Entraîner des LLMs avec des Données Synthétiques (NVIDIA Nemotron)
Regardez la vidéo!
Vous êtes-vous déjà demandé pourquoi entraîner de grands modèles de langage est un défi aussi colossal ? Le secret réside dans l'énorme quantité de données de haute qualité dont ces modèles ont besoin. Mais obtenir ces données est incroyablement difficile. Bien que de nombreuses personnes aient essayé de résoudre ce problème de diverses manières, l'une des approches les plus prometteuses est l'utilisation de données synthétiques. C’est-à-dire des données entièrement générée artificiellement. Par exemple, en utilisant un autre modèle de language. C'est moins coûteux que d'autres méthodes, mais cela présente un inconvénient majeur : le manque de diversité. Récemment, les nouveaux LLM de Nvidia issus de leur famille de modèles Nemotron ont abordé cette question. Ils ont partagé une nouvelle méthode pour générer des données synthétiques utilisées pour l'entraînement et l'amélioration des grands modèles de langage (LLM).
Je suis Louis-François, co-fondateur de Towards AI, où on crée et partage du contenu éducatif comme notre récent livre ou des blogues gratuit comme celui-ci. Dans celui d'aujourd'hui, on va explorer ce qu’ Nvidia a faitpour entraîner un LLM en utilisant des données synthétiques et ce qu’ils ont découvert.
La première étape pour créer un ensemble de données synthétiques est de générer des prompts synthétiques, et pour cela, ils ont construit un générateur de modèles, pour travailler avec plusieurs modèles. On verra en quoi ça devient très intéressant dans quelques secondes…
Comme je l’ai dit, l'un des grands défis avec les données synthétiques est le manque de diversité des contenus générés par ces prompts. Pour surmonter cela, Nvidia a contrôlé la distribution des prompts pour couvrir un large éventail de scénarios grâce à quelques astuces.
