Générer de la musique avec l'IA !
J’ai récemment couvert un modèle capable d'imiter la voix de quelqu'un appelé VALL-E. Faisons un pas de plus dans la direction créative avec cette nouvelle IA appelée MusicLM. MusicLM permet de générer de la musique à partir d'une description textuelle, que je vous invite à écouter sur leur site ou dans ma vidéo (en anglais) afin de comprendre ce que je veux dire par “faire un pas de plus”…
En supposant que vous ayez pris le temps d'écouter certaines des chansons… C'est cool, non ? Ces pièces que vous avez entendues ont été entièrement générées par l'IA ! Automatiquement!
Encore plus intéressant que d'écouter quelques exemples supplémentaires, c'est de comprendre comment cela fonctionne ; plongeons dans ce qu'est cette IA !
Alors, comment ont-ils fait cela?
Eh bien, comme pour la plupart des modèles récents, c'était en prenant le meilleur de plusieurs approches, et les regroupants.
Plus précisément, ils mentionnent que leur approche est très similaire à DALLE 2, dont j'ai déjà parlé sur ma chaîne, mais avec une différence qu'il génère de la musique plutôt que des images et utilise des modèles basés sur Transformer au lieu de ceux basés sur la diffusion.

Architecture DALLE-2. Image de l'article DALLE-2.
Alors revenons un peu en arrière...
Que devons-nous faire ici ?
1. Nous devons traiter le texte de manière à ce que la machine puisse le comprendre.
2. Nous devons comprendre ce texte.
3. Nous devons générer une nouvelle piste musicale inédite qui signifie relativement la même chose que cette entrée de texte.
Ce sont essentiellement les mêmes étapes qu'avec DALLE et d'autres modèles de génération d'images : nous prenons du texte, le comprenons, puis générons une image qui représente ce texte dans une autre modalité que les humains comprennent.
Entrons dans ces étapes une par une…
Tout d'abord, nous devons traiter le texte de manière à ce que la machine puisse le comprendre.
Comment fait-on cela?
Eh bien, nous le faisons en prenant un modèle formé avec beaucoup de paires de texte et de son qui apprend à représenter les deux modalitées (texte et son) de manière similaire dans son espace encodé (rectangle bleu ci-bas). Il apprend essentiellement à transformer les deux modalitées en représentations similaires dans sa propre langue. Les modèles de génération d’images font la même chose, si vous avez vu mes vidéos sur le sujet, où nous voulons que notre texte soit le même qu'une image le représentant. Cela se fera grâce à un long processus de formation avec beaucoup d'exemples. Dans notre cas, ce modèle spécifique s'appelle MuLan :
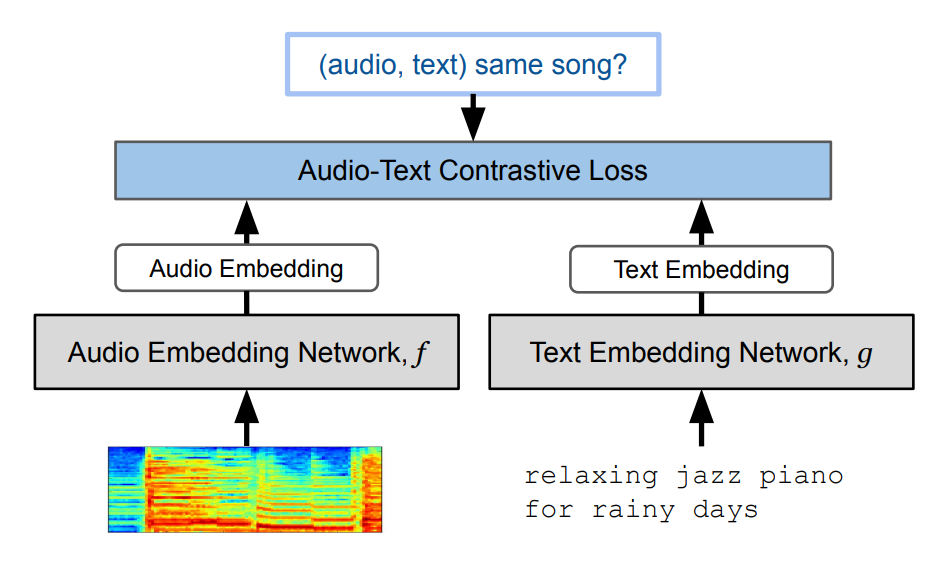
Image tirée de l'article MuLan.
Ensuite, comme je l'ai dit, nous devons comprendre ce texte. Cela se fait de manière séquentielle en apprenant des transformations pour passer de notre texte à la représentation audio.

Vue d'ensemble de l'architecture pendant la formation avec nos trois modèles. Image tirée du papier.
