Enregistrements audio améliorés avec l'IA ! (Et giveaway NVIDIA !)
Nous avons vu “l’inpainting” d’image, qui vise à supprimer un objet indésirable d'une image. Les techniques basées sur l'apprentissage automatique ne suppriment pas simplement les objets, mais elles comprennent également l'image et remplissent les parties manquantes de l'image avec ce à quoi l'arrière-plan devrait ressembler.

Exemple d'inpainting d'image de LaMa.
Comme nous l'avons vu, les avancées récentes sont incroyables, tout comme les résultats, et cette tâche d'inpainting peut être très utile pour de nombreuses applications comme les publicités ou l'amélioration de votre future publication Instagram. Nous avons également couvert une tâche encore plus difficile : l'inpainting vidéo, où le même processus est appliqué aux vidéos pour supprimer des objets ou des personnes.

Exemple d'inpainting d'image de STTN.
Le défi avec les vidéos consiste à rester cohérent d'une image à l'autre sans creer aucun artefact étrange dû au changement d’images rapide d’une vidéo. Mais maintenant, que se passe-t-il si nous supprimons correctement une personne d'un film et que le son est toujours là, inchangé ? Eh bien, nous pouvons entendre un fantôme et ruiner tout notre travail.
C'est là qu'intervient une tâche que je n'ai jamais couverte sur mon blogue : l'inpainting de la parole. Vous avez bien lu, des chercheurs de Google viennent de publier un article visant à inpaint la parole, et, comme nous le verrons, les résultats sont assez impressionnants. D'accord, nous pourrions plutôt entendre que voir les résultats, mais vous comprenez mon point. Il peut corriger votre grammaire, votre prononciation ou même supprimer les bruits de fond. Toutes les choses sur lesquelles je dois absolument continuer à travailler, ou… simplement utiliser leur nouveau modèle… Écoutez les exemples dans ma vidéo ou sur le site Web du projet !
p.s. il y a aussi une grosse surprise à la fin de la vidéo que la vignette et le titre ont peut-être spoilé, mais vous voulez certainement jeter un œil !
Entrons dans la partie la plus passionnante de cet article : comment ces trois chercheurs de Google ont créé SpeechPainter, leur modèle d’inpainting de la parole. Pour comprendre leur démarche, il faut d'abord définir le but de l'inpainting de la parole.

Modèle SpeechPainter basé sur Perceiver IO. Image tirée du papier.
Ici, nous voulons prendre un clip audio et sa transcription et “inpaint”, ou enlever et remplacer, une petite section du clip audio. Le texte que vous voyez en bas à gauche est la transcription de la piste audio, la partie gris clair étant supprimée du clip audio et inpaint par le réseau.
Le modèle effectue non seulement l'inpainting de la parole, mais il le fait tout en conservant l'identité de l'orateur et l'environnement d'enregistrement suivant le texte. C’est génial! Encore une fois, prenez quelques minutes pour écouter les exemples dans la vidéo ou sur le site Web du projet des auteurs !
Maintenant que nous savons ce que le modèle peut faire, comment y parvient-il ? Comme vous vous en doutez, c'est assez similaire à l'inpainting d'image où nous remplaçons les pixels manquants dans une image. Au lieu de cela, nous remplaçons les données manquantes dans une piste audio après une transcription spécifique. Ainsi, le modèle sait quoi dire et son objectif est de combler le vide dans la piste audio en suivant le texte et en imitant la voix de la personne et l'atmosphère générale de la piste pour se sentir réel.

