Agents ou Workflows ? La Révolution Cachée de l’IA
Regardez la vidéo!
Ce que la plupart des gens appellent des agents n’en sont pas. Je n’ai jamais vraiment aimé le terme "agent", jusqu’à ce que je tombe sur cet article récent d’Anthropic, où je suis totalement d’accord et j’aimerais donc partager ce qu’est réellement un agent. La grande majorité des “agents” d’aujourd’hui, c’est simplement un appel API à un modèle de langage. C’est ça. Quelques lignes de code et un prompt.

Ceci ne peut pas agir de manière indépendante, prendre des décisions ou faire quoi que ce soit de réellement intelligent. Cela répond simplement à vos utilisateurs. Pourtant, nous appelons cela des agents. Mais ce n’est pas ce dont nous avons en tête. Ce que nous pensons, et aimerions avoir, sont de vrais agents, mais qu’est-ce qu’un vrai agent ?
Reprenons donc depuis le début. Nous avons un LLM accessible de manière programmatique, soit via une API, soit localement sur votre propre serveur ou machine, et ensuite ? Eh bien, nous avons besoin qu’il prenne des mesures ou qu’il fasse un peu plus que simplement générer du texte. Comment ? En lui donnant accès à des outils et leur documentation. On leur donne accès à un outil comme la capacité d’exécuter des requêtes SQL dans une base de données pour accéder à des connaissances privées. Concrètement, nous codons tout cela nous-mêmes pour que le LLM génère des requêtes SQL, et ensuite notre code envoie et exécute automatiquement la requête dans notre base de données. Nous renvoyons ensuite les résultats pour qu’ils soient utilisés pour répondre à l’utilisateur.
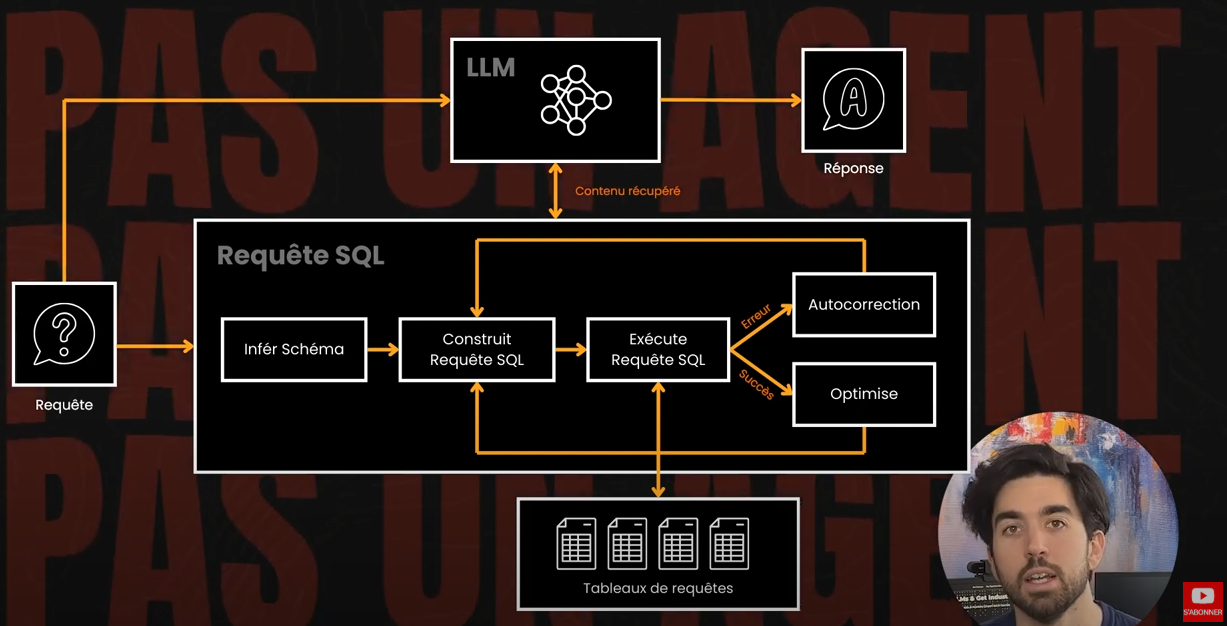
C’est ce qu’une grande proportion de personnes appelle encore des agents. Ce ne sont toujours pas des agents. C’est simplement un processus, codé en dur ou avec de petites variations comme des routeurs que nous discutons dans notre cours. Bien sûr, c’est utile et c’est super puissant. Pourtant, ce n’est pas un être intelligent ou quelque chose d’indépendant. Ce n’est pas un "agent" agissant en notre nom. C’est simplement un programme que nous avons créé et contrôlons. Ou, comme Anthropic l’a appelé, un workflow.
