L'IA est-elle l'avenir de la conception de jeux vidéo?

Ce que vous voyez ici est une séquence tirée d'un jeu vidéo très populaire appelé GTA-5. Ça semble déjà assez réaliste, mais il est toujours évident qu'il s'agit d'un jeu vidéo. Maintenant, regardez ceci...

Non, ce n'est pas la vraie vie. C'est toujours la même scène de GTA-5 qui est passée par un nouveau modèle utilisant l'intelligence artificielle pour améliorer ses graphismes et le faire ressembler davantage au monde réel! Les chercheurs d'Intel Labs ont publié cet article intitulé “Enhancing Photorealism Enhancement”. Et si vous pensez que cela est "juste un autre GAN", en prenant une photo du jeu vidéo comme entrée et en le changeant en suivant le style du monde naturel, laissez-moi changer votre avis.
Ils ont travaillé sur ce modèle pendant deux ans pour le rendre extrêmement robuste. Il peut être appliqué directement au jeu vidéo et transformer chaque image pour qu'elle paraisse beaucoup plus naturelle. Imaginez simplement les possibilités où vous pouvez mettre beaucoup moins d'efforts dans le graphisme du jeu, le rendre super stable et complet, puis améliorer le style à l'aide de ce modèle. Je pense que c'est une percée massive pour les jeux vidéo, et ce n'est que le premier article attaquant cette même tâche appliquée spécifiquement aux jeux vidéo! Je veux vous poser une question à laquelle vous pouvez peut-être déjà répondre ou attendre la fin de la vidéo pour répondre: Pensez-vous que c'est l'avenir des jeux vidéos?
Si vous voulez plus de temps pour répondre, c'est parfait, passons à l’explication de cette technique. En général, cette tâche est appelée translation d'image à image (voir ci-dessous). En gros, vous prenez une image et la transformez en une autre, souvent en utilisant des GANs, comme je l'ai couvert à plusieurs reprises dans mes articles précédents.

Si vous voulez un aperçu du fonctionnement d'une architecture GAN typique, je vous invite à regarder cette vidéo ci-dessous avant de continuer, car je n'entrerai pas dans les détails de son fonctionnement ici.
Comme je l'ai dit plus tôt, ce modèle est différent de la translation d’image à image de base, car ils utilisent le fait que le modèle est appliqué à un jeu vidéo. Ceci est d'une énorme importance ici car les jeux vidéo ont beaucoup plus d'informations qu'une simple image, alors pourquoi rendre la tâche plus compliquée en réalisant des transformations réalistes en utilisant uniquement l’image visible comme entrée?

Les différentes versions d’une image d’entrée. Richter, Abu AlHaija, Koltun (2021)
Au lieu de cela, ils utilisent beaucoup plus d'informations déjà disponibles pour chaque image du jeu comme les normales de surface, les informations de profondeur, les matériaux, la transparence, l'éclairage et même une carte de segmentation. Carte de segmentation qui vous indique où se trouvent les objets. Je suis sûr que vous pouvez déjà voir comment toutes ces informations supplémentaires peuvent aider dans cette tâche. Toutes ces images sont envoyées à un premier réseau appelé le G-buffer Encoder (voir ci-dessous).

Modèle EPE complet. Richter, Abu AlHaija, Koltun (2021)
Zoomons sur ce "G-buffer Encoder":

