Le Développeur LLM : Le Pont Entre Logiciel 1.0, 2.0 et 3.0
Regardez la vidéo!
Le besoin de nouvelles compétences et de nouveaux rôles
L’émergence des grands modèles de langage (LLM) ne concerne pas seulement la technologie ; elle touche également les personnes. Pour exploiter leur plein potentiel, nous avons besoin d’une main-d'œuvre dotée de nouvelles compétences et de nouveaux rôles. Cela inclut les développeurs spécialisés en LLM, qui comblent le fossé entre le développement logiciel, l’ingénierie de l’apprentissage automatique et l’ingénierie des invites.
Les développeurs logiciels se concentrent sur la création d’applications traditionnelles en utilisant du code explicite. Les ingénieurs en apprentissage automatique (Machine Learning Engineers) se spécialisent dans l’entraînement de modèles à partir de zéro et leur déploiement à grande échelle. Les développeurs LLM, en revanche, évoluent dans un espace intermédiaire. Ils personnalisent des modèles de base existants, utilisent l’ingénierie des invites pour orienter les résultats, et construisent des pipelines intégrant des techniques telles que RAG, le peaufinage et les systèmes basés sur des agents.
Devenir un excellent développeur LLM exige plus que des connaissances techniques. Cela implique de cultiver des compétences entrepreneuriales et de communication, de comprendre les compromis économiques, et d’apprendre à intégrer l’expertise du secteur dans des outils et des flux de travail. Ces développeurs doivent également exceller dans l’itération de solutions, la prévision des modes d’échec et l’équilibre entre performances, coût et latence.
La demande pour les développeurs LLM augmente rapidement, et comme ce domaine est très récent, il y a très peu d’experts. C’est donc le moment idéal pour acquérir ces compétences et se positionner à l’avant-garde de cette évolution.
Comment les développeurs LLM se distinguent-ils des développeurs logiciels et des ingénieurs ML ?
Construire sur un modèle de base existant avec des capacités intégrées permet de gagner énormément de temps de développement et de lignes de code par rapport au développement d’applications logicielles traditionnelles. Cela réduit également les besoins en expertise en ingénierie des données, en apprentissage automatique, en infrastructure et en coûts d’entraînement des modèles, comparé à l’entraînement de modèles d’IA de zéro.
Nous pensons que, pour maximiser la fiabilité et les gains de productivité d’un produit final, les développeurs LLM sont essentiels et doivent concevoir des applications personnalisées et fiables basées sur des modèles LLM de base. Cependant, cela nécessite la création et l’enseignement de nouvelles compétences et de nouveaux rôles, comme les développeurs LLM et les ingénieurs en invites (ou prompts). Et les grands développeurs LLM sont en très faible nombre, surtout en comparaison avec les nombreux auto-proclamés ingénieurs en invites!
Alors, comment les développeurs LLM se distinguent-ils des développeurs logiciels et des ingénieurs ML ?

Les développeurs logiciels opèrent principalement dans le cadre du “Logiciel 1.0”, en se concentrant sur le codage d’instructions explicites et basées sur des règles pour piloter des applications. Ces rôles sont généralement spécialisés par langage et compétences logiciels. De nombreux développeurs ont des années d’expérience dans leur domaine et ont développé de solides capacités de résolution de problèmes et une intuition pour organiser et faire évoluer le code, ainsi qu’utiliser les outils et bibliothèques les plus appropriés.
