RAG vs modèles à long contexte : Quel avenir pour vos solutions IA ?
Regardez la vidéo!
Bon matin ! Je suis Louis-François, cofondateur et CTO de Towards AI, et aujourd'hui, on aborde une question assez cruciale : beaucoup disent que le RAG est mort avec l’arrivée des nouveaux modèles dotés de grandes fenêtres de contexte (c’est-à-dire pouvant prendre beaucoup de texte en entrée), comme le GPT-4o Mini, capable de traiter jusqu’à 128 000 tokens en entrée, ou, pire encore, Gemini 1.5 Pro, qui peut en traiter 2 millions. Pour vous donner une idée, 2 millions de tokens équivalent à environ 3 000 pages de texte.
Alors, a-t-on encore besoin de la génération augmentée par récupération (RAG), sachant que de meilleurs modèles vont continuer d’apparaître avec des fenêtres de contexte et des capacités accrues ?
Je ne pense pas. Pour comprendre pourquoi, il est important de saisir les avantages et les compromis d’utiliser des modèles avec de grandes fenêtres de contexte par rapport à la construction d’un système basé sur le RAG, afin de savoir quand et pourquoi investir du temps et des ressources dans le développement de l'un ou l'autre.
Disons que vous créez un assistant d’écriture IA personnel qui doit avoir accès à toute votre collection d'articles ou de livres. Que feriez-vous ?
Ou bien vous développez un assistant financier IA qui doit analyser des rapports financiers. Quelle méthode interprétera correctement les rapports, y compris les chiffres ?
Connaître les avantages et les inconvénients de l'utilisation des modèles à longue fenêtre de contexte par rapport à la construction d’un système RAG performant vous fera économiser du temps et de l’argent.
Étant donné que les fenêtres de contexte deviennent de plus en plus grandes et que les modèles deviennent multimodaux (images, texte, audio, etc.), vous pourriez ne pas vouloir perdre du temps à développer un pipeline de récupération pour votre cas d'usage spécifique, surtout pour une tâche unique, et cela a parfaitement du sens. Mais savoir comment exploiter au mieux ces approches vous sera utile tôt ou tard, lorsque la bonne application se présentera.
Tout d’abord, répondons à la question de savoir ce que sont les modèles à long contexte et quels sont leurs avantages et inconvénients.
Les modèles de langage à long contexte sont des modèles d’IA capables de traiter et de raisonner sur des quantités beaucoup plus importantes de texte en entrée que les modèles LLM traditionnels précédemment publiés. Ces modèles peuvent gérer des contextes allant jusqu'à des centaines de milliers, voire des millions de tokens dans une seul invite, leur permettant ainsi d'ingérer et d'analyser des documents entiers, des livres, des bases de données ou des collections d'informations en une seule fois. Beaucoup ont annoncé la mort du RAG lorsque Gemini a publié une fenêtre de contexte dépassant le million de tokens.
La version de GPT-4 de mars 2023 pouvait seulement traiter jusqu’à 8 000 tokens. Aujourd’hui, en Décembre 2024, GPT-4o Mini, un remplaçant plus intelligent et moins coûteux que GPT-3.5-turbo, peut traiter jusqu’à 128 000 tokens. La récente suite de modèles Llama 3.1 dispose également de fenêtres de contexte de 128 000 tokens. Il y a aussi des modèles récents comme Gemini, qui peut traiter jusqu’à 2 millions de tokens. Cela représente environ 3 000 pages de texte !
Ce long contexte permet aux LLM de réaliser des tâches qui, traditionnellement, nécessitaient des outils externes ou des systèmes spécialisés, comme la récupération d’informations, le raisonnement multi-document ou la réponse à des requêtes complexes, tout cela au sein d'un seul modèle.
Cela est particulièrement utile, par exemple, lorsque vous donnez l’ensemble d’un code source à un modèle, où la compréhension du modèle bénéficie de la vision complète du répertoire et des connexions entre les différentes parties.