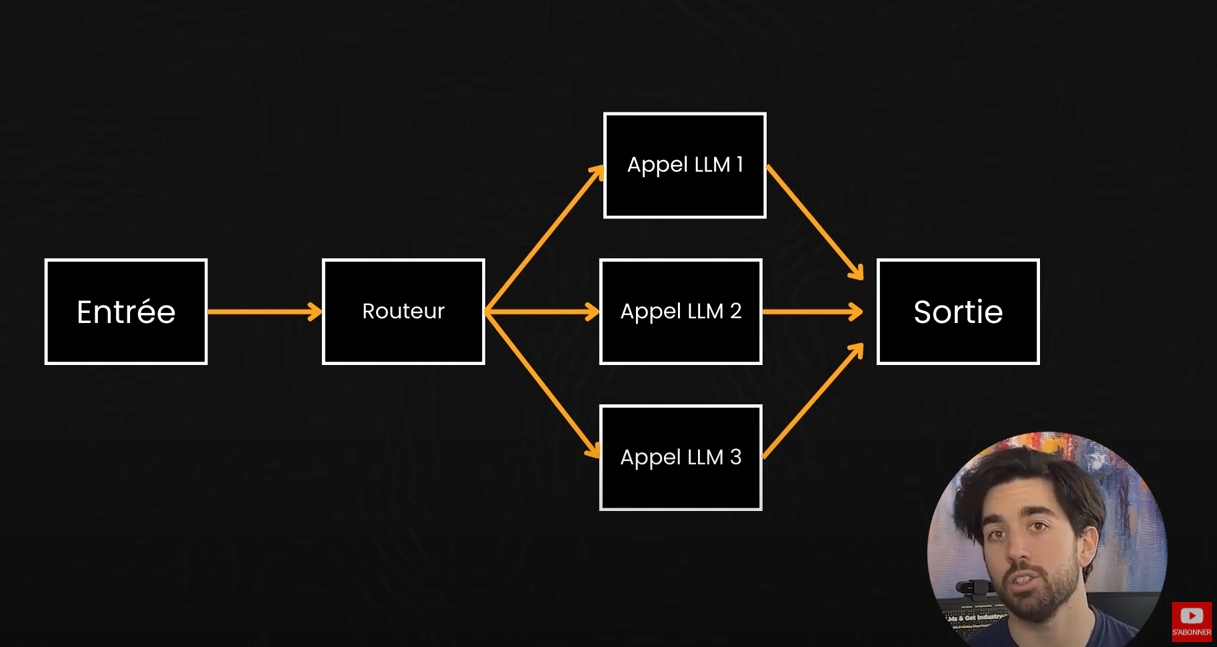
Ne vous méprenez pas. Les workflows sont extrêmement utile. Et ils peuvent devenir assez complexe et avancé. Nous pouvons mettre en œuvre des routeurs intelligents pour décider quel outil utiliser et quand accéder à diverses bases de données, décider lequel interroger et quand, exécuter des tâches via des outils d’action à travers du code, et bien plus encore. De plus, vous pouvez avoir autant de workflows que vous le souhaitez. Je veux simplement souligner à quel point c’est différent d’un véritable agent. Le type d’agent dont nous rêvons, et dont Ilya a parlé dans une récente conférence à NeurIPS…
La prochaine question qu’on se pose serait : et donc, qu’est-ce qu’un "vrai agent" ? En termes simples, un vrai agent est quelque chose qui fonctionne de manière indépendante. Plus précisément, c’est quelque chose capable d’employer des processus similaires à notre Système 2 — quelque chose capable de vraiment raisonner, réfléchir, et reconnaître quand il manque de connaissances. C’est presque le contraire de notre Système 1, qui est rapide, automatique, et basée uniquement sur des schémas et des réponses apprises, comme des réflexes quand vous devez attraper un verre qui tombe. En revanche, le Système 2 pourrait impliquer de décider si et comment l’on doit empêcher le verre de tomber en premier lieu, peut-être en utilisant un outil à proximité comme un plateau ou en déplaçant un objet fragile hors du chemin. Un vrai agent, donc, ne saurait pas seulement utiliser des outils, mais déciderait aussi quand et pourquoi les utiliser, basé sur un raisonnement délibéré.
