OpenAI o1 : L'IA Qui Réfléchit Avant de Parler !
Regardez la vidéo!
Bon matin à tous ! Ici Louis-François, cofondateur de Towards AI, et aujourd'hui, nous allons plonger dans le dernier modèle d'OpenAI, o1, qui présente de nouvelles fonctionnalités super intéressantes qui le distinguent des versions précédentes comme GPT-4o, GPT-4, et même des modèles comme Claude, Gemini et LLaMA. Alors, voyons ce que fait o1 différemment, comment il fonctionne, et ce qui le rend à la fois puissant et, eh bien... un peu lent. Mais nous y reviendrons !
Qu'est-ce que o1 et comment fonctionne-t-il ?
Alors, qu'est-ce que o1 ? Le modèle o1 d'OpenAI est leur dernière itération, axée sur le raisonnement avancé et le traitement par chaîne de pensée (ou chain-of-tought en anglais). Contrairement aux modèles précédents comme GPT-4o ou GPT-4, o1 est spécialement conçu pour "réfléchir" avant de répondre. Cela signifie qu'il ne se contente pas de générer du texte, mais passe par plusieurs étapes de raisonnement pour résoudre des problèmes complexes avant de répondre. Cette approche le rend plus performant pour les tâches nécessitant un raisonnement détaillé, comme résoudre des problèmes de mathématiques ou des défis de programmation. C’est un peu comme nous, qui réfléchissons avant de parler.
Malheureusement, comme certains d'entre nous, ce processus de réflexion avant de répondre rend o1 beaucoup, beaucoup plus lent que les modèles précédents, provoquant parfois l'absence de réponse.
Lorsque vous posez une question, il prend plus de temps parce qu'il consacre plus de ressources informatiques à l'inférence — en gros, il prend le temps de réfléchir et d'affiner sa réponse. Tout comme nous demanderions de "réfléchir étape par étape" avec l'invite de chaîne de pensée, mais il le fait à chaque fois grâce à la manière dont le modèle a été entraîné avec l'apprentissage par renforcement pour le forcer à penser étape par étape et à réfléchir avant de répondre. Malheureusement, il n’y a aucun détail sur l’ensemble de données utilisé pour cela, à part le fait qu’il s’agit d’un "processus d’entraînement de données extrêmement efficace".
Bien que les résultats semblent impressionnants, on va devoir attendre de voir si les gens apprécient le fait que cela prenne beaucoup plus de temps pour obtenir de bons résultats. Il y a tout de même des éléments très intéressants à mentionner...
Différences clés entre o1 et GPT-4o
Tout d'abord, ce qui distingue vraiment o1 des modèles comme GPT-4o, ce sont évidemment ses capacités de raisonnement intégrées. Lors des tests, o1 a surpassé GPT-4o dans les tâches nécessitant un raisonnement intensif, comme la programmation, la résolution de problèmes et les benchmarks académiques. L’une des caractéristiques marquantes de o1 est sa capacité à enchaîner les pensées, ce qui signifie qu’il est mieux équipé pour résoudre des problèmes à plusieurs étapes là où les modèles précédents auraient eu du mal.
Par exemple, dans des tâches comme les compétitions mathématiques et les défis de programmation, o1 a réussi à résoudre des problèmes beaucoup plus complexes. En moyenne, o1 a obtenu des scores bien plus élevés dans les benchmarks comme l'American Invitational Mathematics Examination, où il a résolu 74 % des problèmes, contre 9 % pour GPT-4o.