La première chose qu'ils ont utilisée est une méthode appelée alignement itératif de faible à fort. Cela commence par un modèle initial puissant pour produire des données synthétiques, qui sont ensuite utilisées pour entraîner un nouveau modèle, qui devient ainsi meilleur ayant accès à plus de données. Ce serait comme utiliser GPT-3.5 pour entraîner GPT-4. Ce processus se répète en cycles : chaque modèle amélioré génère des données de meilleure qualité, ce qui permet d’entraîner un modèle encore meilleur. On passerait essentiellement de GPT 3.5 à 3.6, puis à 3.7, etc. Cette boucle continue de génération de données et d’entraînement de modèles aboutit à des modèles de plus en plus performants.

D'accord, on a trouvé une manière de créer de meilleurs modèles avec peu de travail manuel d'amélioration des données. C’est très cool. Mais comment ont-ils résolu notre problème de distribution des prompts ?
Eh bien, ils ont simplement utilisé plusieurs techniques d'ingénierie des prompts.
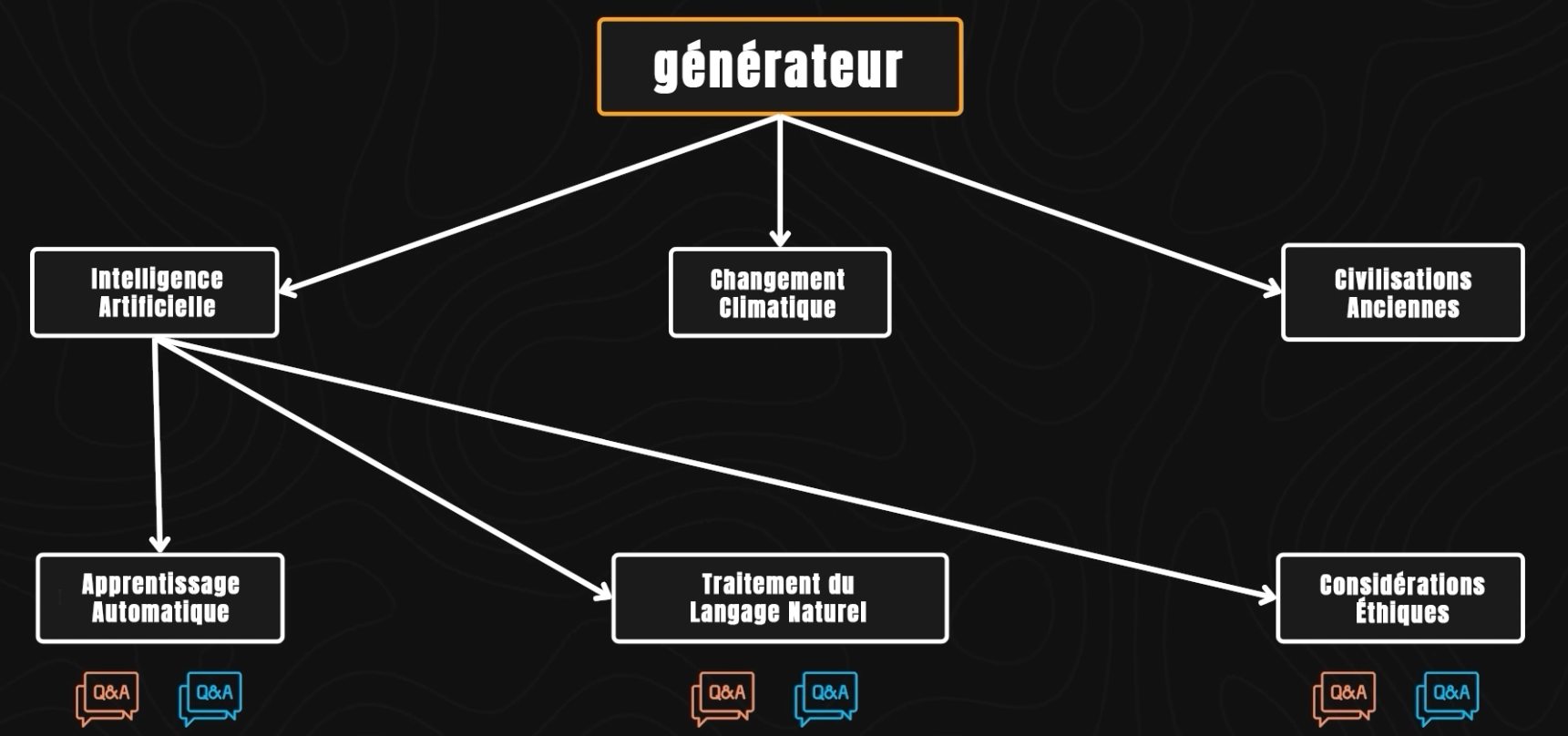
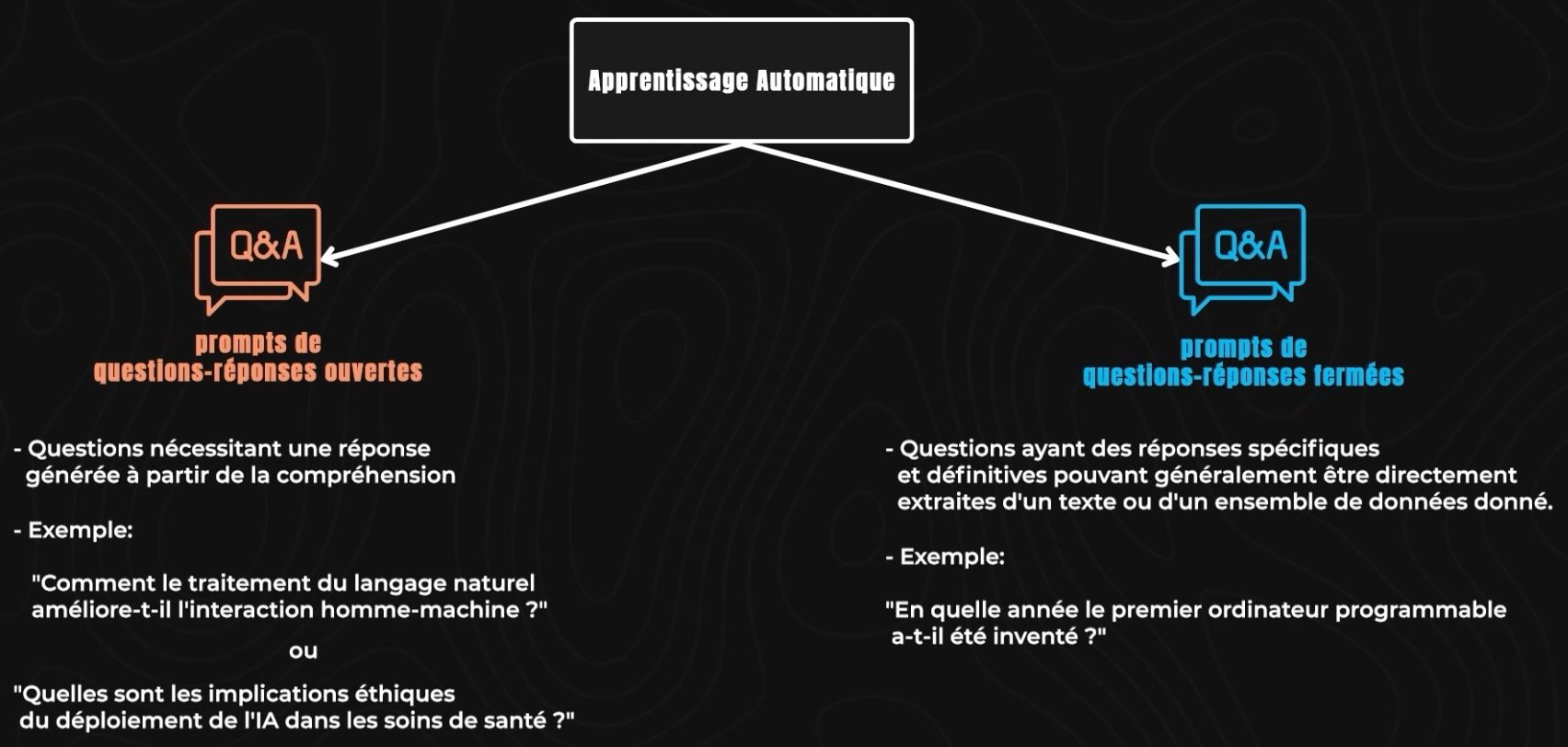
La première technique utilisée est celle des prompts à tour unique. Ici, un premier modèle, qu’on appelle un générateur, crée divers macro-sujets tels que "Intelligence Artificielle", "Changement Climatique" et "Civilisations Anciennes". Chaque macro-sujet est divisé en sous-sujets. Par exemple, sous "Intelligence Artificielle", les sous-sujets pourraient inclure "Apprentissage Automatique", "Traitement du Langage Naturel" et "Considérations Éthiques". Des questions sont ensuite créées pour chaque sous-sujet. Il existe deux types de questions : des prompts