Tout d'abord, nous utiliserons un modèle que nous avons formé sur nos exemples musicaux pour apprendre un moyen de mapper nos encodages MuLan, que nous appelons des jetons, en jetons sémantiques. Cela donnera simplement plus d'informations au réseau pour notre transformation audio, ce que nous faisons maintenant.
Nous utilisons tout ce que nous avons : nos jetons de textes de MuLan et nos nouveaux jetons sémantiques basés sur des transformations apprises des musiques d’entraînements et utilisons un troisième modèle, appelé SoundStream, pour créer des jetons acoustiques, prêts à être interprétés par le modèle et générer notre son.
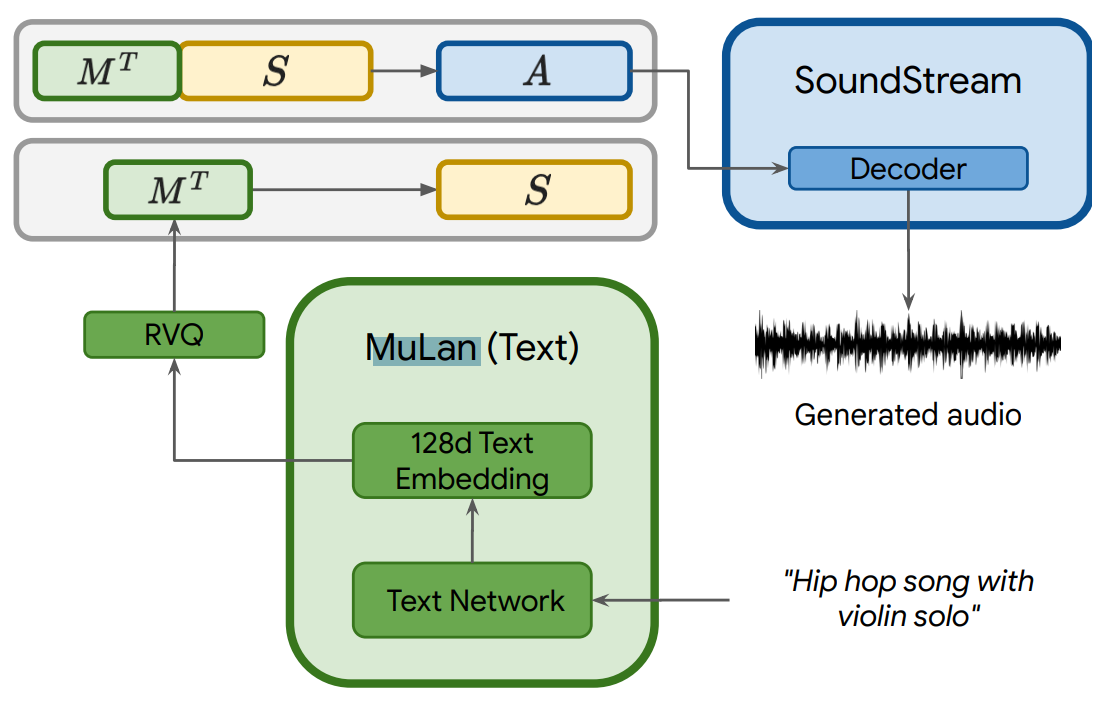
Présentation du modèle pour l'inférence (utilisée en production). Image tirée du papier.
Lorsque la formation est terminée, nous utilisons simplement nos modèles formés pour prendre le texte, le transformer en une représentation significative pour la machine, appliquer nos transformations apprises et utiliser notre dernier sous-modèle (SoundStream) pour générer la chanson souhaitée.
Et voilà !
C'est ainsi que Google Research a pu créer un modèle générant de la musique avec d'aussi bons résultats à partir de simples descriptions textuelles !
Mais ne me croyez pas sur parole; allez écouter quelques exemples sur leur site internet !
Ils publient également MusicCaps, un ensemble de données composé de 5,500 paires musique-texte, avec des descriptions textuelles riches fournies par des experts humains, ce qui aidera sûrement à améliorer les futures approches .
Bien sûr, ce n'était qu'un aperçu de ce nouveau modèle MusicLM. Je vous invite à lire leur article pour plus d'informations.
J'espère que vous avez apprécié cet article, et je vous verrai la semaine prochaine avec un autre article incroyable!
Références
►Agostinelli et al., 2023: MusicLM, https://arxiv.org/pdf/2301.11325.pdf
►Écoutez des résultats: https://google-research.github.io/seanet/musiclm/examples/
►Ma Newsletter (en anglais): https://www.louisbouchard.ai/newsletter/
►Supportez mon travail sur Patreon: https://www.patreon.com/whatsai
►Rejoignez notre communauté sur Discord, “Learn AI Together” (anglais): https://discord.gg/learnaitogether