Modèle SpeechPainter basé sur Perceiver IO. Image tirée du papier.
Étant donné que l'inpainting d'image et de parole sont des tâches similaires, ils utiliseront des architectures similaires. Ils ont utilisé un modèle appelé Perceiver IO, illustré ci-dessus. Il fera la même chose qu'avec une image où vous encodez votre image, extrayez les informations les plus utiles et effectuez des modifications, et décodez-la pour reconstruire une autre image avec ce que vous voulez réaliser. Dans l'exemple d'inpainting, la nouvelle image serait simplement la même, mais avec quelques pixels modifiés.
Dans ce cas, au lieu de pixels provenant d'une image, l'architecture Perceiver IO peut fonctionner avec à peu près n'importe quel type de données, y compris les spectrogrammes mel, qui sont essentiellement nos empreintes vocales représentant notre piste audio à l'aide de fréquences. Ensuite, ce spectrogramme et la transcription textuelle sont encodés, édités et décodés pour remplacer l'espace dans le spectrogramme par ce qui devrait apparaître. Comme vous le voyez ci-dessus, c'est comme générer une image, et nous utilisons le même processus que dans l'inpainting d'image, mais les données de sortie et d'entrée sont des spectrogrammes, ou, fondamentalement, des images de la bande sonore.
Si vous souhaitez en savoir plus sur l'architecture Perceiver IO, je vous recommande vivement de regarder la vidéo de Yannic Kilcher à ce sujet.
Ils ont formé leur modèle sur un ensemble de données vocales, créant des trous aléatoires dans les pistes audio et essayant de combler ces trous à partir du script initial. Ensuite, ils ont utilisé une approche GAN pour l’entraînement du modèle afin d'améliorer encore le réalisme des résultats.
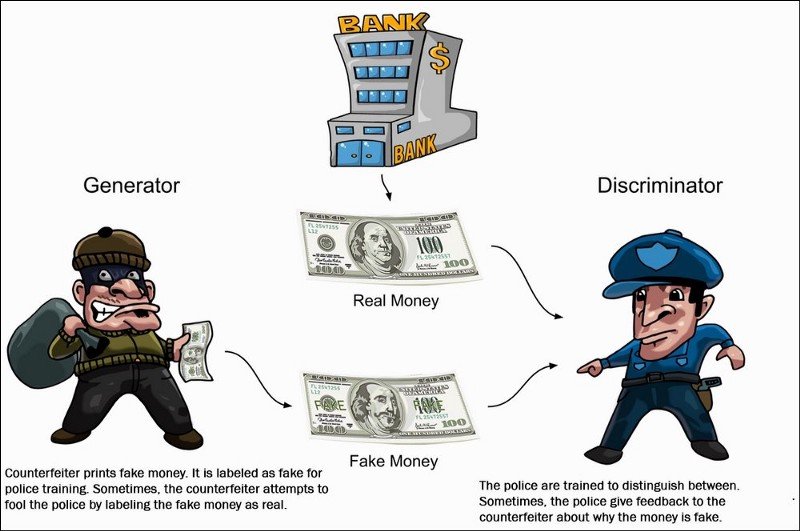
Générateur et discriminateur clairement expliqués. Image de Packt ; Principes des GAN.
Rapidement, avec les GAN, il y aura le modèle que nous avons vu, appelé générateur, et un autre modèle appelé discriminateur. Le générateur sera formé pour générer les nouvelles données, dans notre cas, la piste audio qui a été inpaint. Simultanément, le discriminateur recevra des échantillons de l'ensemble de données d'apprentissage et des échantillons générés et essaiera de deviner si l'échantillon a été générée, appelé faux, ou réel à partir de l'ensemble d'apprentissage. Idéalement, nous voudrions que notre discriminateur ait raison la moitié du temps afin qu'il choisisse essentiellement au hasard, ce qui signifie que nos échantillons générés sonnent comme une vrai.e piste audio Le discriminateur pénalisera alors le modèle du générateur afin de le rendre plus réaliste.
Et voilà ! Vous vous retrouvez avec un modèle qui peut prendre une piste audio et sa retranscription pour corriger votre grammaire ou votre prononciation ou encore combler des trous en suivant votre voix et l'ambiance du morceau. C'est trop cool.
Il vous suffit donc d'entraîner ce modèle une fois sur un ensemble de données général et conscéquent, puis de l'utiliser avec vos propres pistes audio, car il devrait, idéalement, pouvoir généraliser et fonctionner assez bien ! Bien sûr, il y a quelques cas d'échec, mais les résultats sont assez impressionnants, et vous pouvez écouter plus d'exemples sur leur page de projet liée ci-dessous.
Merci d'avoir lu, regardez la vidéo pour entendre les exemples !
Inscrivez-vous gratuitement à GTC22 (n'oubliez pas de laisser un commentaire et de vous abonner à ma chaîne youtube pour participer au concours et avoir la chance de gagner une carte graphique NVIDIA RTX 3080Ti, étapes dans la vidéo !) : https://nvda.ws/3upUQkF