Les Mélanges d’Experts (MoE) en IA Expliqués
Ce que vous savez sur le Mélange d'Experts est erroné. On n'utilise pas cette technique parce que chaque modèle est un expert sur un sujet spécifique. En fait, chacun de ces soi-disant experts n'est pas un modèle individuel, mais quelque chose de beaucoup plus simple.
On peut maintenant supposer que la rumeur selon laquelle GPT-4 possède 1,8 trillion de paramètres est vraie…
1,8 trillion ça équivaut à 1 800 milliards, soit 1,8 million de millions. Si nous pouvions trouver quelqu'un pour traiter chacun de ces paramètres en une seconde, ce qui reviendrait à demander de faire une multiplication complexe avec des valeurs comme celles-ci, cela lui prendrait 57 000 ans ! Encore une fois, en supposant que vous puissiez faire chaque calcul en une seconde. Si nous faisons cela tous ensemble, en calculant un paramètre par seconde avec 8 milliards de personnes, nous pourrions réaliser cela en 2,6 jours. Pourtant, les modèles basés sur la technologie des Transformers font cela en millisecondes.
Cela est dû à beaucoup d'ingénierie, y compris ce que nous appelons un « mélange d'experts ».
Malheureusement, nous n'avons pas beaucoup de détails sur GPT-4 et comment OpenAI l'a construit, mais nous pouvons nous plonger davantage dans un modèle très similaire et presque aussi puissant de Mistral appelé Mixtral 8x7B.

Image du blog de Mistral.
Au fait, si vous ne connaissez pas encore Mistral, vous devriez vraiment envisager de suivre leur travail ! Mistral est une startup française qui développe des modèles de langage à la pointe de la technologie, et ils sont très prometteurs et plutôt ouverts à partager leurs avancées par rapport à certaines autres entreprises connues. Et si suivre toutes ces différentes entreprises et recherches semble difficile, eh bien, vous pouvez facilement rester à jour avec toutes ces nouvelles avancées en vous abonnant à la chaîne !
Mais qu'est-ce exactement qu'un mélange d'experts ? Comme je l'ai dit, il ne s'agit pas de plusieurs experts comme la plupart des gens le disent. Même si le modèle est appelé Mixtral 8x7B, ce n'est pas 8 fois un modèle de 7 milliards de paramètres, et de même pour GPT-4. Même si nous supposons qu'il possède 1,8 trillion de paramètres, ce qui n'a jamais été confirmé par OpenAI, il n'y a pas 8 experts de 225 milliards de paramètres comme certains le disent. En réalité, il s'agit tout simplement d'un seul modèle.
Pour mieux comprendre cela, nous devons examiner ce qui fait fonctionner les modèles Transformers.

L'architecture du transformeur. Image de Attention is All you Need (Google).
Bien que vous ayez probablement vu cette image de nombreuses fois, ce que nous utilisons en réalité ressemble davantage à ceci : un transformeur uniquement décodeur.

Transformeur décodeur uniquement. Image de Attention is All you Need (Google).
Cela signifie que le modèle essaie de prédire le prochain token, ou le prochain mot, d'une phrase que vous envoyez comme prompt d'entrée. Il le fait mot par mot, ou token par token, pour construire une phrase qui, statistiquement, a le plus de sens en fonction de ce qu'il a vu pendant son entraînement.
Entrons maintenant dans les parties les plus importantes. Tout d'abord, de toute évidence, vous aurez votre texte et aurez besoin d'obtenir vos embeddings, qui sont les nombres que le modèle comprend. Vous pouvez voir cela comme une grande liste d'environ mille valeurs représentant divers attributs sur ce que signifie votre phrase ou mot d'entrée. L'un pourrait être sa taille, l'autre sa couleur, un autre pourrait être s'il peut être mangé ou non, etc., juste divers attributs que le modèle d'embedding apprend par lui-même pour représenter notre monde avec seulement une à deux mille valeurs numériques. Ceci est fait pour chaque token, qui peut être un morceau de texte, une partie de code, une partie d'une image ou autre chose, transformé en cette liste de nombres.
