FlashMLA expliqué simplement : le secret d’efficacité ultime de DeepSeek
Regardez la vidéo pour tous les visuels!
Bonjour à tous ! Ici Louis-François de Towards AI, et si vous avez vu mes précédentes vidéos sur les embeddings, les mixtures d’experts, l'attention à contexte infini ou même ma vidéo sur le CAG ou context caching, vous savez que je suis toujours enthousiaste à l’idée de creuser en profondeur des solutions astucieuses qui rendent les grands modèles de langage plus efficaces et plus rapides.
Accrochez-vous bien, car DeepSeek a publié une nouvelle technique qui fait exactement cela et explique en partie le gros succès derrière l’entraînement de leurs récents modèles super compétitifs : FlashMLA. Découvrons ensemble ce que c’est, pourquoi c’est important et comment cela s’appuie sur des innovations clés dont nous avons déjà parlé.
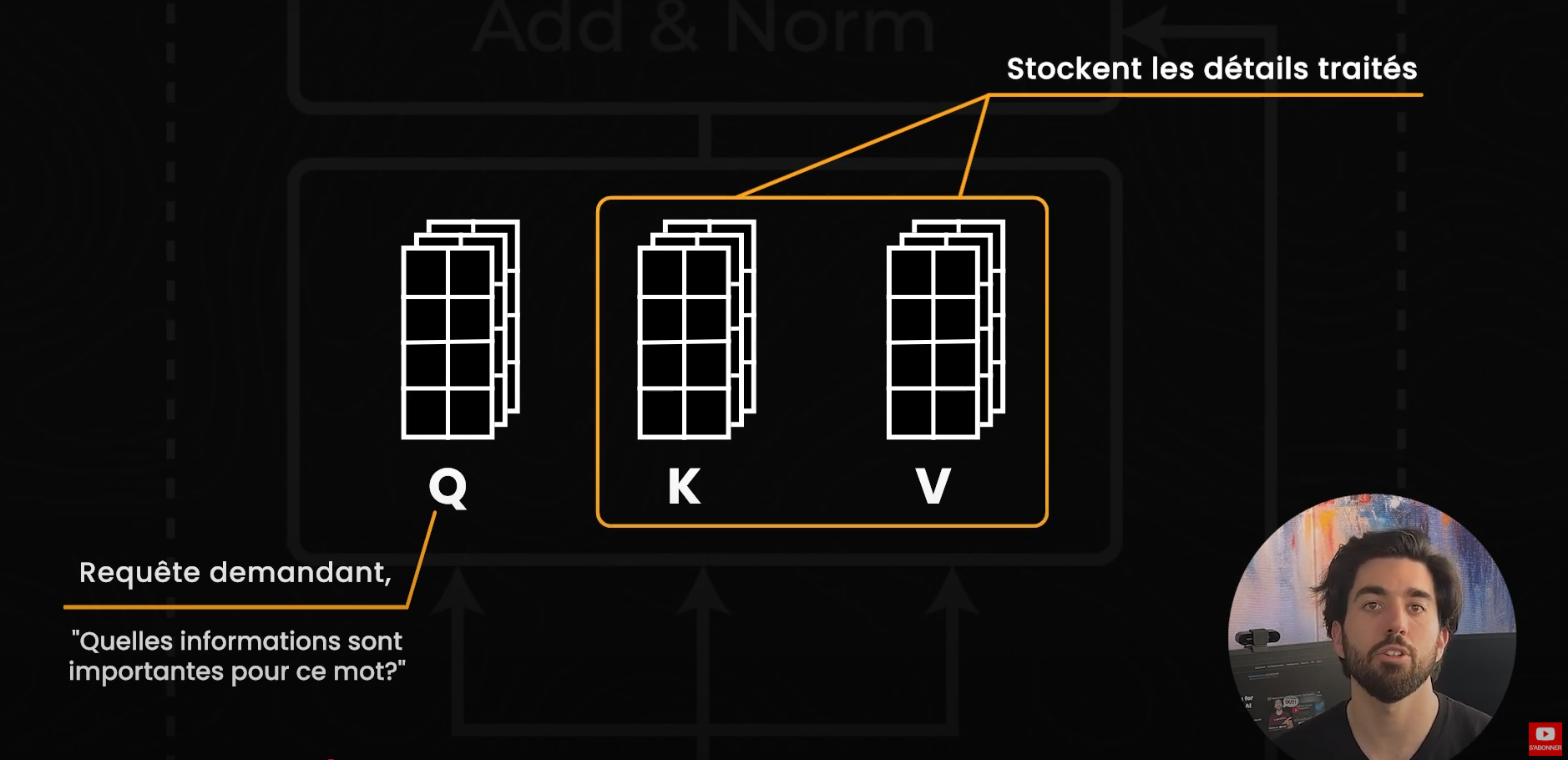
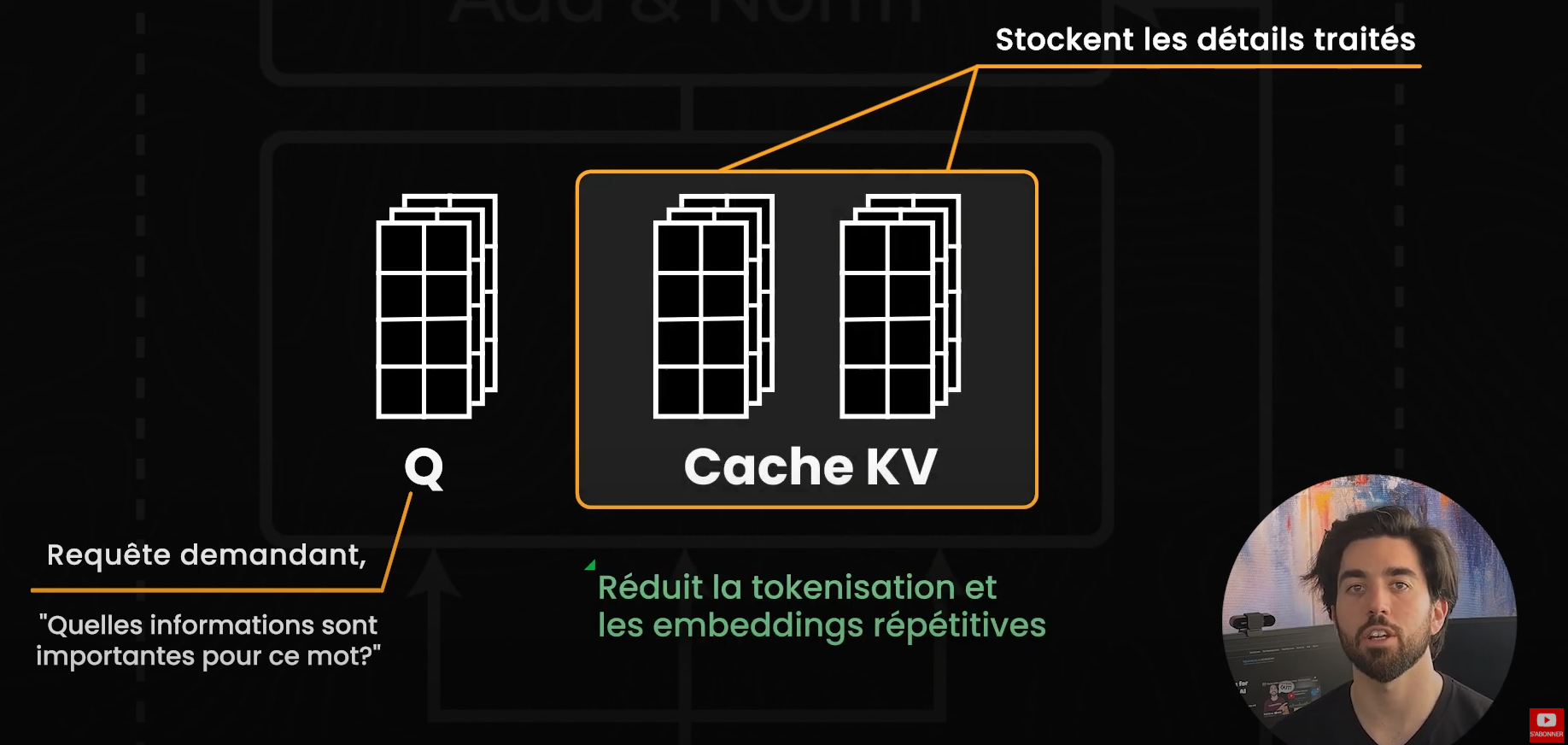
Pour comprendre FlashMLA, commençons par un concept clé des transformeurs : le cache KV. Chaque fois qu'un modèle de langage prédit le prochain mot dans une phrase, il doit décider quelles parties du texte sont les plus pertinentes. Dans un modèle basé sur les transformeurs, « l'attention » est le mécanisme qui identifie ces parties du texte, déterminant ainsi quels mots méritent plus d'attention pour prédire le prochain mot, qui sont ici nos tokens. Pour cela, le modèle génère trois ensembles de nombres, nos embeddings: les Queries, les Keys et les Values (Q, K et V), ou requête, clé et valeur. Imaginez la Query comme une requête demandant : « Quelles informations sont importantes pour ce mot ? », tandis que les Keys et Values contiennent les détails de tout ce que le modèle a déjà traité. Plutôt que de recalculer ces vecteurs pour chaque token, le modèle les stocke dans le cache KV, ce qui accélère les futures recherches et évite des opérations répétitives de tokenisation et d'embedding. (D'ailleurs, j'ai une vidéo complète sur CAG parlant de tout ça plus en profondeur si ça vous intéresse !)

