Cette IA supprime les objets indésirables de vos images !
Vous avez très certainement vécu cette situation au moins une fois : vous prenez une superbe photo avec votre ami(e), et quelqu'un fait un photobomb derrière, ruinant votre future publication Instagram! Eh bien, ce n'est plus un problème à vous soucier! Que ce soit une personne ou une poubelle que vous avez oublié de retirer avant de prendre votre selfie qui gâche votre photo. Cette IA supprimera automatiquement l'objet ou la personne indésirable dans l'image et sauvera votre prochaine publication. C'est comme un artiste photoshop professionnel dans votre poche, et fonctionne avec un simple clic!

Exemple “d'inpainting d'image”. Fabriqué avec LaMa.
Cette tâche consistant à supprimer une partie d'une image et à la remplacer par ce qui devrait apparaître derrière a été abordée par de nombreux chercheurs depuis longtemps. C'est ce qu'on appelle “l'inpainting d'image”, et c'est extrêmement complèxe. Comme nous le verrons, le papier de recherche que je veux vous présenter y parvient avec des résultats incroyables et peut le faire facilement en haute définition, contrairement aux approches précédentes dont vous avez peut-être entendu parler auparavant. Vous voulez certainement rester jusqu'à la fin de l'article pour voir cela dans la vidéo démo. Vous ne croirez pas à quel point cela semble génial et réaliste pour quelque chose produit en une fraction de seconde par un algorithme!
Pour supprimer un objet d'une image, la machine doit comprendre ce qui doit apparaître derrière cet objet. Et pour ce faire, il faudrait avoir une compréhension tridimensionnelle du monde comme le font les humains, mais ce n'est pas le cas. La machine a juste accès à quelques pixels dans une image, et c'est pourquoi c'est si compliqué, alors que ça semble si simple pour nous qui pouvons simplement imaginer les profondeurs et deviner qu'il devrait y avoir le reste du mur, ici la fenêtre, etc. ..

Exemple d’images d’entraînement pour une telle machine, tiré de l’ensemble de données Imagenet.
Nous devons essentiellement apprendre à la machine à quoi ressemble le monde. Nous allons donc le faire en utilisant BEAUCOUP d'exemples d'images du monde réel afin qu'il puisse avoir une idée de ce à quoi ressemble notre monde dans le monde de l'image en deux dimensions, ce qui n'est pas une approche parfaite mais peut tout de même (relativement) bien fonctionner pour ce type de tâches.

Image basse définition vs image haute définition. Image de l'auteur.
Ensuite, un autre problème vient du coût de calcul de l'utilisation d'images du monde réel avec beaucoup trop de pixels. Pour résoudre ce problème, la plupart des approches actuelles fonctionnent avec des images de faible qualité, donc une version réduite de l'image qui est gérable pour nos ordinateurs, et une mise à l'échelle de la partie peinte à la fin pour la remplacer dans l'image d'origine, ce qui rend les résultats finaux moins bons que ce qu'il pourrait être (un peu flou). Ou du moins, ils ne seront pas assez beaux pour être partagés sur Instagram et avoir tous les likes que vous méritez! Nous ne pouvons pas vraiment lui fournir directement des images de haute qualité, car le traitement et la formation prendront beaucoup trop de temps. Ou pouvons-nous?
Le réseau: LaMa

L'architecture LaMa. Image tirée du papier.
Eh bien, ce sont les principaux problèmes auquels les chercheurs se sont attaqués dans cet article, et voici comment…
Roman Suvorov et al. de Samsung Research ont présentés un nouveau réseau appelé LaMa qui est assez particulier. Comme vous pouvez le voir ci-dessus, dans l'inpainting d'image, vous envoyez généralement l'image initiale ainsi que ce que vous souhaitez en supprimer. C'est ce qu'on appelle un masque (image du dessus en noir et blanc) et couvrira l'image, comme vous pouvez le voir ici, et le réseau n'aura plus accès à ces informations, car il doit désormais remplir les pixels manquant.
Ensuite, il doit comprendre l'image et essayer de remplir les pixels avec des couleurs qui, selon lui, devraient convenir le mieux. Donc, dans ce cas, ils démarrent comme n'importe quel autre réseau et réduit la taille de l'image, mais ne vous inquiétez pas, leur technique leur permettra de garder la même qualité qu'une image haute résolution. C'est parce qu'ici, dans le traitement de l'image, ils utilisent quelque chose d'un peu différent de d'habitude.

