Qu'est-ce que l'IA centrée sur les données (Logiciel 2.0) ?
C’est exactement la même chose qui rend GPT-3 et Dalle puissants : les données.
Les données sont cruciales dans notre domaine, et nos modèles sont extrêmement gourmands. Ces grands modèles, qu'il s'agisse de modèles de langage pour GPT ou de modèles d'image pour Dalle, nécessitent tous la même chose : beaucoup trop de données.
Malheureusement, plus vous avez de données, mieux c'est. Vous devez donc grossir ces modèles, en particulier pour les applications du monde réel. Les modèles plus volumineux peuvent utiliser des ensembles de données plus volumineux pour s'améliorer, mais uniquement si les données sont de haute qualité. Nourrir ces modèles d’images qui ne représentent pas le monde réel ne servira à rien et dégradera même la capacité de généralisation du modèle. C'est là qu'intervient l'IA centrée sur les données (Data-centric AI).
L'IA centrée sur les données, également appelée logiciel 2.0, n'est qu'une façon élégante de dire que nous optimisons nos données pour maximiser les performances du modèle au lieu d'être centrée sur le modèle, où vous modifieriez simplement les paramètres du modèle sur un ensemble de données fixe. Bien sûr, les deux doivent être faits pour obtenir les meilleurs résultats possibles, mais les données sont de loin le plus gros joueur ici.
Dans cet article, en partenariat avec Snorkel, je couvrirai ce qu'est l'IA centrée sur les données et passerai en revue quelques grandes avancées dans le domaine. Vous comprendrez rapidement pourquoi les données sont si importantes dans l'apprentissage automatique, qui est la mission de Snorkel. Prenant une citation de leur article de blog lié ci-dessous:
« Les équipes passaient souvent du temps à écrire de nouveaux modèles au lieu de comprendre leur problème et son expression dans les données plus en profondeur. [...] Écrire un nouveau modèle [est] un beau refuge pour se cacher de la complexité derrière la compréhension des vrais problèmes.
Et c'est ce que cet article vise à combattre. En une phrase : l'objectif de l'IA centrée sur les données est d'encoder les connaissances de nos données dans le modèle en maximisant la qualité des données et les performances du modèle.
Présentation de l'Idée de Programmation de Données (Data Programming)
Tout a commencé en 2016 à Stanford avec un article intitulé "Data Programming: Creating Large Training Sets, Quickly" introduisant un paradigme pour annoter les ensembles de données d'entraînement à l’aide de programmation plutôt qu'à la main. C'était il y a une éternité en termes d'ère de la recherche en IA.
Comme vous le savez certainement, les meilleures approches à ce jour utilisent l'apprentissage supervisé, un processus dans lequel les modèles s'entraînent sur les données et les annotations et apprennent à reproduire ces annotations lorsqu'on leur donne les données. Par exemple, vous alimentez un modèle avec de nombreuses images de chiens et de chats, avec les annotations respectives (chien, chat), et demandez au modèle de découvrir ce qui est dans l'image, puis utilisez la rétropropagation pour entraîner le modèle en fonction de sa réussite. Si vous n'êtes pas familier avec la rétropropagation, je vous invite à faire une petite pause pour regarder mon explication d'une minute et revenir là où vous vous étiez arrêté.

À mesure que les ensembles de données deviennent de plus en plus volumineux, il devient de plus en plus difficile de les organiser et de supprimer les données nuisibles pour permettre au modèle de se concentrer uniquement sur les données pertinentes. Vous ne voulez pas entraîner votre modèle à détecter un chat alors qu'il s'agit d'une mouffette, ça pourrait plutôt mal finir. Lorsque je fais référence à des données, gardez à l'esprit qu'il peut s'agir de n'importe quel type de données : tabulaire (comme Excel), images, texte, vidéos, etc.
Maintenant que nous pouvons facilement télécharger un modèle pour n'importe quelle tâche, le passage à l'amélioration et à l'optimisation des données est inévitable. La disponibilité des modèles, la taille des récents ensembles de données et la dépendance des données de ces modèles sont les raisons pour lesquelles un tel paradigme pour annoter les ensembles de données de formation avec de la programmation devient essentiel.