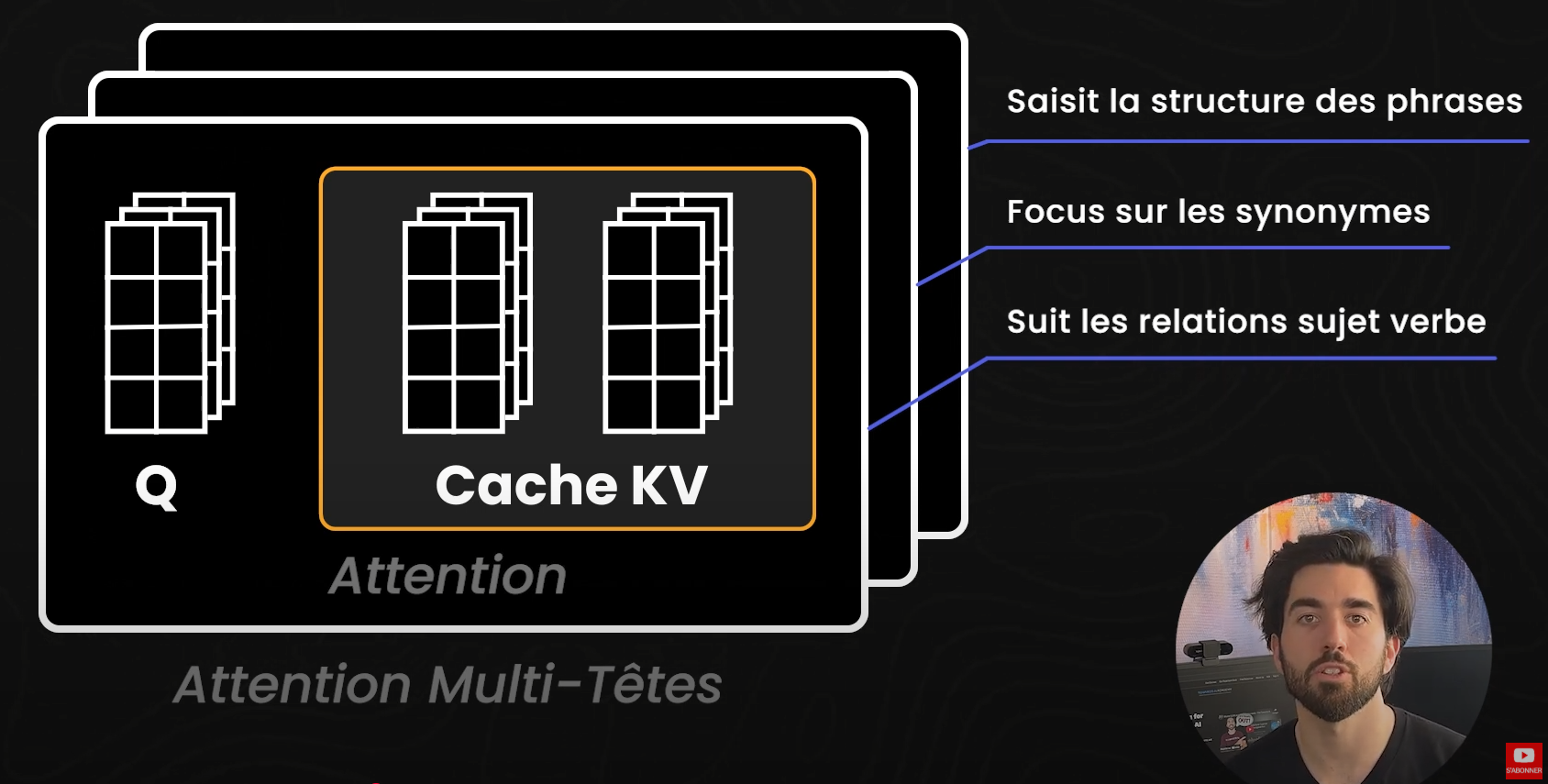
Mais il y a un problème avec ce cache : lorsque le contexte s'allonge, le cache KV grandit également, consommant très rapidement d'énormes quantités de mémoire. Cela se produit parce que les transformeurs n'utilisent pas qu'un seul mécanisme d'attention ; ils utilisent une attention multi-têtes (multi-head attention). Chaque tête analyse le texte sous un angle différent : une pourrait suivre les relations sujet-verbe, une autre pourrait se concentrer sur les synonymes, et une autre encore pourrait saisir la structure des phrases. Bien que cette approche multi-têtes enrichisse la compréhension du modèle, elle signifie aussi que chaque tête a besoin de son propre ensemble de paires KV. Et donc, lors du traitement de contextes plus longs ou de texte en temps réel, ces clés et valeurs distinctes se multiplient, entraînant des besoins énormes en mémoire.