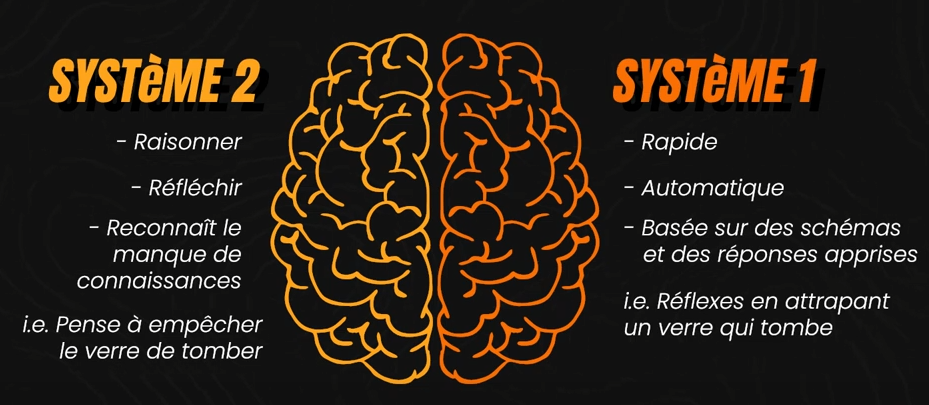
Les nouvelles séries o1 et o3 d’OpenAI illustrent ce changement, car elles commencent à explorer des approches similaires au Système 2 et essaient de faire “raisonner” les modèles en discutant d’abord avec eux-mêmes, imitant une approche humaine du raisonnement avant de parler. Contrairement aux modèles de langage traditionnels qui reposent sur la prédiction du mot suivant (ou du token suivant) — essentiellement un mécanisme de pensée instantanée du Système 1, basé uniquement sur ce qu’il sait et a appris pour deviner la prochaine chose à faire sans plan — ces nouveaux modèles visent à incorporer des capacités de raisonnement plus profondes, marquant un pas vers la réflexion délibérée associée au Système 2.
Mais nous nous écartons un peu trop avec cette parenthèse de Kahneman. Permettez-moi de clarifier ce que je veux dire par un vrai agent en détaillant un peu mieux ce qu’est un workflow…
Les workflows suivent des lignes de code spécifiques avec des intégrations et, mis à part les sorties du LLM, ils sont assez prévisibles. Ils sont responsables de la plupart des applications avancées que vous voyez et utilisez aujourd’hui, et ce pour une raison. Ils sont cohérents, plus prévisibles, et incroyablement puissants lorsqu’ils sont bien exploités. Comme l’a écrit Anthropic : "Les workflows sont des systèmes où les LLMs et les outils sont orchestrés via des chemins de code prédéfinis."
