Essayez différentes coiffures et couleurs de cheveux à partir d'images!
Cet article ne concerne pas une nouvelle technologie en soi. Il s'agit plutôt d'une nouvelle et fascinante application des GANs. En effet, vous avez vu le titre, et ce n'était pas un “clickbait”. Cette IA peut transférer vos cheveux pour voir à quoi ils ressembleraient avant de s'engager dans un gros changement. Nous savons tous qu'il peut être difficile de changer de coiffure même si vous le souhaitez. Bon, du moins pour moi, je suis habituée à la même coupe de cheveux depuis des années, en disant à mon coiffeur "comme la dernière fois" tous les 3 ou 4 mois même si, au fond, j'aimerais bien un changement. Je ne peux tout simplement pas plonger, peur que ça ait l'air bizarre et inhabituel. Bien sûr, tout cela est dans notre tête, car nous sommes les seuls à nous soucier de notre coupe de cheveux, mais cet outil pourrait changer la donne pour certains d'entre nous, nous aidant à décider de s'engager ou non dans un tel changement en ayant de bonnes idées sur la façon dont on aura l’air.
Ces moments où l'on peut voir dans le futur sont rares. Même si ce n'est pas tout à fait exact, c'est quand même plutôt cool d'avoir une approximation si excellente de ce à quoi pourrait ressembler une nouvelle coupe de cheveux, nous soulageant d'une partie du stress d'essayer quelque chose de nouveau tout en gardant la partie excitante. Bien sûr, les coupes de cheveux sont très superficielles par rapport à des applications plus utiles. Néanmoins, c'est un pas en avant vers le fait de « voir dans le futur » en utilisant l'IA, ce qui est plutôt cool. En effet, cette nouvelle technique nous permet en quelque sorte de prédire l'avenir, même s'il ne s'agit que de l'avenir de nos cheveux. Mais avant de plonger dans son fonctionnement, je suis curieux de savoir ce que vous pensez de cela. Dans tout autre domaine :
Quelle(s) autre(s) application(s) aimeriez-vous voir utiliser l'IA pour « voir dans le futur » ?

Exemples de translations. Peihao Zhu et al., (2021)
Cela peut changer non seulement le style de vos cheveux, mais aussi la couleur. Tout ça à partir d’une ou plusieurs images. Vous pouvez fondamentalement donner trois choses à l'algorithme :
une photo de vous
une photo de quelqu'un avec la coiffure que vous aimeriez avoir et
une autre photo (ou la même) de la couleur de cheveux que vous aimeriez essayer
et il fusionne tout sur vous-même de manière réaliste.
Les résultats sont vraiment impressionnants. Si vous ne faites pas confiance à mon jugement, comme je le comprendrais parfaitement si je me base sur mes compétences artistiques, ils ont également mené une étude subjective sur 396 participants. Leur solution a été préférée 95% du temps! Bien sûr, vous pouvez trouver plus de détails sur cette étude dans les références ci-dessous si cela semble difficile à croire.
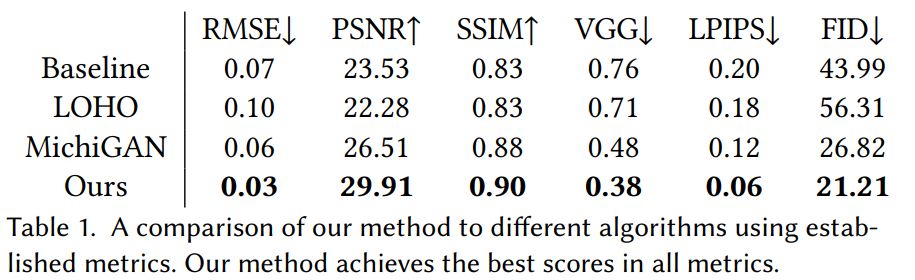
Résultats quantitatifs de la méthode. Peihao Zhu et al., (2021)
Comme vous pouvez vous en douter, nous jouons avec les visages ici, il utilise donc un processus très similaire à celui des articles précédents que j'ai couverts, en changeant le visage en dessins animés ou d'autres styles qui utilisent tous des GANs. Puisqu'elle est extrêmement similaire, je vous laisse regarder mes autres vidéos ou les articles où j'ai expliqué comment les GANs fonctionnent en détail, et je me concentrerai sur les nouveautés de cette méthode ici et pourquoi elle fonctionne si bien.