Travailler avec un long contexte est également bénéfique lorsqu’un temps de traitement prolongé n'est pas un problème. Ces modèles traitent un grand nombre de tokens à travers un processus itératif, avec une petite partie traitée séquentiellement jusqu'à ce que toute la longueur de l'entrée soit complétée, en sauvegardant les connaissances de chaque sous-partie dans un format encodé. J'ai couvert cela dans ma vidéo sur l'attention infinie si vous êtes intéressé par la manière dont ils peuvent y parvenir.
Alors, quels sont les avantages du RAG ?
Le RAG est une technique excellente pour gérer des collections plus importantes de documents qui ne peuvent pas tenir dans la fenêtre de contexte d’un LLM.
Contrairement à certaines croyances populaires, les systèmes RAG bien conçus sont rapides et précis. Les requêtes adressées à une base de données contenant plusieurs documents sont traitées rapidement grâce à des méthodes d'indexation efficaces. Lorsque l’on traite de grandes quantités de données, ce processus de recherche est beaucoup plus léger comparé à l’envoi de toutes les informations directement à un LLM et à la tentative de "trouver l’aiguille" dans cette montagne de données. Avec le RAG, on peut inclure sélectivement des informations pertinentes dans l’invite initial, réduisant ainsi le bruit et les hallucinations potentielles. En bonus, le RAG permet l’utilisation de techniques et de systèmes avancés, comme le filtrage par métadonnées, les graphes et la recherche hybride, pour améliorer les performances et ne pas dépendre uniquement d’un LLM.
Alors, quelle méthode est meilleure ?
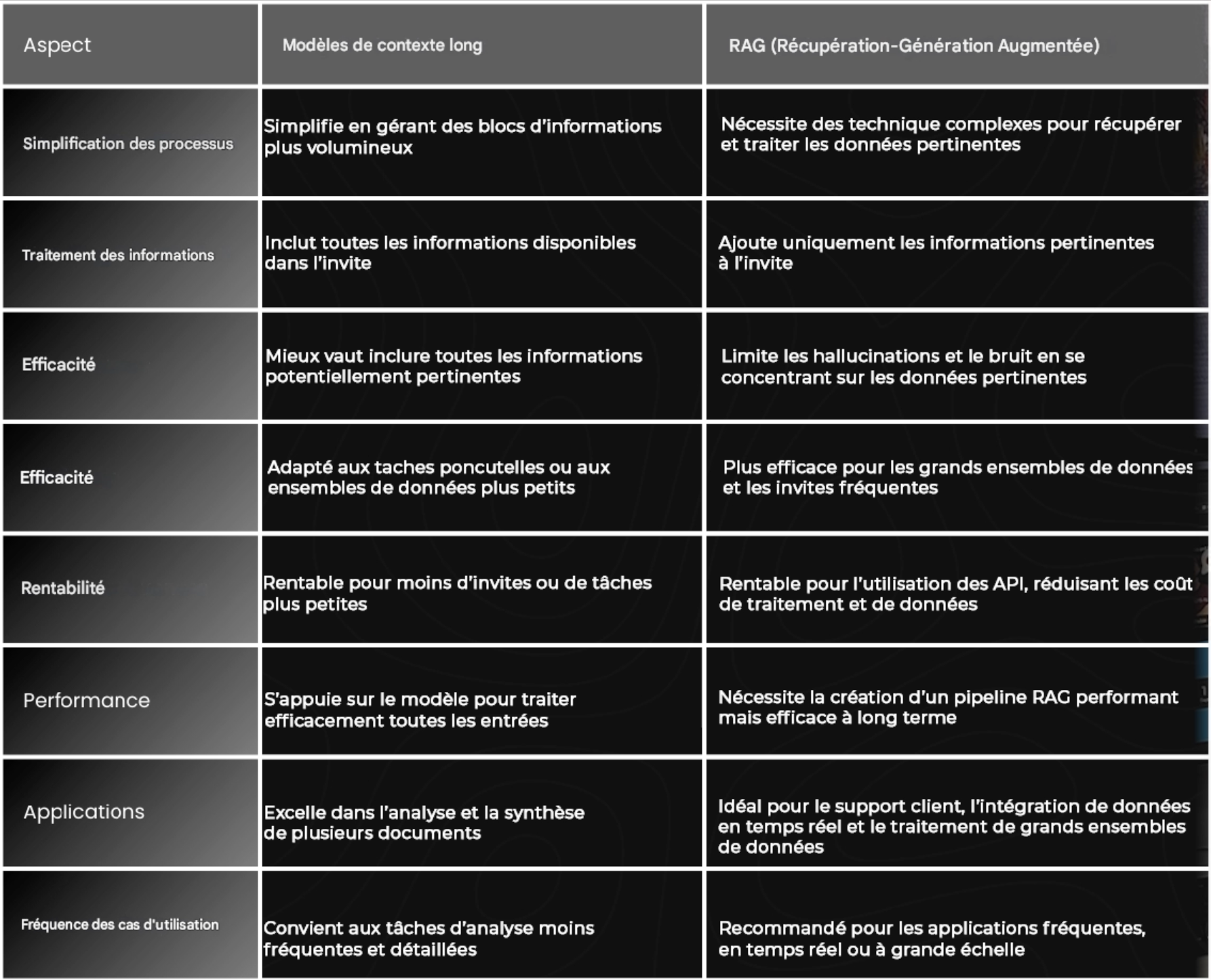
Je pense qu'il y a une place pour l’utilisation et la combinaison des deux méthodes. Les modèles à long contexte simplifient le processus global en réduisant le besoin de techniques RAG complexes, car ils peuvent traiter de plus gros volumes d’informations à la fois. Cela augmente les chances d’inclure des informations pertinentes et réduit le besoin d’évaluations complexes.