Le principal problème vient du fait d'avoir des annotations pour nos données. Il est facile d'avoir des milliers d'images de chats et de chiens, mais il est beaucoup plus difficile de savoir quelles images ont un chien et lesquelles ont un chat, et encore plus difficile d'avoir leurs emplacements exacts dans l'image pour les tâches de segmentation, par exemple.

Ce premier article présente un algorithme de programmation de données dans lequel l'utilisateur, ou l'ingénieur ML/scientifique des données, exprime des stratégies de supervision faibles en tant que fonctions d’annotations à l'aide d'un modèle génératif qui annote des sous-ensembles de données. Les chercheurs ont constatés que "la programmation de données peut être un moyen plus simple pour les non-experts de créer des modèles d'apprentissage automatique lorsque les données de formation sont limitées ou indisponibles. »
En bref : ils montrent comment l'amélioration des données sans trop de travail supplémentaire, tout en gardant le même modèle, améliore les résultats, ce qui était un tremplin désormais évident, mais essentiel, pour le domaine. C'est un article de base vraiment intéressant dans ce domaine et vaut la peine d'être lu!
Le Système Open Source “Snorkel”
Le deuxième article que nous couvrons ici s'intitule "Snorkel: Rapid Training Data Creation with Weak Supervision". Cet article, publié un an plus tard également à l'Université de Stanford, présente une interface flexible pour écrire des fonctions d’annotations basées sur l'expérience. Partant de l'idée que les données d'entraînement sont de plus en plus volumineuses et difficiles à annoter, provoquant un goulot d'étranglement dans les performances des modèles, ils introduisent Snorkel, un système qui implémente l'article précédent dans un système de bout en bout (end-to-end). Ce système permet aux experts, les personnes qui comprennent le mieux les données, de définir facilement des fonctions d’annotations pour annoter automatiquement les données, au lieu de faire des annotations manuelles. Ce système permet ainsi de créer des modèles 2,8 fois plus rapidement tout en augmentant les performances prédictives de 45,5 % en moyenne.
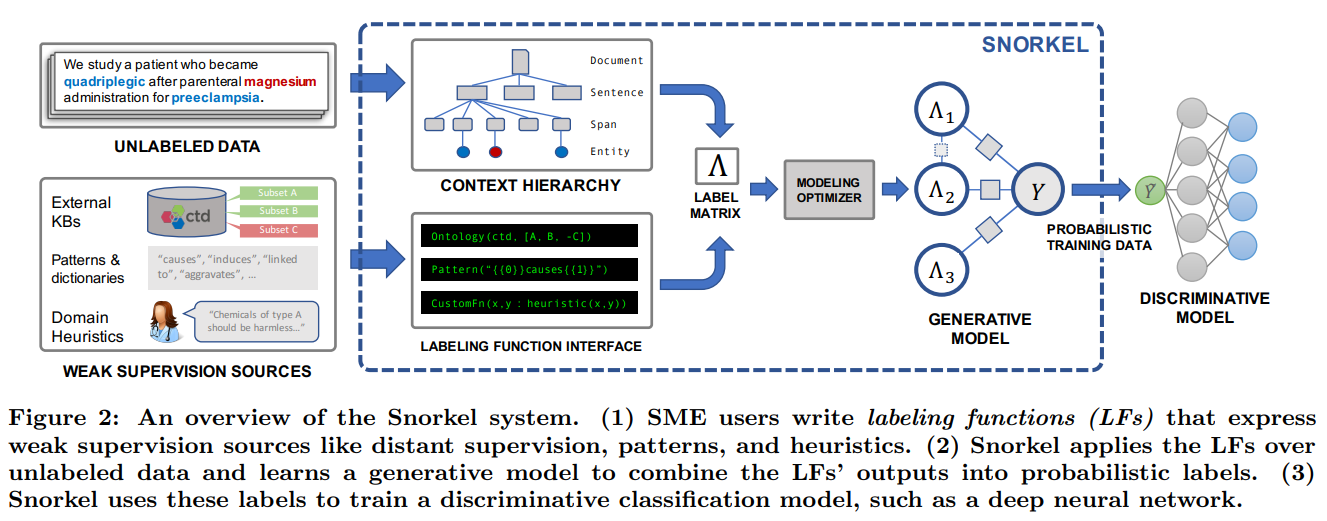
Donc, encore une fois, au lieu d'écrire des annotations, les utilisateurs ou les experts détenant les connaissances écrivent des fonctions d’annotations. Ces fonctions donnent simplement des informations aux modèles sur les caractéristiques à rechercher ou tout ce que l'expert utiliserait pour classer les données, aidant le modèle à suivre le même processus. Ensuite, le système applique les fonctions d’annotations nouvellement écrites sur nos données non annotées et entraîne un modèle génératif pour combiner les annotations de sortie en annotations probabilistes qui sont ensuite utilisées pour entraîner notre réseau de neurone profond final pour la tâche visée. Snorkel fait tout cela par lui-même, facilitant tout ce processus pour la première fois.