Réseau G-Bugger encodeur. Richter, Abu AlHaija, Koltun (2021)
Cet “encodeur G-buffer” prend toutes ces informations, les envoies dans un réseau convolutif classique indépendamment pour extraire et condenser toutes les informations précieuses de ces différentes versions de l'image initiale. Ceci est fait en utilisant plusieurs blocs résiduels, comme vous pouvez le voir ici qui est essentiellement juste une architecture de réseau neuronal convolutif, et plus précisément, une architecture ResNet. Les informations sont extraites en plusieurs étapes, comme vous pouvez le voir. Ceci est fait pour obtenir des informations à différentes étapes du processus. Les informations précoces sont vitales dans cette tâche car elles donnent plus d'informations sur l'emplacement spatial et contiennent des informations plus détaillées. En comparaison, des informations plus profondes dans le réseau sont essentielles pour comprendre l'image globale et son style. Une combinaison d'informations à la fois précoces et profondes est donc très puissante lorsqu'elle est utilisée correctement!
Ensuite, toutes ces informations ici, appelées “G-buffer features” (voir l’image complète du modèle affichée plus tôt dans cet article), sont envoyées à un autre réseau avec l'image d'origine du jeu appelée image rendue. Cet autre modèle s'appelle le "Réseau d'amélioration d'image", comme le montré dans l'architecture complète, zoomons également sur celui-ci.
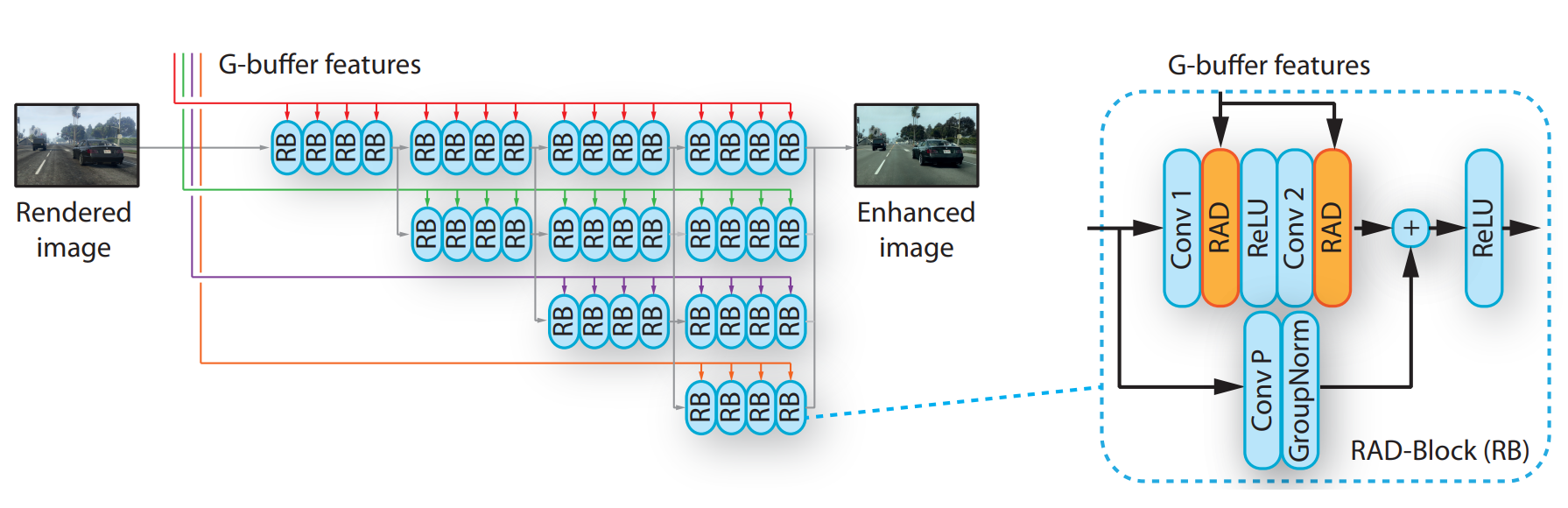
Réseau d’amélioration d’image. Richter, Abu AlHaija, Koltun (2021)
Ici, vous pouvez voir les différentes couleurs représentant les informations du G-buffer extraites de différentes échelles comme nous l'avons vu précédemment, avec la flèche grise montrant le processus pour l'image réelle. Ici encore, vous pouvez voir cela comme une version améliorée des mêmes blocs résiduels que pour l'encodeur g-buffer répété plusieurs fois (à gauche de l’image), mais avec un petit ajustement pour mieux adapter les informations G-buffer avant d'être ajoutées au processus (à droite de l’image). Ceci est fait en utilisant ce qu'ils appellent ici RAD, qui est à nouveau des blocs résiduels, des convolutions et une normalisation.

Modèle EPE complet. Richter, Abu AlHaija, Koltun (2021)
Comme je l'ai mentionné, cette architecture est un peu plus compliquée qu'une simple architecture encodeur-décodeur comme un GAN ordinaire. De même, le processus de formation est également plus élaboré. Ici, vous pouvez voir deux mesures, le score de réalisme et le score LPIPS.

Images réelles vs. Images du jeu. Richter, Abu AlHaija, Koltun (2021)
Le score de réalisme est essentiellement la section GAN du processus d’entraînement. Il compare une image similaire du monde réel à une image de jeu et compare l'image réelle à une image de jeu améliorée. Ce qui permet au modèle d’apprendre à produire une version réaliste et améliorée de l'image du jeu envoyée.

Image améliorée de GTA5. Richter, Abu AlHaija, Koltun (2021)
Alors que ce composant LPIPS est une fonction de perte connue par la communauté de vision fréquemment utilisée pour conserver autant que possible la structure de l'image initiale dans l’image générée. Ceci est réalisé en donnant un score basé sur la différence entre les pixels associés de l'image initiale par rapport à l'image améliorée. Pénaliser le réseau lorsqu'il génère une nouvelle image qui diffère spatialement de l'image d'origine. Ainsi, ces deux mesures collaborent pour améliorer les résultats globaux lors de l’entraînement de cet algorithme.
Bien sûr, comme toujours, vous avez besoin d'un ensemble de données suffisamment grand et représentatif du monde réel et du jeu car il ne générera pas quelque chose que le modèle n'a jamais vu auparavant.
Et maintenant, pensez-vous que ce genre de modèle est l'avenir des jeux vidéo? Votre opinion a-t-elle changé après avoir vu cette vidéo?
Merci d’avoir lu cet article!
Venez discuter avec nous dans notre communauté Discord: ‘Learn AI Together’ et partagez vos projets, vos articles, vos meilleurs cours, trouvez des coéquipiers pour des compétitions Kaggle et plus encore!
Si vous aimez mon travail et que vous souhaitez rester à jour avec l'IA, vous devez absolument me suivre sur mes autres médias sociaux (LinkedIn, Twitter) et vous abonner à ma newsletter hebdomadaire sur l'IA!
Pour supporter mon travail:
La meilleure façon de me soutenir est de souscrire à ma newsletter tel que mentionné précédemment ou de vous abonner à ma chaîne sur YouTube si vous aimez le format vidéo en anglais.
Soutenez mon travail financièrement sur Patreon
Références
Richter, Abu AlHaija, Koltun, (2021), "Enhancing Photorealism Enhancement", https://intel-isl.github.io/PhotorealismEnhancement/