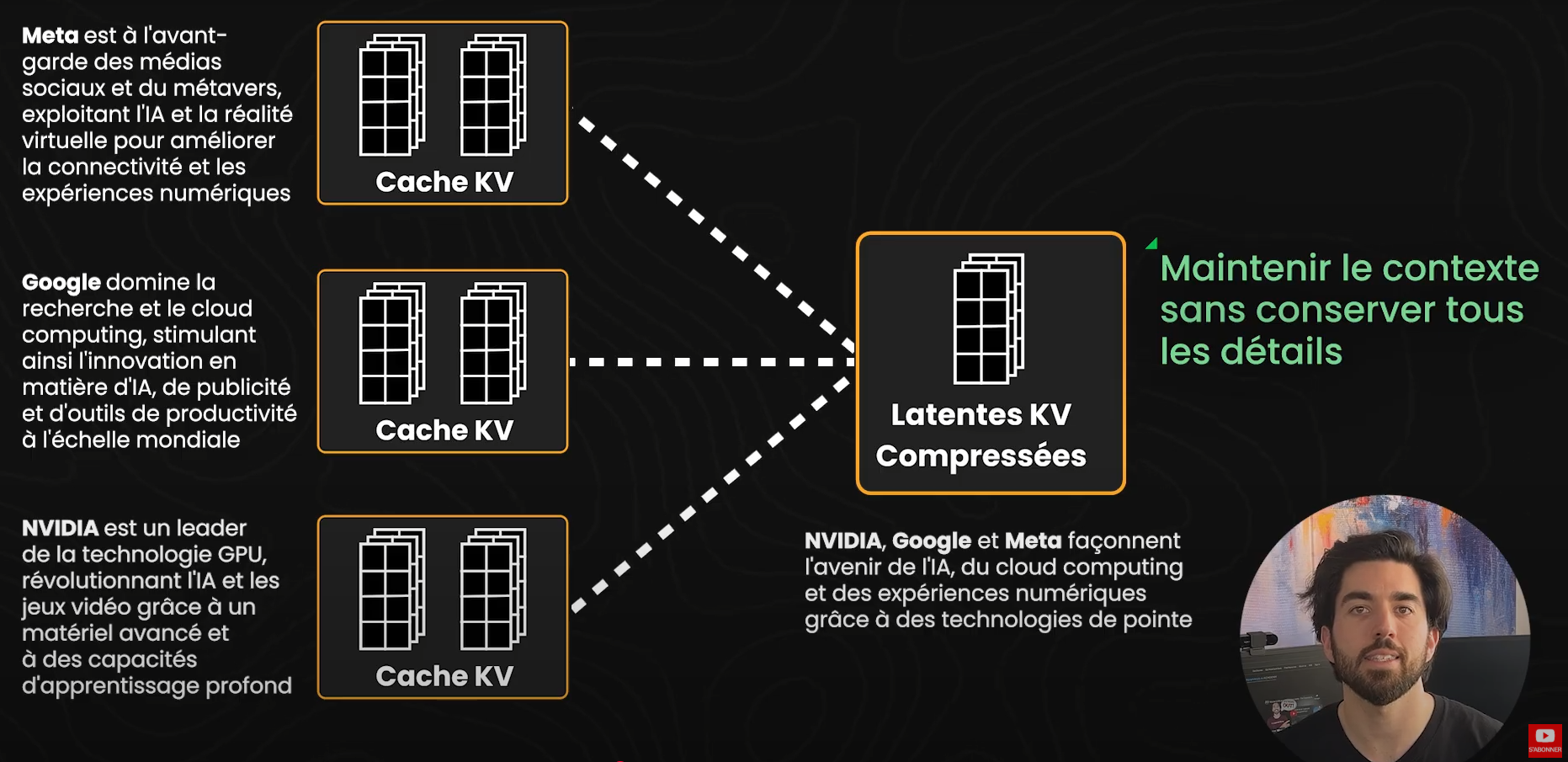
C'est là qu'intervient l'attention latente multi-têtes (Multi-head Latent Attention ou MLA). Au lieu de stocker les Keys et Values détaillées pour chaque token, MLA compresse l’historique d'attention en représentations « latentes » compactes. L’idée est de maintenir le contexte sans conserver chaque détail précis, réduisant ainsi la charge mémoire. Cela ressemble beaucoup à la façon dont l'infini-attention, que nous avons abordée il y a quelques mois, gère les contextes volumineux tout en évitant intelligemment les problèmes de calcul et de mémoire de l’auto-attention classique.