Voici à quoi ressemble un workflow: Nous avons notre LLM, quelques outils ou une mémoire pour récupérer du contexte supplémentaire, itérer un peu avec plusieurs appels au LLM, puis un résultat renvoyé à l’utilisateur. Comme nous l’avons discuté, lorsqu’un système doit parfois effectuer une tâche et parfois une autre, selon les conditions, il utilise un routeur avec diverses conditions pour sélectionner le bon outil ou le bon prompt à utiliser. Ça reste un workflow. C’est simplement plus complèxe. Ils peuvent même fonctionner en parallèle pour être plus efficaces. Mieux encore, nous pouvons avoir une sorte de modèle principal, que nous appelons orchestrateur, qui sélectionne tous les différents sous modèles à appeler pour des tâches spécifiques et synthétise les résultats, comme notre exemple SQL où nous aurions un orchestrateur principal obtenant la requête utilisateur, et pourrait décider s’il a besoin d’interroger le jeu de données ou non, et si c’est le cas, demanderait à l’agent SQL de générer la requête SQL, interrogerait la base de données, obtiendrait les résultats et synthétiserait la réponse finale grâce à toutes les informations fournies.
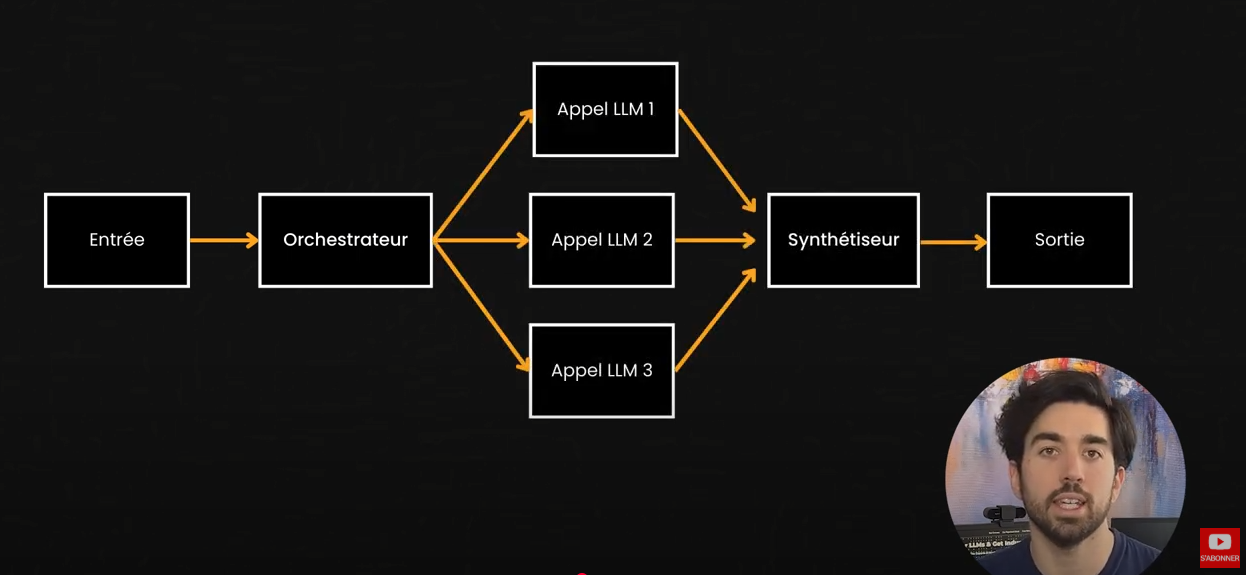
C’est très similaire à l’interface ChatGPT, qui exploite parfois Canvas ou un interpréteur de code pour mieux répondre à vos besoins. Même si complexe et avancé, tout est encore codé en dur. Si vous savez ce que vous voulez que votre système fasse, vous avez besoin d’un workflow, peu importe à quel point il est avancé, pas un agent.
