéale pour des données mixtes et lorsque vous souhaitez équilibrer le fait de trouver tout ce qui est pertinent (ce qui peut représenter beaucoup d’informations) avec le fait de trouver les informations les plus pertinentes, comme les trois meilleures.
Par exemple, dans le shopping en ligne, la recherche hybride peut aider les clients à trouver des produits même s’ils ne connaissent pas le nom exact. En même temps, elle peut toujours trouver des correspondances exactes pour les codes produits. De même, pour notre exemple sur « l’éthique de l’IA », si l’utilisateur tape quelque chose comme « considérations éthiques des véhicules autonomes », vous trouverez exactement les informations sur les véhicules autonomes, mais vous serez également capable de trouver des préoccupations plus générales liées à l’IA et aux véhicules qui pourraient être pertinentes. Bien équilibrée, c’est le meilleur des deux mondes.
GraphRAG : Connecter les idées
Passons maintenant à un niveau supérieur avec GraphRAG, une nouvelle méthode popularisée par Microsoft. Ce n’est pas seulement une question de trouver des informations ; il s’agit de comprendre comment elles sont toutes connectées.
GraphRAG utilise les relations entre les objets ou les personnes, que nous appelons graphes de connaissances. Au lieu de simplement trouver des documents pertinents, il discerne leurs relations, extrait les entités et les relations, et crée une représentation structurée qui capture les connexions sémantiques des données.
Pour que nous soyons sur la même longueur d’onde, un graphe de connaissances est simplement une représentation structurée des données qui capture les entités et leurs relations, permettant une meilleure compréhension et récupération des informations.
Nous utilisons GraphRAG lorsque les données ont des connexions complexes. Il est idéal pour répondre à des questions difficiles impliquant plusieurs morceaux d’informations. Pensez à la recherche juridique, où vous devez comprendre comment différents cas et lois sont connectés.
Mais attention : GraphRAG est puissant, mais lent. Actuellement, il peut prendre jusqu’à 10 fois plus de temps que des méthodes plus simples, comme l’a mesuré un récent Blog Post de Microsoft. Assurez-vous d’en avoir réellement besoin avant de l’utiliser !
Filtrage par métadonnées : utiliser des informations supplémentaires
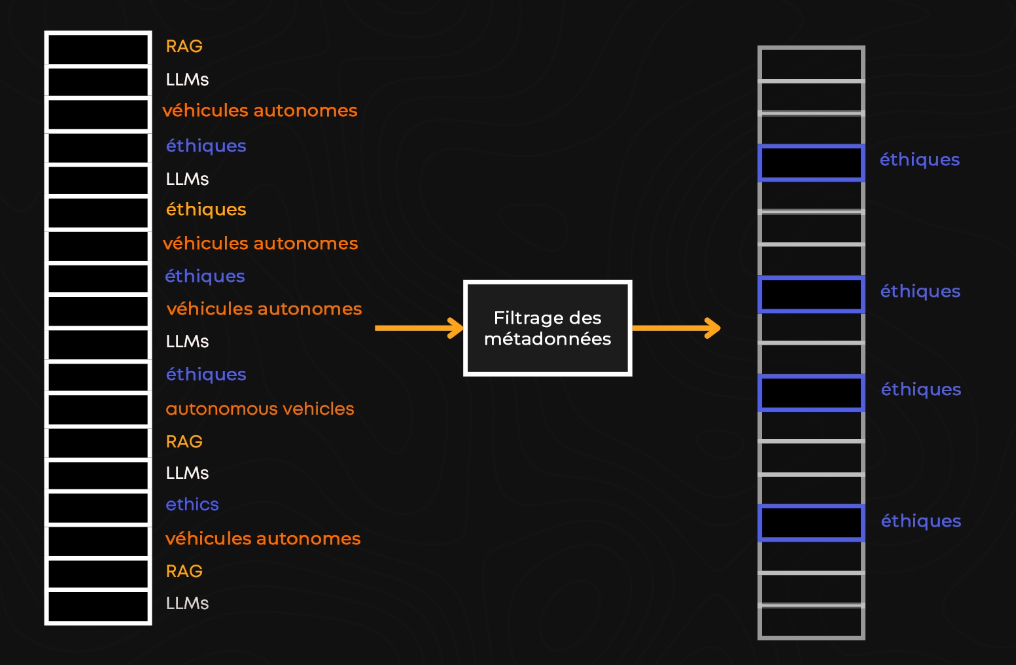
Parfois, la clé pour trouver ce dont vous avez besoin ne se trouve pas dans le texte principal, mais dans les informations supplémentaires à son sujet. C’est ce qu’on appelle le filtrage par métadonnées.