Mais cette information n'est que des nombres dans une grande liste. Nous venons de perdre toutes nos informations contextuelles, nous n'avons qu'un tas de mots représentés par des nombres. On doit donc ajouter des informations de position, en gros, juste des informations syntaxiques, pour aider à mieux comprendre la phrase ou le texte envoyé, montrant globalement et localement où se trouve chaque mot. Ainsi, chaque token finit par être représenté par encore plus de valeurs à l'intérieur du réseau. Ce n'est vraiment pas efficace par rapport à la compréhension directe du langage. Dans le cas de Mixtral, chaque liste pour les tokens a 4096 valeurs. C'est déjà assez gros, et on en envoie beaucoup en même temps ! Nous avons maintenant tout notre texte correctement représenté dans de nombreuses listes de ces 4000 nombres. Maintenant, que fait un modèle comme GPT-4 ou Mixtral avec ça ?
Il le comprend, puis répète ce processus de nombreuses fois, effectué à l'intérieur d'une partie essentielle : le bloc du transformeur, introduit dans le célèbre article Attention Is All You Need.
À l'intérieur de ce bloc, nous avons les deux composants cruciaux de tous ces modèles comme GPT-4, Llama3, Gemini ou Mixtral : une étape d'attention et une étape de feed forward. Les deux ont leur propre rôle.
Le mécanisme d'attention est utilisé pour comprendre le contexte des tokens d'entrée. Comment ils s'imbriquent, comment comprendre tout ça. En bref, nous avons nos nombreux tokens qui sont chacun déjà une liste de nombres. Le mécanisme d'attention transforme nos listes de nombres en fusionnant essentiellement des parties de toutes nos listes actuelles et en apprenant la meilleure combinaison possible pour les comprendre. Vous pouvez voir cela comme une réorganisation de l'information pour qu'elle ait du sens pour son propre cerveau. Ce que le modèle apprend lorsqu'on dit qu'il s'entraîne, c'est où placer quels nombres pour l'étape suivante. Accorder moins d'importance aux tokens inutiles et plus aux tokens utiles. Tout comme lorsque vous rencontrez une nouvelle personne, vous donnez idéalement plus d'importance à son nom et moins à ce qu'elle a dit en premier, que ce soit « Salut, bienvenue ou bonjour ». Se souvenir du nom est plus important que le synonyme qu'elle a utilisé, même si mon propre cerveau n'est pas d'accord avec ça. Ici, l'attention fait la même chose, apprenant simplement à quoi accorder son attention à travers de nombreux exemples.
Couche “Feed Forward” du block Transformer.
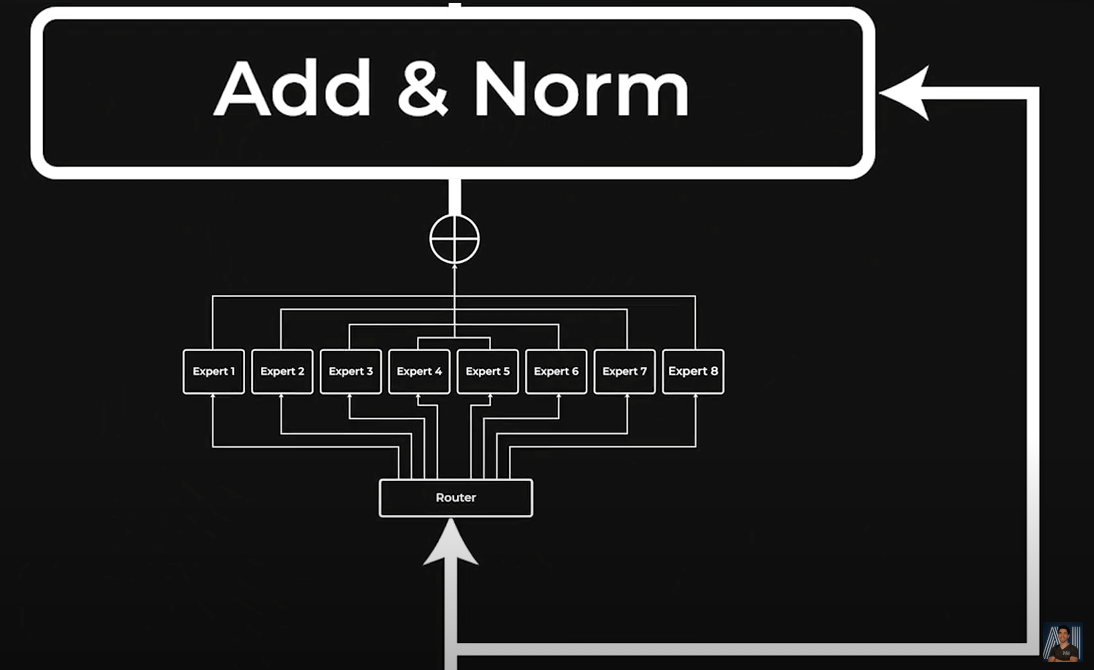
Couche “Feed Forward” du block Transformer remplacée avec les experts.