Par exemple, ce que CrewAI appel des agents fonctionnent comme des workflows prédéfinis affectés à des tâches spécifiques, tandis qu’Anthropic imagine un agent comme étant un système unique capable de raisonner sur n’importe quelle tâche de manière indépendante. Les deux approches ont leurs mérites : l’une est prévisible et intuitive, tandis que l’autre vise la flexibilité et l’adaptabilité. Cependant, cette dernière est beaucoup plus difficile à réaliser avec les modèles actuels et correspond mieux à ma définition d’un agent.
Donc, à propos de ces “vrais” agents…
Les agents "sont des systèmes où les LLMs dirigent eux-mêmes dynamiquement leurs propres processus et l’utilisation des outils, en gardant le contrôle sur la manière dont ils accomplissent les tâches." C’est ce qu’Anthropic a écrit, et ça me semble tout à fait raisonnable. Les vrais agents élaborent un plan en échangeant avec vous et en comprenant vos besoins, en itérant à un niveau de “raisonnement” pour décider des étapes à suivre pour résoudre le problème ou répondre à la requête. Idéalement, ils vous demanderont même si des informations supplémentaires ou des clarifications sont nécessaires, au lieu de divaguer et halluciner, comme le font les LLMs actuels.
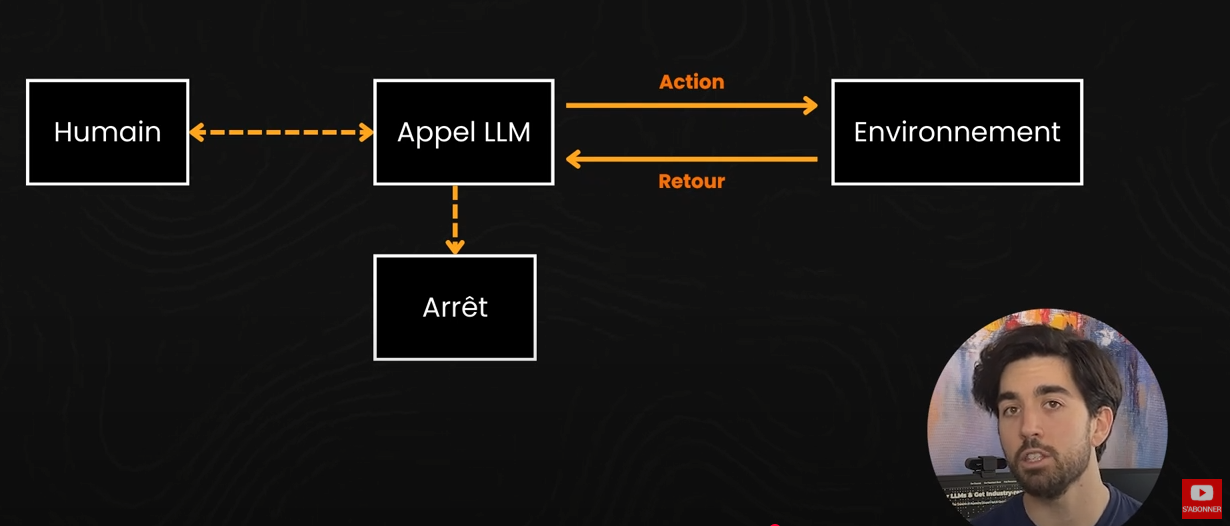
Malheureusement, ils ne sont pas si simples à construire. Ils nécessitent un LLM très puissant, meilleur que ceux que nous avons actuellement, et un environnement dans lequel évoluer, comme une discussion avec vous et des capacités supplémentaires comme des outils qu’ils peuvent utiliser eux-mêmes lorsqu’ils le jugent nécessaire. Le tout, en itérant avgec lui-même. En bref, vous pouvez presque voir les agents comme remplaçant une personne ou un rôle, alors qu’un workflow remplace une tâche que l’on effectuerait. Il n’y a pas de chemin codé en dur. Le système agentique prendra ses décisions. Ce sont des systèmes bien plus avancées et complexes que nous n’avons pas encore réussi à construire avec succès.