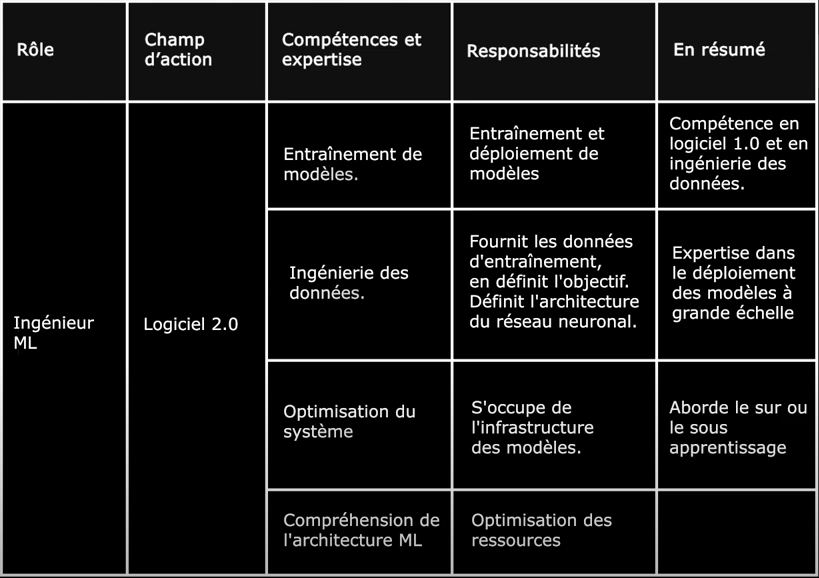
Les ingénieurs en apprentissage automatique se concentrent sur l’entraînement et le déploiement de modèles d’IA (ou “Logiciel 2.0”). Le “code” du Logiciel 2.0 est abstrait et stocké dans les poids d’un réseau neuronal, où les modèles se “programment” eux-mêmes en s’entraînant sur des données. Le rôle de l’ingénieur consiste à fournir les données d’entraînement, souvent en collaboration avec des experts en données, à définir l’objectif d’entraînement et l’architecture du réseau neuronal à utiliser. En pratique, ce rôle nécessite encore de nombreuses compétences en Logiciel 1.0 et en ingénierie des données pour développer un système complet. Les rôles peuvent être spécialisés, mais l’expertise réside dans l’entraînement des modèles, le traitement des données ou le déploiement des modèles dans des environnements de production à grande échelle. Ils préparent les données d’entraînement, gèrent l’infrastructure des modèles, et optimisent les ressources pour entraîner des modèles performants tout en abordant des problèmes comme le sur-apprentissage ou le sous-apprentissage.

Les ingénieurs en invites se concentrent sur l’interaction avec les LLMs en utilisant le langage naturel (ou “Logiciel 3.0”). Ce rôle consiste à affiner les sorties des modèles de langage en optimisant les invites, nécessitant une forte intuition sur les forces et limites des LLMs. Ils fournissent des données aux modèles et optimisent les techniques d’invite et les performances sans nécessiter de compétences en codage. L’ingénierie des invites est souvent une compétence nouvelle plutôt qu’un rôle complet - et beaucoup devront développer cette compétence en complément de leurs rôles existants dans de nombreux secteurs pour rester compétitifs. Les techniques précises d’invite évolueront, mais au cœur de cette compétence, il s’agit simplement de développer une intuition pour utiliser, instruire et interagir avec les LLMs en langage naturel afin d’obtenir des résultats productifs et de tirer parti de la technologie.
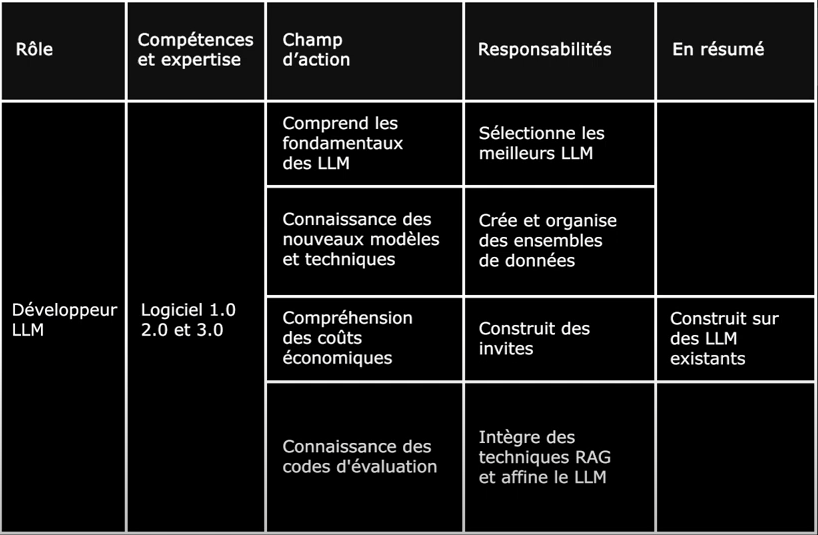
Les développeurs LLM font le lien entre le Logiciel 1.0, 2.0 et 3.0, et sont particulièrement bien placés pour personnaliser les modèles de langage avec des données et instructions spécifiques à un domaine. Ils sélectionnent les meilleurs LLMs pour une tâche donnée, créent et organisent des ensembles de données sur mesure, conçoivent des invites, intègrent des techniques avancées comme RAG, et affinent les LLMs pour maximiser fiabilité et capacité. Ils exploitent le meilleur des technologies disponibles plutôt que de repartir de zéro, ce que la plupart des entreprises, à l’exception de Google et Meta, ne peuvent de toute façon pas se permettre. Ce rôle nécessite de comprendre les fondamentaux et techniques des LLMs, tout en restant informé des nouveaux modèles, des méthodes d’évaluation et des compromis économiques pour évaluer la pertinence d’un LLM à un flux de travail cible. Il exige également de comprendre l’utilisateur final et les cas d’usage, car ils interagiront avec le LLM d’une manière ou d’une autre. Vous intégrez plus d’expertise humaine du secteur dans le logiciel avec des pipelines LLM - et pour bénéficier réellement de la personnalisation, vous devez mieux comprendre les subtilités du problème à résoudre. Bien que le rôle utilise le Logiciel 1.0 et 2.0, il nécessite généralement moins de théorie fondamentale en apprentissage automatique et en informatique.