Ce mécanisme d'attention a fait beaucoup de bruit depuis l’article Attention is All You Need en 2017, et pour une bonne raison : on n'a presque besoin que de cela pour comprendre le contexte. Néanmoins, vous avez besoin d'autre chose pour aboutir à ces énormes modèles puissants de milliards et de miliards de paramètres. Ces modèles transformeurs sont si gros parce qu'ils empilent plusieurs blocs de transformeurs les uns sur les autres. Mais pour l'instant, nous avons vu une étape d'attention mélangeant le contenu dans une nouvelle forme. Cela aide à comprendre le contexte, mais maintenant nous avons perdu nos connaissances pour chaque token eux-même.
Pour résoudre ce problème, nous avons besoin d'une sorte de fonction capable de traiter chacun de ces nouveaux tokens transformés individuellement pour aider le modèle à mieux comprendre cette partie spécifique de l'information. C'est ce qu'on appelle un réseau à feed forward ou un réseau entièrement connecté. Mais le nom n'est pas important. Ce qui est important, c'est qu'il utilise la même fonction ou le même réseau, similaire à l'attention, mais pour un token spécifique individuel afin de les parcourir tous un par un pour le comprendre et le transformer pour l'étape suivante. Ici, par prochaine étape, je veux dire aller plus loin dans le réseau, envoyant essentiellement à la prochaine couche d'attention. C'est exactement ce que notre cerveau fait avec l'information entrant dans notre oreille ou nos yeux jusqu'à ce qu'elle soit comprise et que nous générions une réponse, qu'il s'agisse de répondre ou d'agir. On traite l'information et la transformons en une nouvelle forme. Les transformeurs font la même chose.
Heureusement, on peut faire cette étape en parallèle et ne pas avoir à attendre de traiter tous les tokens un par un. Néanmoins, cela devient un goulot d'étranglement de calcul important, car nous devons travailler avec de grandes quantités de nombres, et ce, en parallèle. C'est là qu'intervient le mélange d'experts. Nos experts ici sont essentiellement différents réseaux complètement connectés au lieu d'un seul. C'est tout. Cela signifie qu'ils peuvent être des réseaux plus petits et plus efficaces, et fonctionner sur différents GPU en parallèle, tout en ayant encore plus de paramètres au total ! Cela permet même aux experts d'apprendre des choses différentes et de se compléter mutuellement. Que des avantages. Dans le cas de Mixtral, il y a 8 experts comme ça.
Pour que cela fonctionne, il suffit d'ajouter un autre mini-réseau appelé routeur, dont le seul travail est d'apprendre à quel expert envoyer chaque token.
Donc, une couche de mélange d'experts ne remplace que notre couche complètement connecté par 8 d'entre elles. C'est pourquoi ce n'est pas vraiment 8 modèles, mais plutôt 8 fois cette partie spécifique de l'architecture du transformeur. Et tout cela pour le rendre plus efficace.