de questions-réponses ouvertes et des prompts de questions-réponses fermées. Les prompts de questions-réponses ouvertes impliquent des questions nécessitant une réponse générée à partir de la compréhension et de l'intégration d'informations provenant d'un large contexte ou de multiples sources, comme "Comment le traitement du langage naturel améliore-t-il l'interaction homme-machine ?" ou "Quelles sont les implications éthiques du déploiement de l'IA dans les soins de santé ?". Les prompts de questions-réponses fermées, en revanche, impliquent des questions ayant des réponses spécifiques et définitives pouvant généralement être directement extraites d'un texte ou d'un ensemble de données donné, comme "En quelle année le premier ordinateur programmable a-t-il été inventé ?" ou "Qu'est-ce que l'effet de serre ?".
Pour les prompts de questions-réponses ouvertes, les questions générées sont affinées pour les rendre plus spécifiques et détaillées. Par exemple, une question générale comme "Quelles sont les applications de l'apprentissage automatique ?" pourrait être affinée en "Comment l'apprentissage automatique est-il utilisé pour améliorer la précision des prévisions météorologiques ?"
Pour les prompts de questions-réponses fermées, ils ont utilisé le dataset C4, une collection de données web mise à jour en continu. Chaque document de ce dataset est intégré au générateur, qui produit une instruction spécifique à ce document. Le document est ensuite concaténé avec les instructions en utilisant des modèles manuels spécifiques. Par exemple, pour un document sur l'apprentissage automatique, l'instruction pourrait être, "Résumez l'apprentissage supervisé et décrivez comment les arbres de décision sont utilisés dans le monde réel."