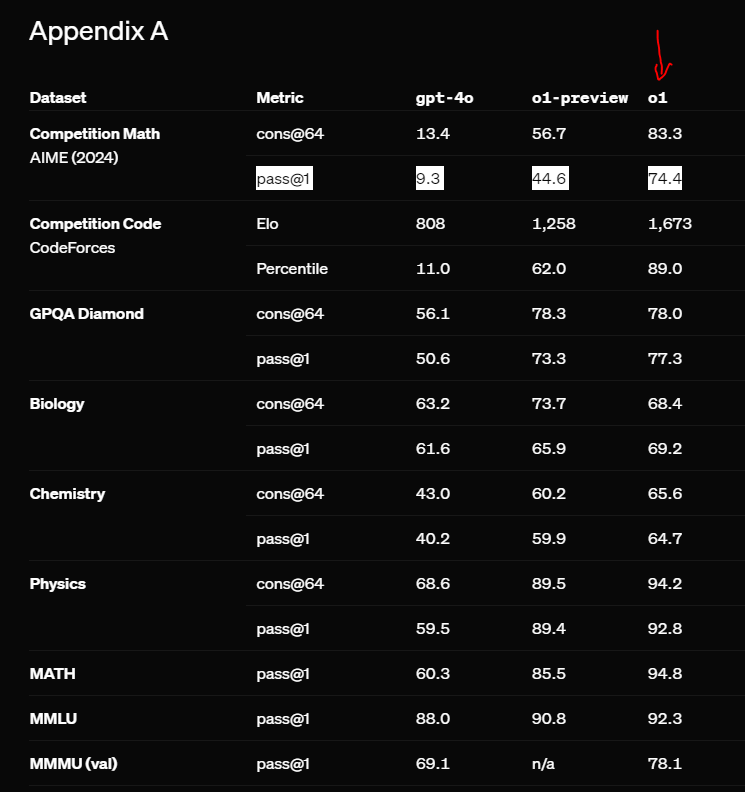
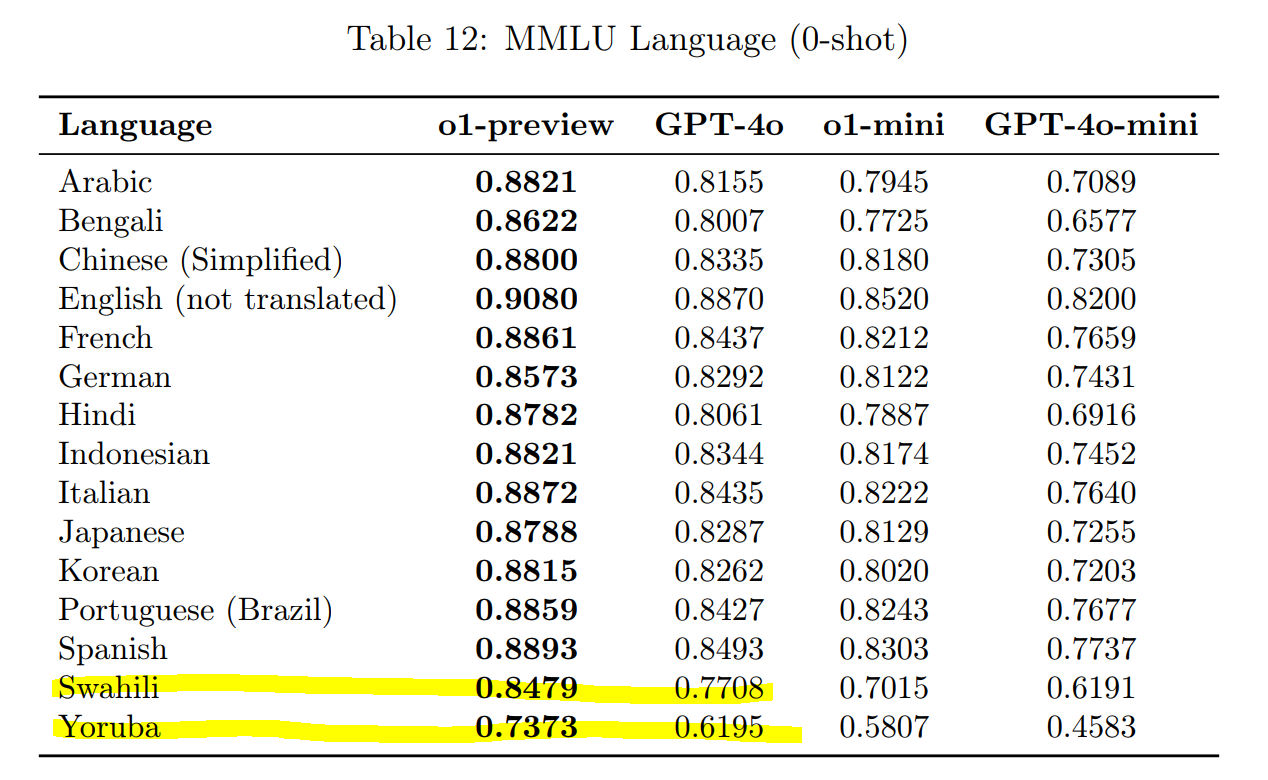
Il gère également très bien les tâches multilingues. En fait, lors de tests impliquant des langues comme le yoruba et le swahili, qui sont connues pour être difficiles pour les modèles précédents, o1 a réussi à surpasser GPT-4o pour toutes les langues.
Temps d'inférence et compromis de performance
C'est ici que les points forts de o1 deviennent sa faiblesse potentielle. Bien que le modèle soit bien meilleur en matière de raisonnement, cela se fait au détriment du temps d'inférence et du nombre de tokens. Le processus de raisonnement en chaîne rend o1 plus lent que GPT-4o, car il passe plus de temps à réfléchir aux problèmes pendant l'inférence, lorsqu'il interagit avec vous, plutôt que de se concentrer uniquement sur l’utilisation intensive des ressources pour entraîner le modèle. C’est plutôt cool de voir une autre voie explorée ici, grâce aux gains d’efficacité dans la génération de tokens des modèles récents, qui réduisent continuellement les coûts et la latence de génération. Cependant, cela augmente considérablement les deux.