Dans ce cas, Mixtral a décidé de n'utiliser que 2 experts sur les 8 pour chaque token. Ils ont déterminé grâce à des expérimentations que c'était la meilleure combinaison pour les résultats et l'efficacité. Donc, le routeur envoie essentiellement chaque token à deux experts, fait cela pour tous les tokens et recombine tout après. Encore une fois, simplement pour gagner en efficacité et en performance, trouvant que 2 experts fonctionnaient mieux qu’un seul ou plusieurs.

Les mélanges d’experts. Image par Mistral AI.
Je veux partager une excellente analogie pour comprendre ce processus de Gregory sur Medium. Pensez à un hôpital avec divers services spécialisés (nos experts). Chaque patient (token d'entrée) est dirigé vers le service approprié par la réception (notre réseau de routeurs) en fonction de ses symptômes (notre liste de nombres, valeurs des tokens). Tout comme tous les services ne sont pas impliqués dans le traitement de chaque patient, tous les experts d'un mélange d'experts ne sont pas utilisés pour chaque entrée.
Voilà ! Nous empilons simplement ces blocs de transformeurs ensemble et nous nous retrouvons avec un modèle ultra-puissant à des milliards de paramètres appelé GPT-4, ou Mixtral 8x7B dans ce cas. Et ici, le nombre réel de paramètres n'est pas de 8x7 ou 56 milliards. En fait, il est plus petit, environ 47 milliards, car ce n'est qu'une partie du réseau qui possède ces experts multiples, et nous n'avons besoin que de 2 experts à la fois pour une transformation de token, ce qui conduit à environ 13 milliards de paramètres actifs lorsque nous l'utilisons pour un seul token à la fois ! Donc, environ un quart du nombre total seulement.
Maintenant, pourquoi ai-je commencé cette vidéo en disant qu'ils n'étaient pas vraiment des experts ? Parce que ces 8 « experts » ne sont en réalité pas du tout des experts. Mistral a étudié leur comportement et a conclu que le routeur envoyant les tokens à ces « experts » le faisait de manière assez aléatoire, ou du moins, sans modèle observable. Ici, nous voyons nos 8 experts et 8 types de données, qu'il s'agisse de code, de mathématiques, de langues différentes, etc., et ils sont malheureusement clairement distribués au hasard. Aucun expert ne s'est concentré sur les mathématiques ou le code comme on peut l’imaginer. Ils ont tous aidé un peu pour tout. Donc, ajouter ces « experts » aide, mais pas de la manière attendue. Cela aide, car il y a plus de paramètres et nous pouvons les utiliser plus efficacement.
Ce qu'ils ont trouvé d'intéressant, c'est que le même expert semble être utilisé lors du démarrage d'une génération de nouvelle ligne, ce qui est assez intéressant, mais pas très utile comme conclusion d'une analyse !
Au fait, l'approche du mélange d'experts n'a rien de nouveau, comme pour la plupart des techniques que nous faisons en IA. Celui-ci vient d'il y a un certain temps. Par exemple, il s'agit d'un article de 2013 avec un auteur que vous devriez reconnaître impliqué chez OpenAI, développé sur l'idée existante d'un mélange d'experts travaillant avec un tel mécanisme de routing. Nous venons juste d'appliquer cette idée aux transformeurs et d'agrandir les choses, comme nous le faisons toujours !
Et voilà ! Bien sûr, l'architecture globale du transformeur contient de nombreux autres composants importants et est un peu plus compliquée que ce que j'ai montré ici, mais j'espère que ce concept de mélange d'experts est un peu plus clair maintenant et qu'il a brisé certaines croyances sur le fait qu'il s'agisse de véritables « experts », et j'espère surtout ne pas voir encore un autre calcul rapide multipliant 8 par 7 pour trouver le nombre total de paramètres d'un modèle !
Merci d'avoir regardé toute la vidéo et je vous verrai dans la prochaine pour plus d'explications sur l'IA !