En dehors des prompts à tour unique, le modèle a besoin de données sur la façon de suivre des instructions spécifiques et de répondre de manière à satisfaire les exigences de l'utilisateur. Cela nous amène aux deux types importants de prompts suivants : les prompts de suivi d'instructions et les données de préférence. Examinons-les un par un pour expliquer pourquoi ils sont utiles pour la diversité des données d'entraînement.
Qu'est-ce que le suivi d'instructions ? C'est lorsque le modèle comprend et exécute les instructions spécifiques données par un utilisateur, assurant ainsi que le modèle s'aligne sur les attentes de l'utilisateur. Dans le cas de Nemetron, son propre générateur, ou le meilleur modèle actuel, crée ces prompts de suivi d'instructions, chacun étant associé à un prompt général. Par exemple, si le prompt général est "Écrire un essai sur l'apprentissage automatique", le prompt d'instruction pourrait être "Votre réponse doit comporter trois paragraphes", en supposant que la réponse dans notre ensemble de données comporte trois paragraphes, évidemment. On va donc simplement inventer des instructions qui décrivent les données qu’on a, ce qui devrait enseigner au modèle comment suivre ce genre d’instructions. Cette association aide le modèle à fournir des réponses qui répondent automatiquement aux exigences spécifiques de l'utilisateur. C’est aussi comme ça que ChatGPT est si bon pour répondre à ce que vous demandez!
Ici, une variation intéressante est les instructions à tours multiples, où l'instruction s'applique à toutes les conversations futures, ce qu’on fait constamment avec ChatGPT. Par exemple, si l'instruction à tours multiples est "Répondez à toutes les questions avec des explications détaillées et des exemples", et que l'utilisateur demande d'abord, "Quelle est l'importance du test de Turing ?", le modèle fournirait une explication détaillée, incluant des exemples. Si la question suivante est "Comment le test de Turing s'applique-t-il à l'IA moderne ?", le modèle continuerait à suivre les instructions et fournirait une réponse tout aussi détaillée avec des exemples. Et donc, dans ce cas, le modèle maintient le même style d'explication.
Passons maintenant à la troisième technique, les données de préférence. Les données de préférence impliquent de créer synthétiquement des prompts à deux tours pour aider le modèle à apprendre et à s'adapter plus efficacement aux préférences des utilisateurs. Par exemple, on utilise un prompt utilisateur provenant de ShareGPT, une plateforme où les utilisateurs partagent leurs interactions avec les modèles d'IA. Supposons que le prompt utilisateur de ShareGPT soit : "Quelle est la signification de la vie ? Expliquez-le en 5 paragraphes." Le modèle génère alors la réponse de l'assistant : "La signification de la vie est une question philosophique qui a été débattue tout au long de l'histoire. C'est un sujet complexe et multiforme, et différentes personnes peuvent avoir des réponses différentes." Sur la base de cette réponse, une autre réplique est générée et étiquetée comme la réponse de l'utilisateur, telle que "La réponse ne devrait-elle pas être 42 ?" Ce cycle aide le modèle à apprendre à anticiper et à répondre aux préférences des utilisateurs. Même si cette réponse pourrait ne pas être très exact, elle ajoute certainement de la vie et même un potentiel de meme au LLM.
Pour garantir que les réponses diffèrent les unes des autres et maintiennent un dialogue réaliste, le modèle reçoit des descriptions de rôles claires sur la manière de fournir des réponses lorsqu'il répond en tant qu'assistant ou utilisateur. Par exemple, en tant qu'assistant, le modèle pourrait recevoir l'instruction de fournir des réponses détaillées et informatives, tandis qu'en tant qu'utilisateur, il pourrait poser des questions de suivi visant à obtenir des clarifications supplémentaires ou des informations additionnelles.