Donc, MLA cible spécifiquement le goulet d'étranglement du cache KV en réduisant drastiquement sa taille. Pour cela, ça utilise une technique appelée compression de rang inférieur (low-rank compression), qui diminue la quantité de mémoire nécessaire pour stocker les paires KV sans perdre trop d'informations. Plutôt que de garder une mémoire haute résolution pour chaque Key et Value, MLA trouve une manière plus compacte de préserver les parties les plus importantes. C’est similaire à la compression d'image : une photo en haute qualité prend beaucoup d'espace, mais il est possible de la compresser en résolution inférieure tout en conservant la plupart des détails. Cependant, tout comme pour les images, il y a toujours un compromis : plus on compresse, plus on risque de perdre des détails. C’est une limitation cruciale à garder en tête.
Alors, où se situe FlashMLA dans tout cela ? FlashMLA est l’implémentation optimisée open-source de l'attention latente multi-têtes proposée par DeepSeek. FlashMLA repense les kernels exécutés sur les GPU Hopper de Nvidia afin que les calculs de l’attention latente multi-tête se fassent plus rapidement qu'avec une approche classique d'attention multi-têtes, tout en conservant la précision. Autrement dit, lorsque la consommation de mémoire diminue, les performances ne diminuent pas pour autant. Pensez-y comme une combinaison des gains d'efficacité que l'on peut voir avec les mixtures d’experts que nous avons vue (qui gère elle-même le calcul en orientant les tokens vers des sous-unités spécialisées) et la commodité du stockage de calculs partiels (comme dans la génération augmentée par cache, CAG), sauf que désormais, nous appliquons ce principe directement au mécanisme d'attention.
En compressant et en accélérant MLA grâce à FlashMLA, nous pouvons améliorer considérablement l'efficacité des ressources GPU. FlashMLA réduit ainsi sa taille d’information stockée à environ 6,7 % des méthodes traditionnelles. Cette optimisation aide aussi à atténuer le problème du « perdu au milieu » (« lost-in-the-middle ») en permettant de traiter des contextes plus longs sans saturer la mémoire. Cependant, bien que cette compression améliore la vitesse et l'efficacité, elle peut entraîner une perte de détails précis dans les tâches nécessitant une grande précision. De plus, FlashMLA est spécifiquement optimisé pour les GPU Hopper de NVIDIA (comme les H100 et H200) et ne prend actuellement en charge que les précisions BF16 et FP16, ce qui signifie que ses avantages ne s'appliqueront peut-être pas à du matériel plus ancien ou à des scénarios exigeant une précision numérique supérieure.
Si vous gérez des tâches comme des modèles de langage destinés à des applications nécessitant une attention spécialisée — par exemple une base de connaissances requérant des recherches quasi-instantanées ou un modèle exigeant des consultations rapides — FlashMLA pourrait changer la donne. Vous pouvez facilement l'intégrer à votre pipeline existant, et vous aurez alors l'impression d'avoir offert à votre GPU une mise à niveau majeure gratuitement.
À l'avenir, attendez-vous à ce que de plus en plus de grands modèles de langage adoptent ces formes spécialisées d'attention. Tout comme pour l'infini-attention, ces mécanismes spécialisés pourraient devenir la norme. FlashMLA réduit significativement votre emprepeinte mémoire tout en maintenant des performances rapides et fluides. Combiné à d'autres innovations telles que l'infini-attention ou la génération augmentée par cache (CAG), c’est précisément ce qui rend DeepSeek si rapide et puissant !
Voici donc pourquoi FlashMLA est l’une des raisons majeures qui expliquent pourquoi DeepSeek est si performant et en partie pourquoi ce modèle a été moins dispendieux a entraîner et à fournir aux utilisateurs. Si vous avez trouvé cette explication utile, partagez-la avec vos amis dans le domaine de l’IA, et restez connectés pour plus d'analyses sur les dernières avancées en recherche et technologies d'IA ! Merci d’avoir lu jusqu’à la fin, et je vous dis à la prochaine!