Cette différence de latence est particulièrement notable dans les tâches où le modèle est censé gérer un raisonnement complexe en plusieurs étapes. Donc, si vous utilisez o1 pour des tâches rapides et simples, il pourrait sembler un peu lent par rapport à des modèles comme GPT-4o-mini ou Claude. C’est essentiellement le compromis entre la vitesse et la profondeur de compréhension du modèle.
Réduction des hallucinations
Un autre domaine où o1 excelle est la réduction des hallucinations. Lors des tests, o1 a beaucoup moins halluciné que GPT-4o, en particulier dans les tâches où l'exactitude factuelle est cruciale. Par exemple, dans le test SimpleQA, o1 avait un taux d'hallucination de seulement 0,44, contre 0,61 pour GPT-4o. Cela rend o1 plus fiable pour les tâches où il est essentiel d'obtenir des informations précises.

Auto-réflexion et le "problème de la fraise"
Vous avez peut-être entendu des gens parler du "Modèle Strawberry", qui est en fait un nom de code pour o1. La raison pour laquelle il est appelé "Strawberry" est une sorte de blague interne — à cause du nombre de "R" dans le mot "fraise" en anglais, ce qui renvoie un peu à l'idée du raisonnement complexe. Tout comme il est difficile de compter les R dans "strawberry" pour un modèle, il est difficile d’obtenir les bonnes étapes de raisonnement à chaque fois, mais o1 rend ce processus beaucoup plus efficace.
Gestion de l'équité et des biais
Une autre amélioration majeure dans o1 est la manière dont il gère l'équité et les biais. Lors des évaluations d'équité comme le test BBQ, o1 a été bien meilleur pour éviter les réponses stéréotypées par rapport à GPT-4o. Cependant, il n’est pas parfait — lorsqu'il est confronté à des questions ambiguës, o1 rencontre parfois des difficultés, surtout lorsque la bonne réponse devrait être "Inconnue". Mais dans l'ensemble, il est plus aligné sur les valeurs humaines, notamment par rapport à GPT-4o.
Conclusion
Alors, le nouveau modèle Strawberry d'OpenAI, ou le modèle o1, n’est pas une avancée énorme. C’est essentiellement un meilleur modèle qui met en œuvre l’invite de chaîne de pensée que la plupart d'entre nous utilisaient déjà avec les autres modèles, et cela a déjà été fait auparavant. Le problème était que cela prenait plus de temps pour générer et coûtait plus cher à cause de l’augmentation du nombre de tokens, donc les gens ont arrêté de le faire. Il semble qu'OpenAI ait décidé le contraire et soit allé à fond dans cette approche. En effet, il est plus lent que des modèles comme GPT-4o, car il prend le temps de réfléchir aux problèmes, mais si vous avez besoin d’un modèle qui excelle dans la résolution de tâches complexes, o1 est votre choix.
Si vous travaillez sur des problèmes compliqués ou avez besoin d’un modèle fiable dans différentes langues, o1 vaut certainement le temps d’attente supplémentaire. Mais si la rapidité est votre priorité, GPT-4o-mini pourrait toujours être la meilleure option.
Comme toujours, j’ai mis des ressources plus détaillées dans la description ci-dessous, ainsi qu'un live en anglais très divertissant de David Shapiro si vous voulez plonger plus en profondeur dans le fonctionnement et les résultats de o1.
J'essaie habituellement d'expliquer des articles de recherche ou des approches, mais malheureusement, OpenAI n’a pas beaucoup parlé du processus d’apprentissage par renforcement ni des données qu’ils ont utilisées, comme d’habitude. Cependant, on peut supposer que le modèle est très similaire à GPT-4o et que l’ensemble de données pour l’entraînement par renforcement est simplement un ensemble bien sélectionné qui met en œuvre des processus de chaîne de pensée.
J'espère que vous avez trouvé ce court blogue utile pour démystifier ce que représente o1 par rapport aux meilleurs LLM actuels.
Ressources:
Blogue de OpenAI: https://openai.com/index/introducing-openai-o1-preview/
Blogue 2 de OpenAI: https://openai.com/index/learning-to-reason-with-llms/
OpenAI "system card": https://openai.com/index/openai-o1-system-card/
Super article de Nathan Lambert: https://www.interconnects.ai/p/openai-strawberry-and-inference-scaling-laws
Live amusant de David Shapiro: https://youtu.be/AO7mXa8BUWk