Le filtrage par métadonnées vous permet de restreindre votre recherche en utilisant des éléments comme les dates, les auteurs ou les types de fichiers. C’est essentiellement une question d’utilisation d’étiquettes pour organiser vos fichiers.
Utilisez le filtrage par métadonnées lorsque vous devez rechercher dans des limites spécifiques. C’est idéal lorsque vos données ont des étiquettes claires ou lorsque vous souhaitez donner aux utilisateurs plus de contrôle sur leur recherche.
Par exemple, si nous avons un large ensemble de données sur l’IA en général, avec de nombreux tags pour chaque texte, comme RAG, LLMs, véhicules autonomes ou éthique, nous pourrions directement obtenir tous les textes liés à l’éthique sans une recherche lourde. Il suffirait d’appliquer un filtre, et c’est tout. Nous pourrions ensuite effectuer une recherche avec les embeddings sur cette partie filtrée pour trouver les informations les plus pertinentes.
Le Routeur : le directeur de circulation de vos recherches
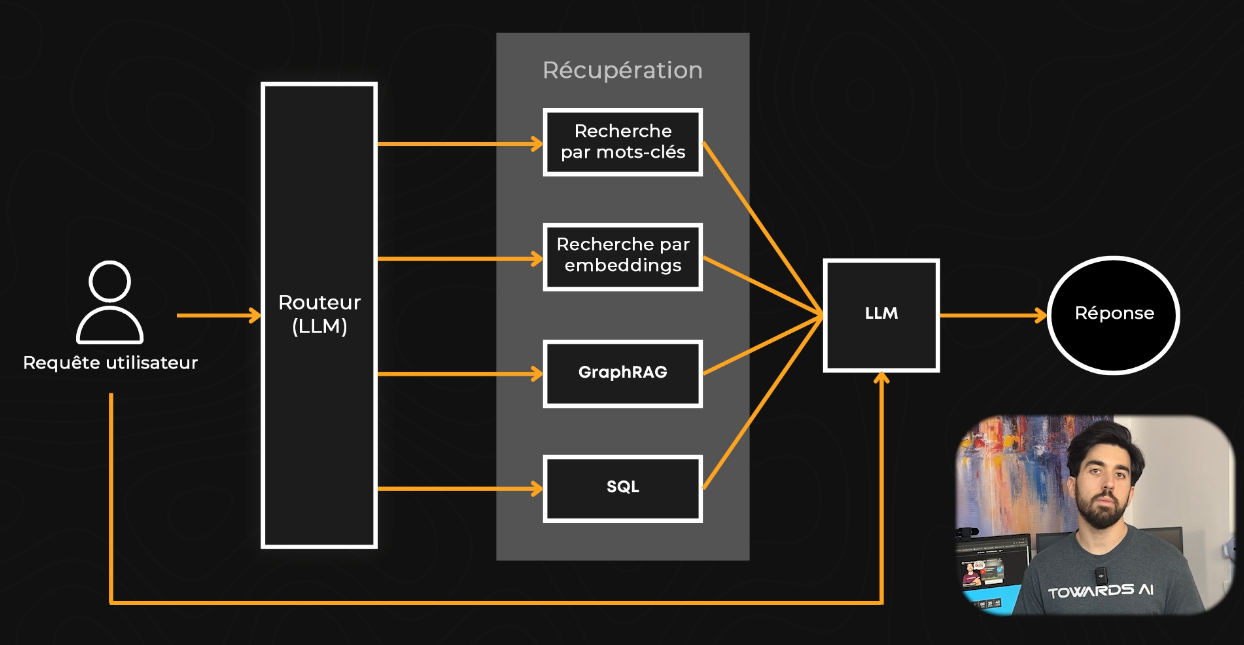
Mais alors, avec toutes ces techniques de recherche, comment savoir laquelle utiliser ? Pouvez-vous en utiliser une seule ? Ou toutes ? C’est là qu’un routeur entre en jeu.