Une architecture GAN peut apprendre à transposer des caractéristiques ou des styles spécifiques d'une image sur une autre. Le problème est que les résultats semblent souvent irréalistes à cause des différences d'éclairage, d’occlusions qu’il peut y avoir dans les images, ou même simplement de la position de la tête qui sont différentes dans les deux images. Tous ces petits détails rendent ce problème très difficile, provoquant des artéfacts dans l'image générée. Voici un exemple simple pour mieux visualiser ce problème, si vous prenez les cheveux de quelqu'un sur une photo prise dans une pièce sombre et essayez de les mettre sur vous dehors à la lumière du jour, même s'ils sont parfaitement transposés sur votre tête, ça aura quand même l'air étrange dû à la différence de luminosité. En règle générale, ces autres techniques utilisant des GANs tentent d’encoder les informations des images et d'identifier explicitement la région associée aux attributs de cheveux dans cet encodage pour les interchanger. Cela fonctionne bien lorsque les deux photos sont prises dans des conditions similaires, mais ça n'aura pas l'air réel la plupart du temps pour les raisons que je viens de mentionner. Ensuite, ils doivent utiliser un autre réseau pour réparer le ré-allumage, les trous et autres artefacts étranges causés par la fusion. Le but ici était donc de transposer la coiffure et la couleur de cheveux d'une image spécifique sur votre propre image tout en modifiant les résultats pour suivre l'éclairage et les propriétés de votre image pour la rendre convaincante et réaliste tout en même temps, en réduisant les étapes et les sources d'erreurs.
Si ce dernier paragraphe n'était pas clair, je vous recommande fortement de regarder la vidéo à la fin de cet article, car il y a plus d'exemples visuels pour aider à comprendre.
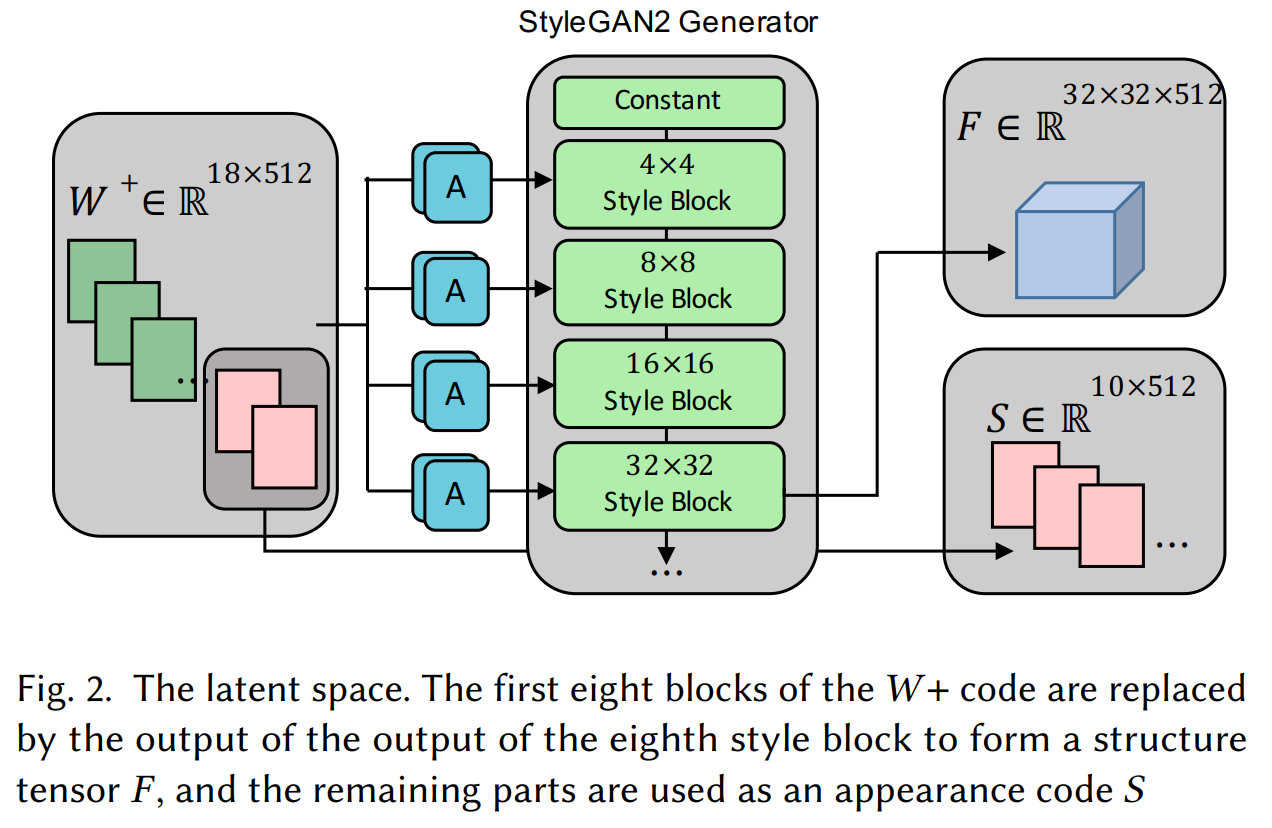
Réseau de base StyleGAN2 et où ils tirent les informations. Peihao Zhu et al., (2021)
Pour y parvenir, Peihao Zhu et al. ont ajouté une étape d'alignement manquante, mais essentielle aux GANs. En effet, au lieu de simplement encoder les images et ensuite les fusionner, ils modifient légèrement l'encodage suivant un masque de segmentation différent pour rendre le code latent des deux images plus similaire. Comme je l'ai mentionné, ils peuvent à la fois modifier la structure et le style ou l'apparence des cheveux.