L’IA Centrée sur les Données - Ou Logiciel 2.0

Notre dernier article également de Stanford, un an plus tard, présente le logiciel 2.0. Ce document d'une page avance une fois de plus la même approche centrée sur les données d'apprentissage en profondeur en utilisant des fonctions d’annotation pour produire des annotations d’entraînement pour de grands ensembles de données non annotés et former notre modèle final, ce qui est particulièrement utile pour d'énormes ensembles de données récupérés sur Internet comme ceux utilisés dans les applications Google comme YouTube, Google Ads, Gmail, etc., s'attaquant au manque de données annotées à la main.
Bien sûr, ceci n'est qu'un aperçu des progrès et de la direction de l'IA centrée sur les données, et je vous invite fortement à lire les informations dans la description ci-dessous pour avoir une vue complète de l'IA centrée sur les données, d'où ça vient, et où ça se dirige.
Je tiens également à remercier Snorkel d'avoir sponsorisé cet article et je vous invite à consulter leur site Web pour plus d'informations (tous les liens se trouvent ci-dessous). Si vous n'avez jamais entendu parler de Snorkel auparavant, vous avez déjà utilisé leur approche dans de nombreux produits comme YouTube, Google Ads, Gmail, etc.!
Merci d’avoir lu,
Louis
Références (en anglais)
Snorkel AI a commencé avec l'IA centrée sur les données alors qu'ils travaillaient au Stanford AI Lab en 2015, introduisant l'idée de la programmation de données en 2016, suivie du système open source Snorkel en 2017, et en 2018, l'IA centrée sur les données ou le logiciel 2.0 a été créé comme la nouvelle façon de créer des applications d'IA.
►Data-centric AI: https://snorkel.ai/data-centric-ai
►Weak supervision: https://snorkel.ai/weak-supervision/
►Programmatic labeling: https://snorkel.ai/programmatic-labeling/
►Curated list of resources for Data-centric AI: https://github.com/hazyresearch/data-centric-ai
►Learn more about Snorkel: https://snorkel.ai/company/
►From Model-centric to Data-centric AI - Andrew Ng: https://youtu.be/06-AZXmwHjo
►Software 2.0: https://hazyresearch.stanford.edu/blog/2020-02-28-software2
►Paper 1: Ratner, A.J., De Sa, C.M., Wu, S., Selsam, D. and Ré, C., 2016. Data programming: Creating large training sets, quickly. Advances in neural information processing systems, 29.
►Paper 2: Ratner, A., Bach, S.H., Ehrenberg, H., Fries, J., Wu, S. and Ré, C., 2017, November. Snorkel: Rapid training data creation with weak supervision. In Proceedings of the VLDB Endowment. International Conference on Very Large Data Bases (Vol. 11, No. 3, p. 269). NIH Public Access.
►Paper 3: Ré, C. (2018). Software 2.0 and Snorkel: Beyond Hand-Labeled Data. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.
►Ma Newsletter (anglais): https://www.louisbouchard.ai/newsletter/