Cependant, le RAG reste indispensable, surtout lorsqu'il s'agit de grands ensembles de données, lorsque le temps de traitement est crucial ou lorsqu’il est important d’optimiser les coûts. Le RAG est particulièrement utile lorsque vous utilisez des LLM via des API, car il est plus efficace et plus rentable de récupérer et d’envoyer uniquement les informations les plus pertinentes plutôt que de traiter de grandes quantités de texte.
Les modèles à long contexte peuvent être préférables pour des tâches ponctuelles, pour des ensembles de données plus petits (par exemple, analyser un ou deux PDF) ou lorsqu’on gère un nombre limité de requêtes par heure, car ils peuvent être plus rentables en tenant compte des coûts de développement d'un système RAG performant.
Les principales différences résident dans la manière dont l’information est ajoutée à l’invite initiale. Le RAG n’ajoute que des informations pertinentes, réduisant potentiellement les hallucinations et le bruit, tandis que les modèles à long contexte incluent toutes les informations disponibles, plaçant davantage de responsabilités sur le LLM pour les traiter efficacement.
En pratique, le RAG est bien adapté aux applications comme les systèmes de support client et l'intégration de données en temps réel, tandis que les modèles à long contexte excellent dans les tâches impliquant l'analyse et la synthèse multi-document.
En fin de compte, le choix entre ces approches dépend des besoins spécifiques et des contraintes de l'application. Pour répondre à la question initiale, non, le RAG n'est pas mort. Les deux méthodes ont des forces dans des scénarios différents, donc c'est à vous de décider. Voici un tableau pour vous aider à choisir comment procéder avec votre application.
Maintenant que vous avez une meilleure idée des avantages et des compromis de chaque méthode, assurez-vous de consulter notre cours, où nous approfondissons ce sujet. Vous y apprendrez de nombreuses techniques avancées, comme le KV caching, une nouvelle méthode récemment publiée par Google qui exploite les modèles à long contexte et rend le processus un peu plus efficace.