Le code latent relié à l’apparence. Peihao Zhu et al., (2021)
Ici, la structure est bien sûr la géométrie du cheveu, qui nous dit s'il est bouclé, ondulé ou raide. Si vous avez vu mes autres vidéos, vous savez déjà que les GANs encodent les informations à l'aide de convolutions. Cela signifie que ça utilise des noyaux pour réduire l'échelle des informations à chaque couche et les rend de plus en plus petites, supprimant ainsi de manière itérative les détails spatiaux tout en donnant de plus en plus de valeur aux informations générales pour la sortie résultante. Ces informations structurelles sont obtenues, comme toujours, à partir des premières couches du GAN, donc avant que l’encodage ne devienne trop général et donc “trop encodé” pour représenter des caractéristiques spatiales.
L'apparence fait référence aux informations profondément encodées. Elle comprend la couleur des cheveux, la texture et l'éclairage. Vous savez d'où proviennent les informations des différentes images, mais maintenant, comment fusionnent-ils ces informations et les rendent-elles plus réalistes que les approches précédentes ?

Images de références et image “target”. Peihao Zhu et al., (2021)
Comme j’ai déjà mentionné, cela se fait en utilisant des cartes de segmentations à partir des images d’entrées. Et plus précisément, générer cette nouvelle image souhaitée basée sur une version alignée de notre image cible et de référence. L'image de référence est notre propre image, et l'image cible la coiffure que nous voulons appliquer. Ces cartes de segmentation nous disent ce que contient l'image et où elle se trouve, cheveux, peau, yeux, nez, etc.
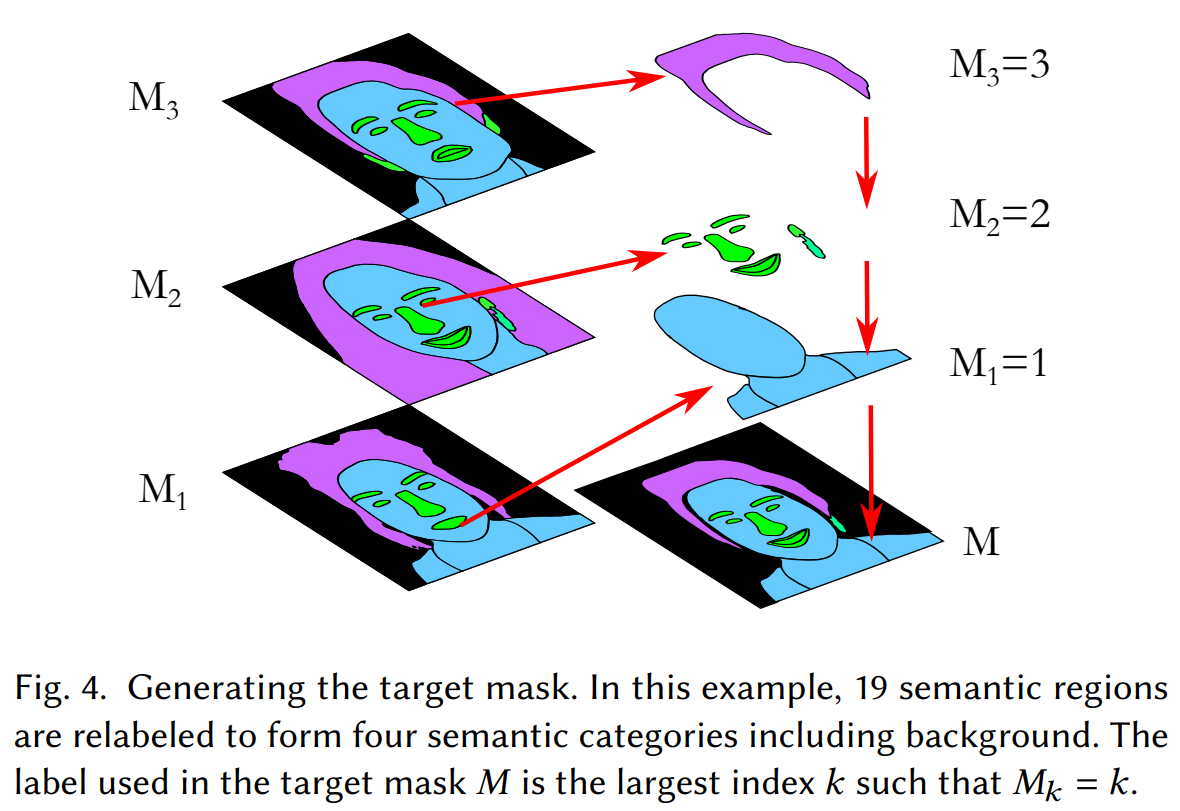
Les masques de segmentations. Peihao Zhu et al., (2021)
À l'aide de ces informations provenant des différentes images, ils peuvent aligner les têtes en suivant la structure de l'image cible avant d'envoyer les images au réseau pour encodage à l'aide d'une architecture modifiée basée sur StyleGAN2. Une architecture que j'ai déjà couvert à plusieurs reprises. Cet alignement rend les informations encodées beaucoup plus facilement comparables et reconstructibles.
Ensuite, pour le problème d'apparence et d'éclairage, ils trouvent un rapport de mélange approprié de ces encodages d'apparences à partir des images cibles et de référence pour les mêmes régions segmentées, le rendant aussi réel que possible. Voici à quoi ressemblent les résultats sans l'alignement sur la colonne de gauche et leur approche sur la droite.