Cette indépendance et la confiance dans votre système le rendent évidemment plus susceptible aux échecs, plus coûteux à exécuter et utiliser, augmentent la latence et, pire encore, les résultats ne sont pas si excitants jusqu’à maintenant. Et quand ils le sont, ils ne sont pas du tout constant.
Alors, quel est un bon exemple concret d’agent ? Deux exemples me viennent rapidement à l’esprit : Devin et l’utilisation de l’ordinateur par Anthropic. Pourtant, pour l’instant, ce sont des agents plutôt décevants.
Si vous êtes curieux à propos de Devin, il y a un excellent blog de Hamel Husain partageant son expérience en l’utilisant. Devin offre un aperçu fascinant des promesses et des défis des systèmes basés sur des agents. Il est conçu comme un ingénieur logiciel entièrement autonome avec son propre environnement informatique, gérant de manière indépendante des tâches telles que les intégrations API et la résolution de problèmes en temps réel. Malheureusement, comme les tests approfondis de Hamel l’ont démontré, bien que Devin excelle dans les tâches simples et bien définies (celles que nous pouvons faire facilement), il a du mal avec les tâches complexes ou ambiguës, proposant souvent des solutions trop compliquées ou poursuivant des chemins irréalisables, tandis que des workflows avancés comme Cursor n’ont pas autant de problèmes. Ces limitations montrent bien les défis plus larges de la création d’agents fiables et contextuellement conscients avec les LLMs actuels, même si vous investissez des millions et des millions.
Ici, Devin s’aligne davantage sur la vision d’Anthropic, montrant les promesses et les défis d’un agent capable de raisonner. Il peut s’attaquer de manière autonome à des problèmes complexes, mais il lutte avec l’incohérence. En revanche, les workflows comme ceux inspirés par CrewAI sont plus simples et plus robustes pour des tâches spécifiques, mais manquent de la flexibilité des systèmes de raisonnement véritables.
De même, il y a l’ambitieux essai d’Anthropic de créer un agent autonome ayant accès à notre ordinateur, qui a suscité beaucoup d’engouement à sa sortie, mais a depuis été largement oublié. Le système est indéniablement complexe et incarne les caractéristiques d’un véritable agent : prise de décision autonome, utilisation dynamique des outils, et capacité à interagir avec son environnement. Son objectif est également de remplacer toute personne sur un ordinateur, ce qui est assez prometteur (ou effrayant) ! Malgré tout, son déclin depuis sa sortie sert également de rappel des défis à créer des systèmes agentiques pratiques qui fonctionnent comme prévu, et le font de manière systématique.
En résumé, les LLMs ne sont tout simplement pas encore prêts pour devenir de vrais agents. Mais cela pourrait être le cas bientôt.
Pour l’instant, comme pour tout ce qui est lié au code, nous devrions toujours viser à trouver une solution à notre problème qui soit aussi simple que possible. Une solution que nous pouvons facilement itérer et déboguer. Les simples appels à des LLM sont souvent la meilleure voie. Et c’est souvent ce que les gens et les entreprises vendent comme étant un “agent”, mais vous ne vous laisserez plus avoir. Vous pouvez vouloir compléter les LLM avec des connaissances externes via l’utilisation de systèmes de récupération ou un léger réentraînement (ou affinage), mais votre argent et votre temps visant de vrais agents devraient être réservés aux problèmes vraiment complexes que nous ne pouvons pas résoudre autrement.
J'espère que ce blogue vous a aidé à comprendre la différence entre un workflow et un vrai agent, et quand utiliser les deux. Si vous l'avez trouvée utile, partagez-la avec vos amis de la communauté IA et n'oubliez pas de vous abonner pour plus de contenu approfondi sur l'IA !
Merci d'avoir lu !
Références :
Blogue d’Anthropic sur les agents :https://www.anthropic.com/research/building-effective-agents
Utilisation de l’ordinateur par Anthropic :https://www.anthropic.com/news/3-5-models-and-computer-use
Blogue de Hamel Husain sur Devin :https://www.answer.ai/posts/2025-01-08-devin.html