Réseaux de neurones convolutifs (CNN), image de l'auteur.
En règle générale, nous pouvons voir différents réseaux ici au milieu, principalement des réseaux de neurones convolutifs. De tels réseaux sont souvent utilisés sur les images en raison du fonctionnement des convolutions, que j'ai expliqué dans d'autres articles, comme celui-ci si vous êtes intéressé par son fonctionnement.

Encodage et décodage d'images en deux étapes à l'aide de réseaux de neurones à convolution (CNN). Image de l'auteur.
Rapidement, le réseau fonctionnera en deux étapes :
D'abord, il compressera l'image et essaiera de n'enregistrer que les informations pertinentes. Le réseau finira par conserver principalement les informations générales sur l'image comme ses couleurs, son style général ou les objets généraux apparaissant , mais pas de détails précis. Ensuite, il tentera de reconstruire l'image en utilisant les mêmes principes mais à l'envers. Nous utilisons des astuces comme les sauts de connexion (skip connections) qui enregistreront les informations des premières couches du réseau et les transmettront le long de la deuxième étape afin qu'elles puissent les orienter vers les bons objets. Bref, le réseau sait facilement qu'il y a une tour avec un ciel bleu et des arbres, ce qu'on appelle des informations globales, mais il a besoin de ces sauts de connexion pour savoir que c'est la tour Eiffel au milieu de l'écran, il y a des nuages ici et là, les arbres avoir ces couleurs, etc. Tous les détails à grain fin, que nous appelons informations locales.
Suite à un long entraînement avec de nombreux exemples, on s'attendrait à ce que notre réseau reconstruise l'image ou du moins une image très similaire contenant le même type d'objets et soit très similaire sinon identique à l'image initiale.
Mais rappelez-vous, dans ce cas, nous travaillons avec des images de qualité inférieure que nous devons mettre à l'échelle par la suite, ce qui nuira à la qualité des résultats. La particularité ici est qu'au lieu d'utiliser des convolutions comme dans les réseaux convolutifs classiques et des sauts des connexions pour conserver les connaissances locales, on utilise ce que l'on appelle la Fast Fourier Convolution ou FFC. Cela signifie que le réseau fonctionnera à la fois dans les domaines spatial et fréquentiel et n'aura pas besoin de revenir aux premières couches pour comprendre le contexte de l'image. Chaque couche fonctionnera avec des convolutions dans le domaine spatial pour traiter les caractéristiques locales et utilisera des convolutions de Fourier dans le domaine fréquentiel pour analyser les caractéristiques globales. Le domaine fréquentiel (incluant Fourier) est un peu spécial, et voici une superbe vidéo qui l’explique assez clairement si vous êtes curieux.
Ce domaine fréquentiel transformera essentiellement votre image en toutes les fréquences possibles, similaire à des ondes sonores représentant quelqu’un qui parle, mais avec des images, et vous dira combien de chaque fréquence l'image contient. Ainsi, chaque "pixel" de cette image nouvellement créée représentera une fréquence couvrant toute l'image spatiale et combien elle est présente, au lieu de couleurs. Les fréquences ici ne sont que des motifs répétés à différentes échelles.