Un routeur choisit la meilleure méthode de recherche en fonction de ce que vous demandez et du type de données que vous avez. C’est généralement un modèle de langage puissant qui comprend votre requête, les options de recherche dont vous disposez, et détermine les techniques qui conviendraient le mieux à vos besoins. Ce serait un peu comme vous après avoir lu ce blogue, ayant une bonne idée de pourquoi utiliser la recherche par mots-clés, par embeddings ou par graphes !
Les routeurs rendent vos recherches plus rapides et plus précises. Ils peuvent utiliser différentes techniques pour différentes questions, le tout dans un seul système.
Par exemple, un routeur dans un système d’assistance client pourrait utiliser la recherche par mots-clés pour les codes produits, la recherche par embeddings pour les questions générales, et GraphRAG pour résoudre des problèmes complexes.
Conclusion : choisir votre stratégie de recherche
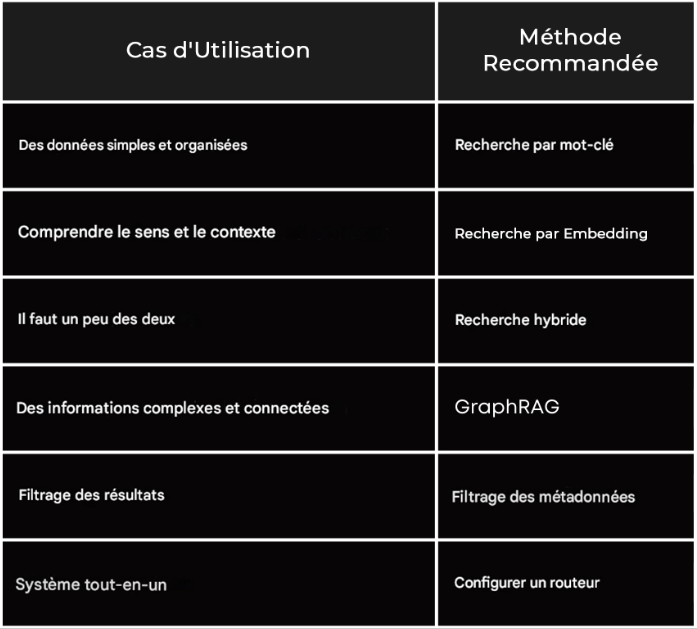
Alors, quelle technique de recherche devriez-vous utiliser ? Eh bien, cela dépend de vos besoins.
Pour des données simples et organisées, restez avec la recherche par mots-clés ou une base de données SQL existante. Si vous devez comprendre le sens et le contexte, optez pour la recherche par embeddings. Besoin d’un peu des deux ? Essayez la recherche hybride. Vous traitez des informations complexes et connectées ? Pensez à GraphRAG. Besoin de filtrer les résultats ? Utilisez le filtrage par métadonnées. Et si vous voulez un système capable de tout faire, mettez en place un routeur.
Souvenez-vous, la meilleure stratégie de recherche s’adapte à vos données, à vos utilisateurs et à ce que votre système peut gérer. N’ayez pas peur de combiner et de mélanger pour créer la meilleure recherche adaptée à votre cas d’utilisation.
Lorsque vous construisez votre prochain projet de données, réfléchissez à la manière dont les gens chercheront des informations. La bonne technique de recherche peut transformer une expérience frustrante en un système réellement intelligent.
Si ce blogue vous a été utile, envisagez de consulter notre cours où nous plongeons dans RAG de zéro à héros avec toutes ces techniques de filtrage et de recherche, ainsi que des approches avancées pour améliorer les LLM dans des applications concrètes.