Nous pensons que les développeurs logiciels et les ingénieurs en apprentissage automatique peuvent rapidement apprendre les principes fondamentaux du développement LLM et commencer à se reconvertir dans ce nouveau rôle. Cela est particulièrement facile si vous maîtrisez déjà Python ou des langages de programmation similaires. Cependant, devenir un excellent développeur LLM nécessite de cultiver une gamme surprenante de compétences nouvelles, notamment des compétences entrepreneuriales.
Cela implique de développer une intuition pour les forces et faiblesses des LLMs, d’apprendre à améliorer et évaluer un pipeline LLM de manière itérative, de prévoir les échecs probables des données ou du LLM, et d’équilibrer les compromis entre performances, coût et latence.
Les pipelines LLM peuvent également être développés plus facilement dans un processus "full stack”, incluant Python, même pour le front-end, ce qui peut nécessiter de nouvelles compétences pour les développeurs précédemment spécialisés. Le rythme rapide des progrès des LLMs exige également une plus grande agilité pour rester à jour avec les nouveaux modèles et techniques.
Le rôle de développeur LLM intègre également de nombreuses compétences non techniques, comme la prise en compte de la stratégie commerciale et des aspects économiques de votre solution, qui peuvent être étroitement liés à vos choix techniques et de produit. Comprendre vos utilisateurs finaux, les subtilités des données sectorielles et les problèmes à résoudre, ainsi qu’intégrer l’expertise humaine de ce domaine dans votre modèle, sont également des compétences clés.
Enfin, les outils LLM eux-mêmes peuvent parfois être considérés comme des “stagiaires peu fiables” ou des collègues juniors - et les utiliser efficacement nécessite des compétences en “gestion des personnes”.
Cela peut inclure la décomposition des problèmes en composants plus facilement explicables et solvables, puis la fourniture d’instructions claires et infaillibles pour les réaliser. Là encore, cela peut représenter une compétence à acquérir si vous n’avez pas précédemment dirigé une équipe.
Nombre de ces nouvelles compétences et intuitions doivent être acquises par l’expérience. Nous visons à enseigner certaines de ces compétences, processus de réflexion et astuces dans ce cours - tandis que votre projet pratique vous permet de développer et de démontrer votre propre expertise.
Si vous avez trouvé ce blogue utile, n’oubliez pas de consulter notre cours complet, où nous vous apprenons à construire des pipelines LLM prêts pour la production et à vous préparer pour l’avenir du travail piloté par l’IA!