Un "pixel" dans l'exemple d'image de Fourier (spectrale) représente les lignes verticales d'un mur de briques. Image de l'auteur.
Par exemple, l'un de ces pixels de l’image fréquentielle pourrait être fortement activé par les lignes verticales à une distance spécifique les unes des autres. Dans ce cas, il pourrait s'agir de la même distance que la longueur d'une brique. Ce pixel précis serait donc fortement activé s'il y a un mur de briques dans l'image. À partir de là, vous comprendrez qu'il y a probablement un mur de briques de taille proportionnelle à son activation. Et vous pouvez répéter cela pour tous les pixels activés pour des motifs similaires, vous donnant de bonnes indications sur l'aspect général de l'image mais rien sur les objets eux-mêmes ou les couleurs. Le domaine spatial s'en chargera.
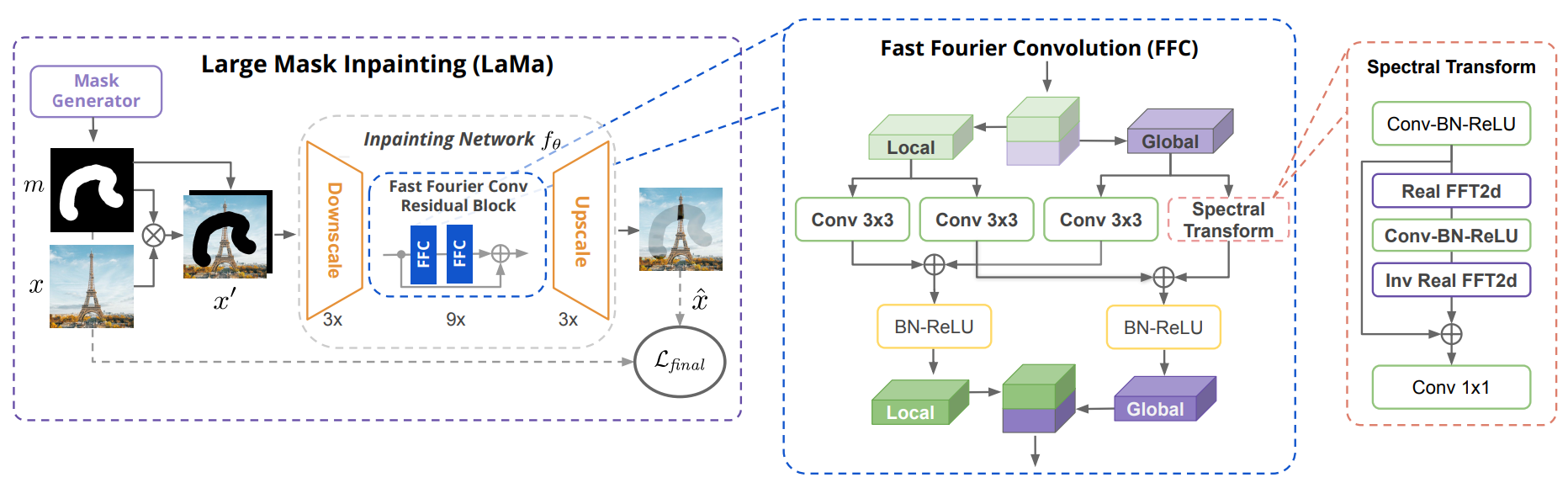
Architecture LaMa avec détails FFC. Image tirée du papier.
Ainsi, faire des convolutions sur cette nouvelle image de Fourier vous permet de travailler avec l'image entière à chaque étape du processus de convolution, de sorte qu'elle a accès à une bien meilleure compréhension globale de l'image même aux premières couches sans trop de coûts de calcul, ce qui est impossible à réaliser avec des circonvolutions régulières (dans le domaine spatial). Ensuite, les résultats globaux et locaux sont enregistrés et envoyés aux couches suivantes, qui répéteront ces étapes. Vous vous retrouverez avec l'image finale que vous pourrez redimensionner. L'utilisation du domaine de Fourier est ce qui rend le modèle adaptable à des images de plus grandes définitions, car la résolution de l'image n'affecte pas le domaine de Fourier étant donné que ça utilise des fréquences sur toute l'image au lieu de couleurs, et les motifs répétés seront les mêmes quel que soit le taille de l'image, représentant les mêmes proportions et répétitions dans l’image. Cela signifie que même lors de l’entraînement de ce réseau avec de petites images, vous pourrez ensuite l’utiliser avec des images beaucoup plus grandes et obtenir des résultats étonnants!
Regardez plus de résultats dans cette vidéo expliqué simplement sous-titré en français:
Histoire de rester réaliste, voici quelques exemples d'échecs dans les images peintes produites par LaMa tirés du papier:



Comme vous pouvez le voir, les résultats ne sont pas parfaits, mais ils sont assez impressionnants, et j'ai hâte de voir ce qu'ils feront ensuite pour les améliorer!
Bien sûr, ce n'était qu'un simple aperçu de ce nouveau modèle, et vous pouvez trouver plus de détails sur la mise en œuvre dans l'article lié dans la description ci-dessous. J'espère que vous avez apprécié l'article, et si c'est le cas, veuillez prendre une seconde pour le partager avec un ami qui pourrait trouver cela intéressant!
Merci d’avoir lu jusqu’à la fin!
Références
Suvorov, R., Logacheva, E., Mashikhin, A., Remizova, A., Ashukha, A., Silvestrov, A., Kong, N., Goka, H., Park, K. and Lempitsky, V., 2022. Resolution-robust Large Mask Inpainting with Fourier Convolutions. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (pp. 2149–2159)., https://arxiv.org/pdf/2109.07161.pdf
Colab Demo: https://colab.research.google.com/github/saic-mdal/lama/blob/master/colab/LaMa_inpainting.ipynb
Produit utilisant LaMa: https://cleanup.pictures/
Fourier Domain expliqué par @3Blue1Brown: https://youtu.be/spUNpyF58BY