Comparaison des techniques traditionnelles (gauche) et celle-ci (droite). Peihao Zhu et al., (2021)
Bien sûr, ce processus est un peu plus compliqué, et tous les détails peuvent être trouvés dans l'article dans les références. Notez que, tout comme la plupart des implémentations de GANs, leur architecture devait être entraînée. Ici, ils ont utilisé un réseau basé sur StyleGAN2 entraîné sur l'ensemble de données FFHQ (photos de visages prises sur Flickr). Puis, comme ils ont apporté de nombreuses modifications, comme nous venons de le voir, ils ont entraîné une deuxième fois leur réseau StleGAN2 modifié en utilisant 198 paires d'images comme exemples de transfert de coiffure pour optimiser la décision du modèle à la fois pour le rapport de mélange d'apparences et les encodages structurels.
De plus, comme vous pouvez vous y attendre, il existe encore des imperfections comme celles-ci où leur approche ne parvient pas à aligner les masques de segmentation ou à reconstruire le visage.
Pourtant, les résultats sont extrêmement impressionnants et c'est formidable qu'ils partagent ouvertement les limites.

Les limitations. Peihao Zhu et al., (2021)
Comme ils l'indiquent dans l'article, le code source de leur méthode sera rendu public après une éventuelle publication de l'article. Le lien vers le répertoire officiel de GitHub se trouve dans les références ci-dessous, en espérant qu'il sera bientôt publié.
Merci d’avoir lu cet article!
Regardez la vidéo sous-titrée en Français:
Venez discuter avec nous dans notre communauté Discord: ‘Learn AI Together’ et partagez vos projets, vos articles, vos meilleurs cours, trouvez des coéquipiers pour des compétitions Kaggle et plus encore!
Si vous aimez mon travail et que vous souhaitez rester à jour avec l'IA, vous devez absolument me suivre sur mes autres médias sociaux (LinkedIn, Twitter) et vous abonner à ma newsletter hebdomadaire sur l'IA!
Pour supporter mon travail:
La meilleure façon de me soutenir est de souscrire à ma newsletter tel que mentionné précédemment ou de vous abonner à ma chaîne sur YouTube si vous aimez le format vidéo en anglais.
Soutenez mon travail financièrement sur Patreon
Références
Peihao Zhu et al., (2021), Barbershop, https://arxiv.org/pdf/2106.01505.pdf
Project link: https://zpdesu.github.io/Barbershop/