On a discuté des conversations à un tour et à deux tours avec le modèle, mais dans la vie réelle, nos conversations avec le modèle sont souvent des allers-retours multiples. Pour gérer ces interactions plus longues, on utilise une méthode appelée génération de dialogues synthétiques à tours multiples. Ici, on assigne au modèle deux rôles : l'un en tant qu'assistant et l'autre en tant qu'utilisateur. Le modèle reçoit des instructions spécifiques pour chaque rôle et commence avec un prompt initial, tel qu'une question ou une déclaration. Il alterne ensuite entre ces rôles, créant des réponses en aller-retour, simulant une conversation réelle. Ce processus aide le modèle à apprendre à gérer des dialogues prolongés en pratiquant les deux côtés de l'interaction. Cependant, cette approche est risquée, car le modèle peut entrer dans des boucles répétitives et revenir à notre problème initial de diversité des données.
Avec toutes ces techniques de création de prompts, l'étape suivante consiste à s'assurer que le modèle donne la réponse correcte de la manière souhaitée par l'utilisateur et reste diversifié. Cela s'appelle le peaufinage, ou fine-tuning en anglais, des préférences et repose sur la justesse de la réponse. Pour générer cela, on a besoin d'un prompt et de sa réponse correcte et une autre réponse incorrecte associée. Par exemple, si le prompt est "Expliquez le processus de la photosynthèse", une réponse correcte décrirait précisément les étapes de la photosynthèse, tandis qu'une réponse incorrecte fournirait des informations sans rapport ou incorrectes.
Comme on en a parlé, au cours de l’entraînement des modèles de Nvidia, différents prompts ont été donnés à plusieurs modèles intermédiaires qui génèrent des réponses pour entraîner le modèle suivant. Ce qui a une seconde utilité intéressante. L'utilisation de plusieurs modèles crée un ensemble de données synthétiques plus complexe. Cela aide à assurer la diversité des données, car chaque modèle peut générer des réponses légèrement différentes au même prompt, reflétant une gamme plus large de perspectives et de styles. On peut utiliser des données déjà annotées, ou bien un modèle pour déterminer si les réponses sont correctes. Les annotations des données peuvent être basées sur les annotations d'ensemble de données existantes ou validée à l'aide d'outils pour les tâches en Python ou en mathématiques. Par exemple, pour un prompt lié à la résolution d'un problème mathématique, une annotation serait la réponse correcte calculée par un vérificateur. On pourrait ensuite utiliser un LLM ou un modèle de récompense comme juge pour l'évaluation du modèle. Par exemple, si on utilise un LLM, on génère des réponses de deux modèles intermédiaires différents et on les compare. Pour éviter le biais de position dans les réponses des deux modèles, on échange leurs positions et compare les réponses à nouveau. Nvidia ont observés que les modèles de récompense performent mieux que les LLM en tant que juges en différenciant plus précisément les réponses.
Par exemple, le modèle de récompense utilisé ici, Nemotron-4, montre une précision plus élevée dans l'évaluation des réponses dans des scénarios complexes, tels que la distinction entre des réponses nuancées et des réponses simples à des questions techniques. Cette approche non seulement assure la justesse des réponses, mais maintient également un ensemble de données d'entraînement diversifié et de haute qualité, enrichissant la capacité du modèle à gérer une variété de requêtes et d'instructions.

Dans ce pipeline de génération de données synthétiques, (1) le modèle Nemotron-4 340B Instruct est d'abord utilisé pour produire une sortie textuelle synthétique. Un modèle d'évaluateur, (2) Nemotron-4 340B Reward, évalue ensuite ce texte généré — , fournissant des commentaires qui guident les améliorations itératives et garantissent que les données synthétiques sont exactes, pertinentes et alignées sur des exigences spécifiques. Image et légende du billet de blog de NVIDIA.
En résumé, on peut voir à quel point les techniques de création de prompts plus avancées sont importantes, surtout lorsqu'on construit des systèmes de plus en plus intégrés et interconnectés dépendant de LLM autonomes travaillant ensemble.
L'entraînement avec des données synthétiques offre une approche prometteuse pour développer des modèles qui ne sont pas contraints par les biais de données, les problèmes de qualité ou les coûts élevés. J'espère que cet aperçu de la génération de données pour des domaines personnalisés et de la façon dont Nvidia l'a fait avec leur famille de modèles Nemotron vous a été utile.
Merci d'avoir lu l’article, et à la prochaine !